标签:技术 标识 key count common ext1 lis 相同 词语
记录下书中的例子
首先得下载
import nltk nltk.download()
下载器的Collections选项卡下,选择book然后下载
如果下载缓慢或者报错,建议找百度云的包效果是一样的
进入IDLE,输入from nltk.book import *,出现以下结果代表安装完成
from nltk.book import * *** Introductory Examples for the NLTK Book *** Loading text1, ..., text9 and sent1, ..., sent9 Type the name of the text or sentence to view it. Type: ‘texts()‘ or ‘sents()‘ to list the materials. text1: Moby Dick by Herman Melville 1851 text2: Sense and Sensibility by Jane Austen 1811 text3: The Book of Genesis text4: Inaugural Address Corpus text5: Chat Corpus text6: Monty Python and the Holy Grail text7: Wall Street Journal text8: Personals Corpus text9: The Man Who Was Thursday by G . K . Chesterton 1908
键入text.concordance("关键字")
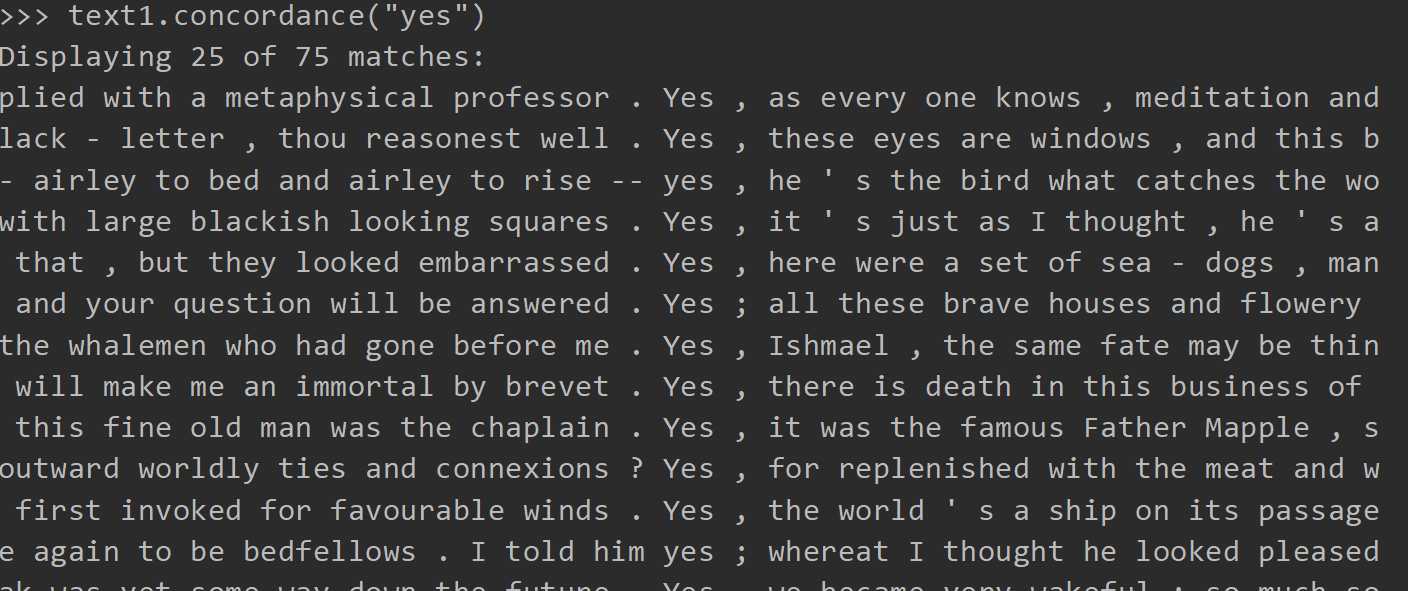
结果还是挺明显的

common_contexts(研究共用两个或两个以上的上下文)


