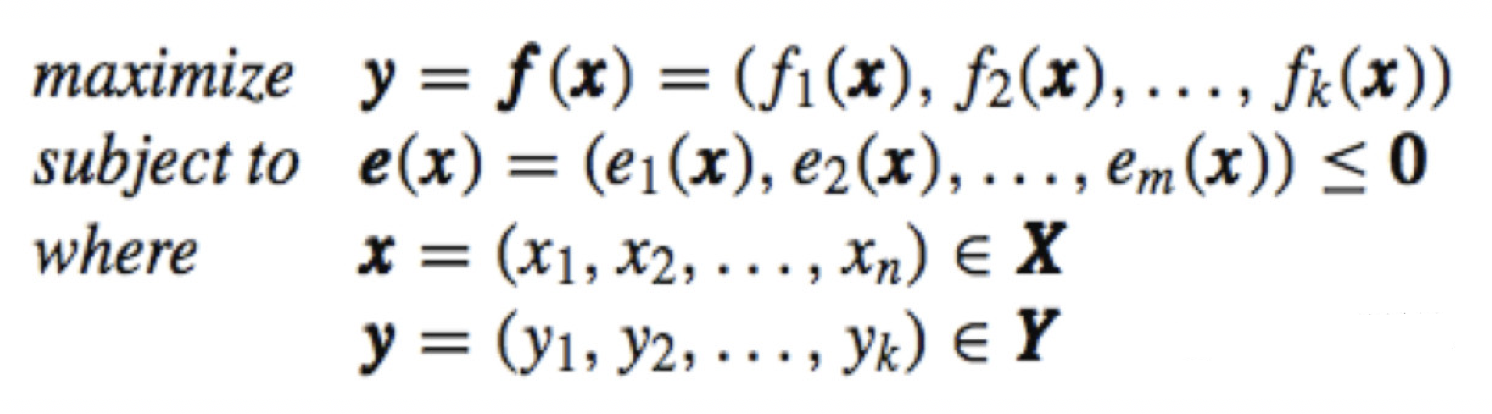拥有世界级领先的风控技术能力,历经十多年的发展,支付宝已从原先的 CTU 大脑全面进入人工智能时代,AlphaRisk[1] 作为第五代风控引擎,其核心正是由 AI 驱动的智能风险识别体系 AI Detect。
AI Detect 是一套智能、高效的风险识别算法体系,不仅包含了传统的像 GBDT,集成学习这种有监督学习算法,还包括了大量基于深度学习的无监特征生成算法,以及监督 & 无监督概念之外的新算法,本文介绍的工作正是其中之一。
当你站在超市收银台前,从点开支付宝二维码给扫码枪扫描,到支付成功的短短时间内,支付宝风控系统的上百个模型已经对这笔交易完成重重扫描,以检查是否手机丢失账户被盗用,是否欺诈被骗,是否有违法套现等风险。

实践中,不同的风险类型会给建模带来不同的挑战。
一般而言,识别套现风险的模型建设相比盗用和欺诈更困难一些,因为缺少主动的外部反馈机制,即缺少样本上的黑白标签。用户在被盗、被骗之后往往会联系支付宝,告知哪些交易非本人操作,抑或哪些交易是被骗的,这些反馈可以相对准确有效地沉淀成历史数据的标签。然而不会有套现的人在交易后主动告诉支付宝或者银行,这笔交易他是在做套现,而另一笔不是。
对于最常见的有监督算法来说,没有标签就会面临巧妇难为无米之炊的困境。因此,现有的套现风险识别方案多是基于无监督模型,如异常检测、图算法等。
无监督模型的优势正如其字面意义而言,即不需要标签,当然这也有其代价。
举例来说,异常检测模型 (如 Isolation Forest) 对于输入特征的要求远高于一般的有监督模型,通常在特征数量稍多的情况下就难以保持其分值顶部的性能。
而图算法则往往需要巨大的运算能力,才能应付支付宝每日亿级别的支付笔数,意味着更大的技术难度和计算成本。
当然,我们还可以用另一种方法解决无标签的问题:那就是基于人的业务经验进行人工标注,随后基于标注进行有监督学习得到模型。但这也面对着不少困难:
-
标注成本高:在我们的场景中,人工标注一个样本所需时间通常在 5~15 分钟,且需要具备相应的专业知识才能胜任,这使得我们难以大量标注样本,对标注样本信息量以及样本使用效率要求很高。
-
标注存在一定误差:即使是领域专家,在很多案例中也难以保证自己判断的准确率。一般来说,专家对于判定为黑的往往比较有信心,因为通常有证据可循。然而要判定为白,则需要排除所有不可能,这在事实上是难以真正做到的。
本文提出了一种基于主动学习(Active Learning[2],简称 AL)与半监督 (two-step Postive and Unlabled Learning[3],简称 PU) 结合的方法 Active PU Learning。
在人工标注工作量有限的情况下,改善了前述两点困难,并基于该方法针对信用卡交易,开发了一个套现风险的识别模型,在相同准确率下,相比无监督模型 Isolation Forest 提升套现交易识别量 3 倍。
2. 相关算法介绍
2.1 Active Learning
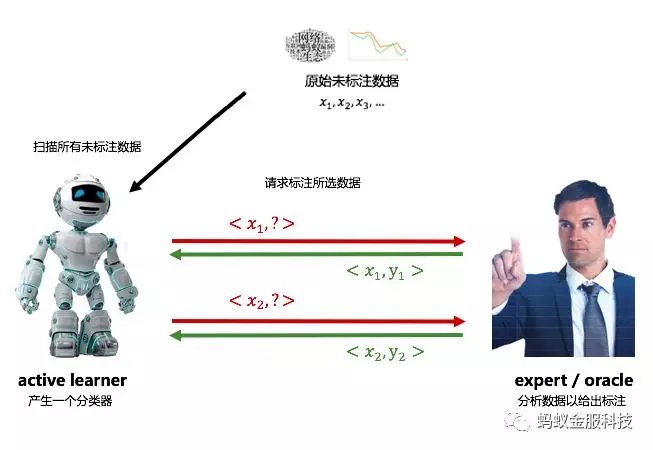
Active Learning 来自于一个朴素的想法,假如得到标签的成本很高昂,那就应该去寻找能对当前算法提升最大的样本请求打标,起到事半功倍的效果。该方法假设了一个 active learner 与专家进行多轮主动的交互,并持续的根据专家标注返回的结果更新分类器。
下图一直观的展示了 Active Learning 的基本工作流程。
2.2 PU Learning
AL 本身并不限制图一中分类器的具体种类,在更新样本后,按照新的样本库直接进行二分类的有监督分类是最简单直接的方法,但考虑到我们样本标注的来之不易以及 P 样本集的高可靠性,我们在这里采用一种半监督的算法 Two-step PU Learning,以提升样本的使用效率。
PU Learning 假定我们面对的数据中,真实黑样本中的小部分已经被标记了出来,构成集合 P(Positve),剩下所有数据都无标记构成集合 U(Unlabeled),如何建设模型可以对未标注的样本进行黑白分类?