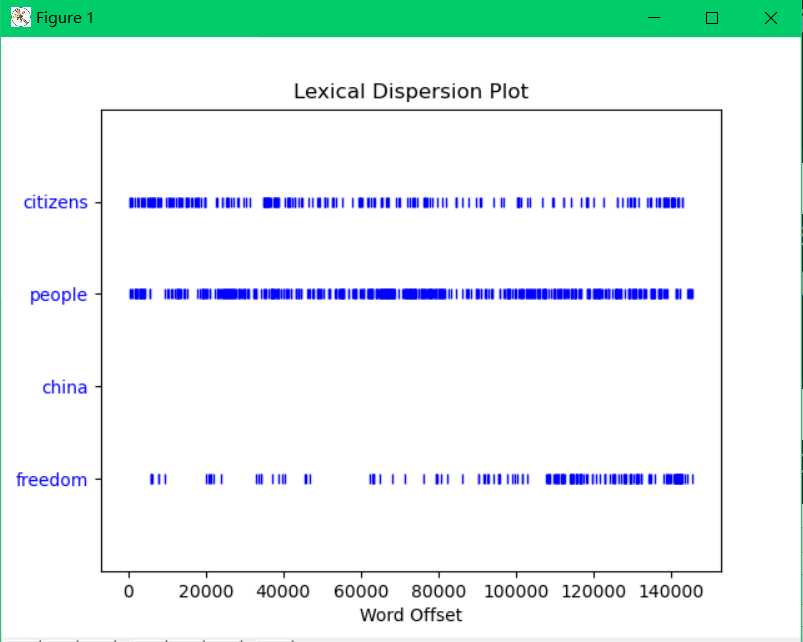

当然也可以texte2.generate(),text3.generate(),每一篇文章的风格不同,书上说每次运行后,输出文本都会不同,实际上我的每次都相同
计数词汇(文本中出现的单词和标点符号)
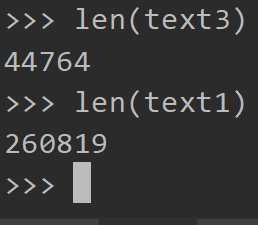
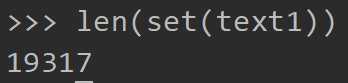
这个是未去重的
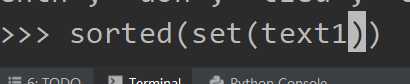
输出结果会按照英文字母顺序排序的所有唯一标识符(单词和标点)
sorted()是排序,单独set()也会得到,但未排序,然和使用len获取唯一项目类型(单词和标点符号)个数
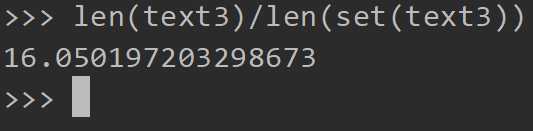
表示该篇文章每个单词平均使用16次

text4.count(‘‘)表统计该单词在文中出现的次数
然后讲了一些列表(书中翻译为链表,老是会联想到数据结构中的链表)的运算,就真是来水页数的
频率分布
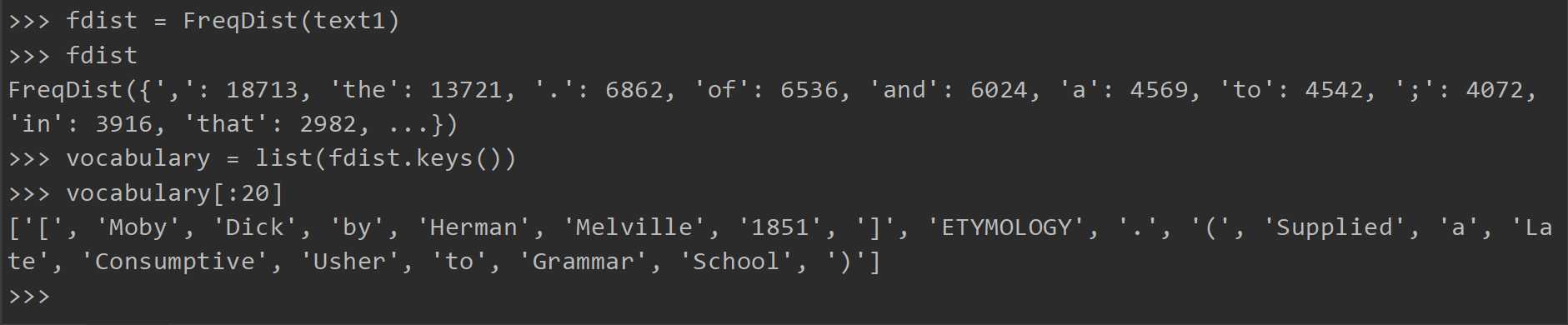
FreqDist将统计各个标识符出现的次数,keys提供所有不同类型的列表(python3中需要按list(fdist.keys())这样写,不然会报错
这里vocabulary[:20]代表取出词频最高的20个词(含标点)
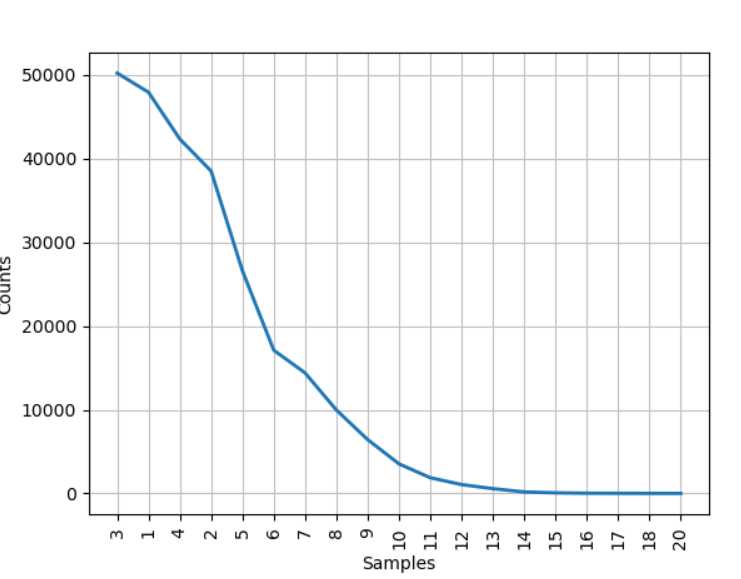
作图:

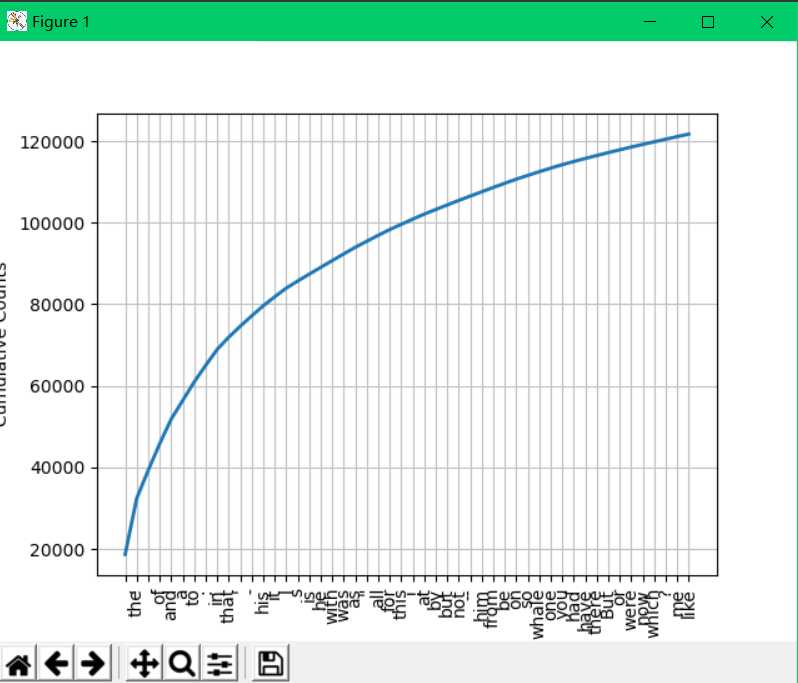
若不加上cumulative = True,即不考虑累加,则会显示出每个词的次数
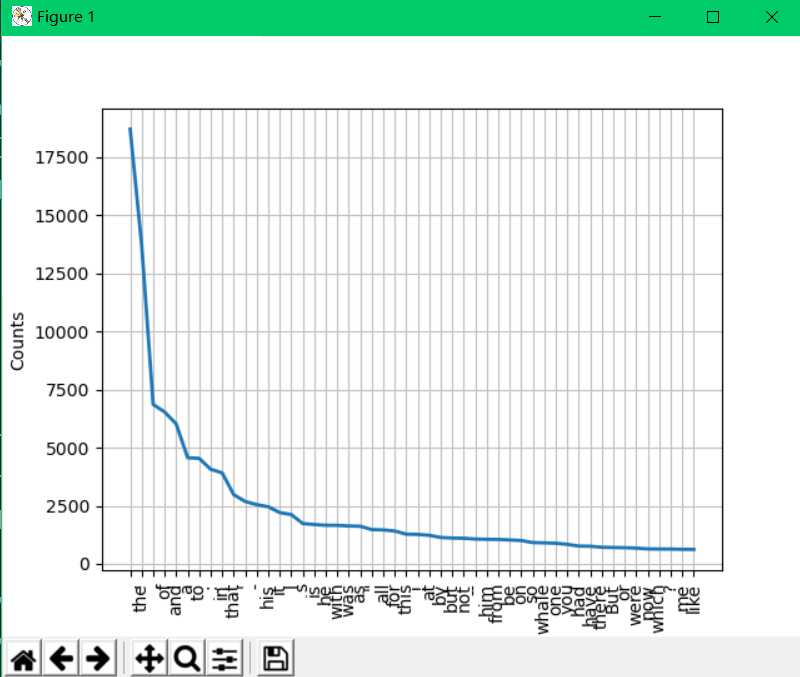
只出现一次的词
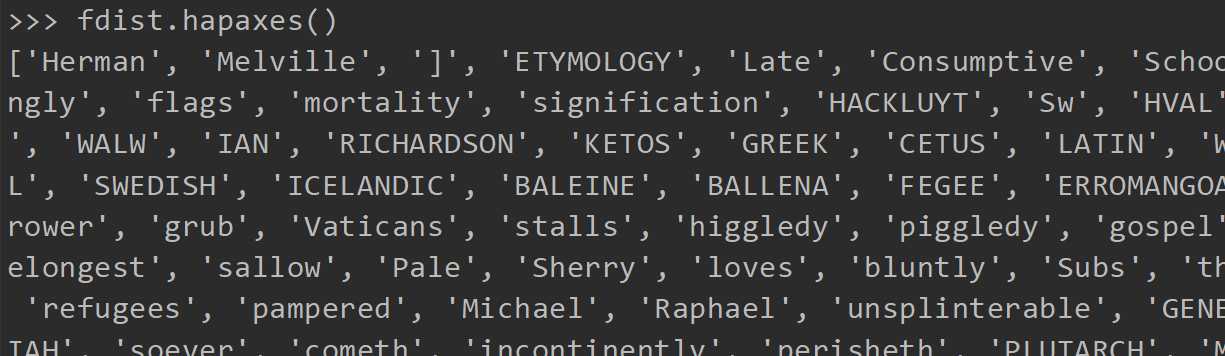