把 U 中的样本标签视为缺失,那么我们便可以考虑使用 EM(Expectation Maximization) 的思想,EM 可以理解为是存在隐变量时 MLE(Maximum Likelihood Estimation) 的一种改进方法,这里我们在 E 步对缺失值进行填充,M 步基于上次填充结果进行迭代,如是多轮之后产出最终模型,这就是原始的 PU。
Two-step PU Learning 是在原始的 PU Learning 上的进一步发展,假如 P 在真实黑样本集上是有偏的,那么多轮的 EM 反而很有可能会起到负向的效果。Two-step PU Learning 引入了 spy 机制,可以更可靠的生成白样本。
下文所提到的 PU Learning,如不作特殊说明,都指代 two-step PU Learning。
3. 算法实现
3.1 算法 Workflow
Algorithm: Active PU Learning
1. 生成样本池:选取问题所需的样本集,并根据其他领域迁移而来的知识给部分样本打上正例标签
2.while 不满足停止条件 do
3. 采样:基于特定的采样方法,在采样环节选取出待标注样本
4. 标注:对待标注样本进行人工标注
5. 更新样本:采用特定的方法更新样本库
6. 更新模型:使用 two-step PU Learning 方法更新模型
7.end while
相比 Stikic[4] 中的方法,我们将采样与模型更新方式改进为批量采样以及 two-step PU Learning。
3.2 采样
在很多 Active Learning 工作中,采样与迭代是流式的,也即是基于当前算法采样一个,标注一个,算法迭代一次,基于当前算法采样一个,…, 如是循环。该方法的时间效率较低,假如标注 100 个样本,那就需要迭代 100 次模型,对于较大的训练数据集和较为复杂的模型,其时间成本是不可接受的。
作为替代,我们采取了 mini-batch 的方法批量采样,每次采样多个纪录,采样全都标注完成后算法才更新,在相同标注数量下显著减少了时间成本。
采样的方式基于 Uncertainty & Diversity 标准,即尽量取出当前模型最不确定同时又有着丰富的多样性的样本集。具体流程为:
1. 对新的数据 Dnew,使用当前模型打分
2. 抽取出若干个模型最不确定的白样本构成 Duncertain,不确定性的衡量基于模型打分而来。
3. 对 Duncertain 进行 K-Means 聚类,在每个类中取出最不确定的若干个样本,构成最终的待标注样本。
3.3 标注
专家进行标注,由于我们的方法对于 P 集合的信息会充分的信赖与利用,因此要求专家判断时,仅把具有充分信心的样本标注为 1,保证 P 集合的正确性。
3.4 更新样本
在这一环节,由于我们对于专家标注的 0 无法完全信任,因此会选择将标为 0 的部分放入 U 集合中,假装没有标注过。而对于标注为 1 的部分,则进行多倍的上采样后全都放入 P 集合,以强化这批样本在下一轮模型更新中的作用。
3.5 更新模型
常规的 Active Learning 通常如图二左边所示,专家会多次标注,逐渐扩充 L(Labeled) 集合,active learner 则会在多次学习 L 集合时不停提升自己的性能,我们称之为 LU setting。
然而在本场景,我们更像是一个 PU setting,专家多次标注,扩充 P(Positive) 集合,Learner 则在每次迭代的时候,基于 PU Learning 进行学习。
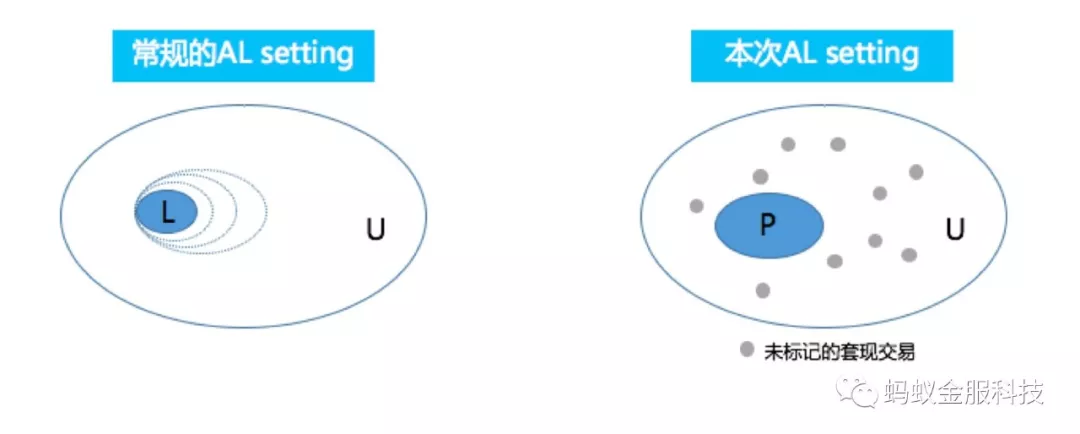