可以看到有9002个词,在文中只出现一次
细粒度的选择词
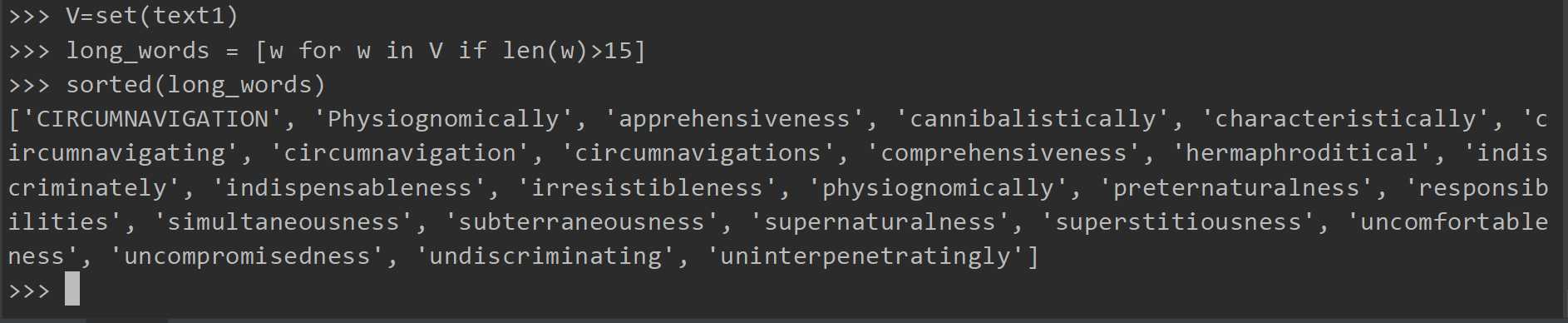
这样就可以选择出在text1中的并且该词长度大于15的所有词
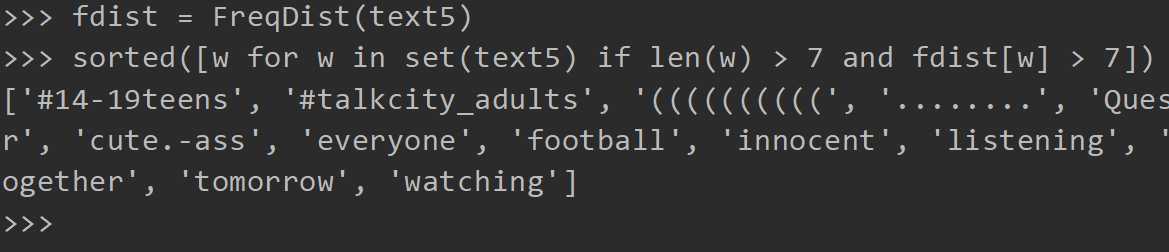
以下是在text5中所有长度超过7并且出现次数也超过7次的词
词语搭配和双连词
搭配是不经常在一起出现的词序列。因此 red wine 是,the wine 不是。

计算其他东西

这样会输出每个标识符的长度

这样得到了该文章中所有词的不同长度(也就是说他们由1,4,2...个字母组成,最长20,没有21的)
再键入,得到统计

也可以这样获取出现len最长的,和出现多少次
同样这里也可以绘图来直观的展示
标签:技术 标识 key count common ext1 lis 相同 词语
原文地址:https://www.cnblogs.com/Truedragon/p/12817308.html