使用 PU Learning 的原因有两个,一是我们希望能够新的模型能够生长在已有知识的基础上,当前我们已经有大量的基础模块的信息带来高准确率但低召回率的黑样本标注。二是在样本标注量较小的情况下,U(Uncertain) 集合中的信息对于模型训练预期会带来更多的帮助。
我们基于 two-step PU 实现模型更新,之所以称为 two-step PU 是因为它可以分为两步,第一步是将 P 集合中部分样本作为 spy 混入 U 集合中并进行多轮 EM 迭代,第二步则是考察 spy 样本的分值分布,将 U 集合中所有分值小于 spy 中 10% 分位模型分值的样本标记为 0,生成 N(Negative) 集合,并基于此进行多轮 EM 迭代。
EM 迭代的思路在 two-step PU 过程中都是一致的,将 P 集合的样本 score 标记为 1,U 集合的样本 score 继承上一轮模型打分,训练新的模型拟合样本 score 并给出新的模型打分,即完成一轮迭代。
我们采用了 GBRT(Gradient Boosting Regression Tree)作为 Active Learning 的基分类器,这意味着在整个学习过程结束后,我们将产出一个 GBRT 模型。
4. 实验结果
我们总共设计了三个实验,分别证明了 two-step PU 的有效性,Active Learning 的有效性,以及 Active PU Learning 的方案有效性。
由于实验成本较高,三组实验并没有采取完全一样的 setting 与考察方法。在三组实验中,训练集的样本量都在百万级别,评估集都经过特殊的非均匀采样以提升计算效率。
4.1 two-step PU Learning 有效性
我们单独考察了 two-step PU 的算法有效性,考察方法如下:
1. 基于相同的训练数据集,训练三个模型,无监督模型 IF(Isolation Forest), 有监督模型 GBRT,two-step PU Learning 迭代生成的 GBRT(简称 PU GBRT);
2. 同一时间段的信用卡交易,IF, GBRT, PU GBRT 分别打分 ;
3. 在各自的 95~100 分位采样,得到总共 30 个样本 ;
4. 评估得到 IF&GBRT 准确率为 60%,PU GBRT 为 70%;
结果证明了,PU 产出的模型是更优的。
4.2 Active Learning 有效性
同样,我们单独考察了 Active Learning 的有效性,AL 的有效性考察可以分成三块:
1. 业务性能提升考察:对比当前无监督模型,考察是否 AL 带来模型性能提升;
2.AL 框架有效性考察:对比不利用人工标注数据的有监督 GBRT 模型,考察 AL 训练出来的 GBRT 模型是否有提升;
3.AL 采样方法有效性考察:对比随机采样标注相同个数训练得到 GBRT 模型,考察 AL 采样方法训练出来的 GBRT 模型是否有提升。
考察 1 的方法如下:
1. 基于训练数据集 A,训练无监督模型 IF;
2. 在数据集 A 上应用 Active Learning,额外标注部分数据并多轮迭代生成 RF(Random Forest)(简称 AL RF);
3. 同一时间段的信用卡交易,IF 和 AL RF 分别打分 ;
4. 分别在各自的 99 分位以上,95~99 分位,90~95 分位,80~90 分位采样,得到总共 70 个样本 ;
5. 评估得到 IF 准确率为 91%,AL RF 准确率为 94% 。
结果证明了,AL 产出的模型是更优的。考察 2 与考察 3 的方法类同,实验结果也都是正面的,此处不再赘述。
4.3 Active PU Learning 方案有效性
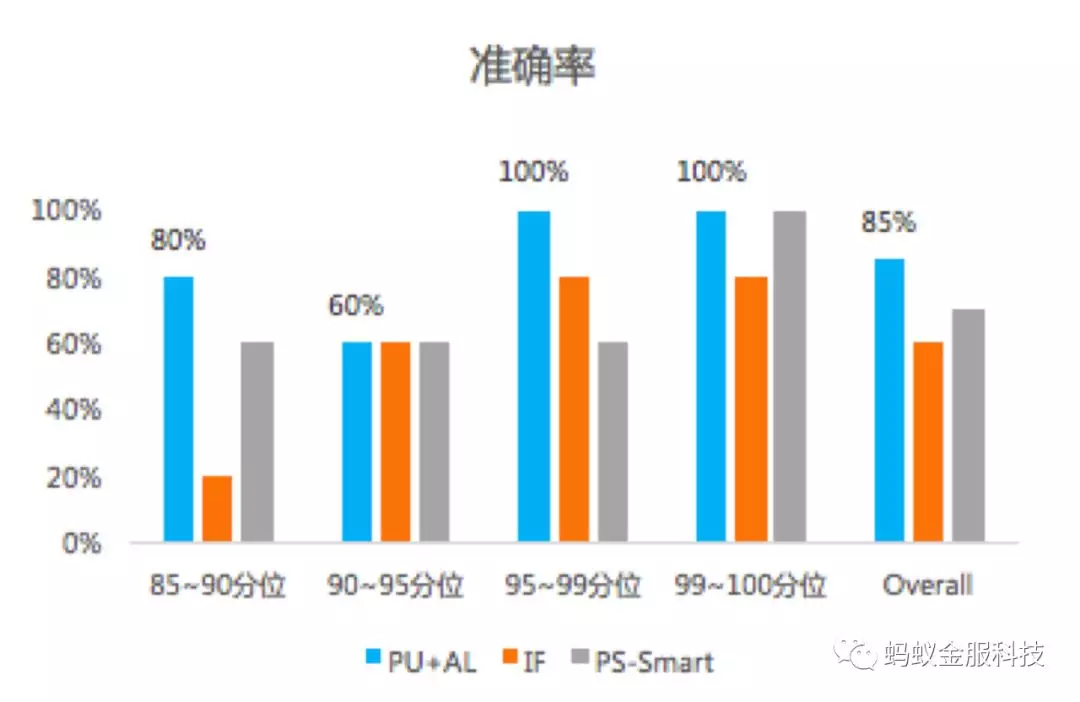
最后,我们考察了 Active PU Learning 是否拥有良好的性能(参见图三),考察方法如下:
1. 基于相同的训练数据集 A,训练两个模型,无监督模型 IF, 有监督模型 GBRT;
2. 在数据集 A 上应用 Active PU Learning,迭代生成 GBRT(简称 APU GBRT);
3. 同一时间段的信用卡交易,IF, GBRT, APU GBRT 分别打分 ;
4. 在各自的 85-90 分位,90-95 分位,95-99 分位,99-100 分位抽取 5 个样本,进行人工标注 ;
5. 横向比较相同 Percentile 下,不同模型的标注准确率,在每个区间上,APU GBRT 都胜于或等同于另两个模型的准确率。
5. 总结与展望
在各行各业的机器学习问题中,缺少标签或者标签获取代价昂贵的现象是普遍存在的,从业者为了在这类场景中建设可靠的模型实践了各种方法。
本文的 Active PU Learning 方法集中在了如何以较小的代价,引入更多的外部信息,并且更好的利用当前已有标签知识。
相比之前的同类工作,Active PU Learning 主要贡献在于引入了 two-step PU Learning 改进了 Active Learning 中模型更新的方法。当然该方法也有其局限,算法对人工标注的质量有很高的要求,整套方案的训练流程相比常规的 GBRT 也更耗时。
目前,我们在反套现该场景应用 Active PU Learning 产出的模型后,相比基于 Isolation Forest 方法在相同准确率下,识别量提升 3 倍。
作为一种验证已有成效的方法论,在内我们正在积极的拓展应用场景,对外则希望本文能给所有的读者带来一些启发。
6. 参考文献
[1] 支付宝风险引擎首次公开展示 AlphaRisk 首秀 Money20/20 Asia
[2] Settles B. Active Learning Literature Survey[J]. University of Wisconsinmadison, 2009, 39(2):127–131.
[3] Liu B, Lee W S, Yu P S, et al. Partially Supervised Classification of Text Documents[C]// Nineteenth International Conference on Machine Learning. Morgan Kaufmann Publishers Inc. 2002:387-394.
[4] Stikic M, Van Laerhoven K, Schiele B. Exploring semi-supervised and active learning for activity recognition[C]// IEEE International Symposium on Wearable Computers. IEEE, 2008:81-88.
作者介绍:
蚂蚁金服风险与决策中心团队,负责其国内外业务场景的交易和资金风险防控,包括盗用、欺诈、营销作弊、垃圾注册识别和决策等。团队以大数据积淀挖掘和前沿机器学习研发应用为核心能力,开发了支付宝第五代风控引擎 AlphaRisk,运用人工智能全面升级了蚂蚁金服的风控体系。
本文转载自公众号蚂蚁金服科技(ID:Ant-Techfin)。
原文链接: