标签:数据量 多数据源 vip 建立 错误 基于 dai prope request
数据采集利用各种手段获取数据,数据样式不限制,但一般而言是形如 excel 或者 csv 这样的表格格式。
数据采集: urllib , requests
数据解析: Xpath , BS4 , 正则表达式
数据持久化存储: pd.to_csv , pd.to_excel , MySQL , Redis
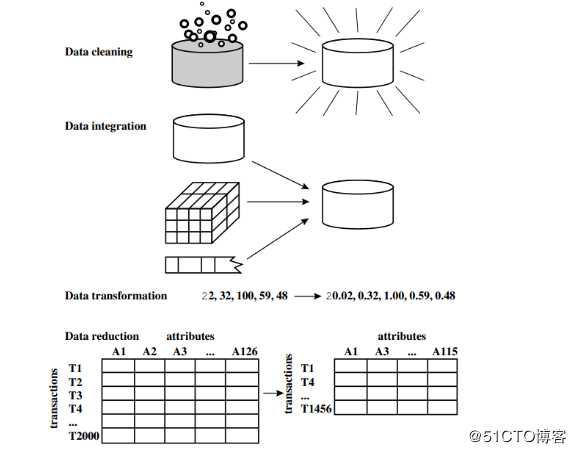
一般而言,数据分析和数据挖掘领域的处理的数据都是海量的数据,这样的数据难免会出现问题。
数据预处理占到数据挖掘工作的60%,这是最重要也是最核心的领域.
数据预处理分为数据清洗、数据集成、数据变换和数据规约。
数据清洗就是删除无关数据、重复数据、平滑噪声数据、处理缺失值和异常值。
有些信息暂时无法获取。例如在医疗数据库中,并非所有病人的所有临床检验结果都能在给定的时
间内得到,就致使一部分属性值空缺出来。又如在申请表数据中,对某些问题的反映依赖于对其他
问题的回答。
有些信息是被遗漏的。可能是因为输入时认为不重要、忘记填写了或对数据理解错误而遗漏,也可
能是由于数据采集设备的故障、存储介质的故障、传输媒体的故障、一些人为因素等原因而丢失
了。有些对象的某个或某些属性是不可用的。也就是说,对于这个对象来说,该属性值是不存在的,如
一个未婚者的配偶姓名、一个儿童的固定收入状况等。
有些信息(被认为)是不重要的。如一个属性的取值与给定语境是无关的,或训练数据库的设计者
并不在乎某个属性的取值(称为 dont-care value )。
获取这些信息的代价太大。
系统实时性能要求较高,即要求得到这些信息前迅速做出判断或决策。
数据集中不含缺失值的变量称为完全变量,数据集中含有缺失值的变量称为不完全变量。
从缺失的分布来将缺失可以分为完全随机缺失,随机缺失和完全非随机缺失。
完全随机缺失(missing completely at random, MCAR ):指的是数据的缺失是完全随机的,
不依赖于任何不完全变量或完全变量,不影响样本的无偏性,如家庭地址缺失;
随机缺失(missing at random,MAR):指的是数据的缺失不是完全随机的,即该类数据的缺失依
赖于其他完全变量,如财务数据缺失情况与企业的大小有关;
非随机缺失(missing not at random, MNAR ):指的是数据的缺失与不完全变量自身的取值有关,
如高收入人群不愿意提供家庭收入;
随机缺失和非随机缺失,直接删除记录是不合适的,随机缺失可以通过已知变量对缺失值进行估计,而
非随机缺失的非随机性还没有很好的解决办法。
我给你一组数据,如果要你做数据清洗,你会怎么做?
数据存在 2 个问题:
典韦出现了 2 次
张飞的数学成绩缺失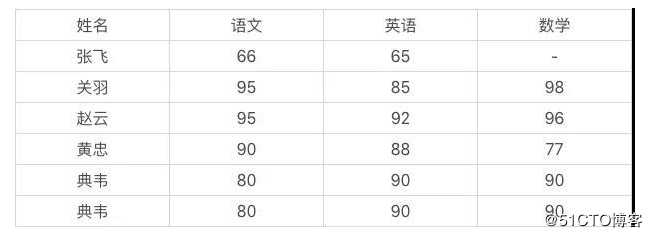
对于各种类型数据的缺失,我们到底要如何处理呢?以下是处理缺失值的四种方法:删除记录,数据填
补,和不处理。
删除记录
简单粗暴
在样本数据量十分大且缺失值不多的情况下非常有效,但如果样本量本身不大且缺失也不少,那么
不建议使用"""
删除缺失数据
"""
import pandas as pd
import numpy as np
#创建一个带有缺失值的DataFrame对象
df = pd.DataFrame(np.arange(12).reshape((3, 4)), index=[‘user1‘, ‘user2‘,
‘user3‘], columns=[‘views‘, ‘likes‘, ‘transfers‘, ‘saves‘])
print("源数据: \n", df)
df.loc[:2, :1]= np.nan
print("缺失值数据: \n", df)
#删除行,使用参数axis=0
print(df.dropna(axis=0))
#删除列, 使用参数axis=1
print(df.dropna(axis=1))
#删除数据表中含有空值的行
print(df.dropna())
对缺失值的插补大体可分为两种:替换缺失值,拟合缺失值,虚拟变量。替换是通过数据中非缺失数据
的相似性来填补,其核心思想是发现相同群体的共同特征,拟合是通过其他特征建模来填补,虚拟变量
是衍生的新变量代替缺失值。
均值插补。
对于定类数据:使用 众数(mode)填补,比如一个学校的男生和女生的数量,男生500
人,女生50人,那么对于其余的缺失值我们会用人数较多的男生来填补。
对于定量(定比)数据:使用平均数(mean)或中位数(median)填补,比如一个
班级学生的身高特征,对于一些同学缺失的身高值就可以使用全班同学身高的平均值或
中位数来填补。
"""
均值差补
"""
import numpy as np
import pandas as pd
df = pd.DataFrame(np.arange(12).reshape((4, 3)),
index=[‘user1‘, ‘user2‘, ‘user3‘, ‘user4‘],
columns=[‘price‘, ‘count‘, ‘info‘])
df[‘price‘][:1] = np.nan
df[‘price‘][3] = 3
print("缺失值数据: \n", df)
#使用price均值对NA进行填充
df_mean = df[‘price‘].fillna(df[‘price‘].mean())
#使用price中位数对NA进行填充
df_median = df[‘price‘].fillna(df[‘price‘].median())
#使用price众数对NA进行填充
df_mode = df[‘price‘].fillna(df[‘price‘].mode())
print("均值填充: \n", df_mean)
print("中位数填充: \n", df_median)print("众数填充: \n", df_median)
插值模型
拉格朗日插值法( scipy 实现)
拉格朗日插值法可以找到一个多项式,其恰好在各个观测的点取到观测到的值。这样的多项式称为
拉格朗日(插值)多项式。数学上来说,拉格朗日插值法可以给出一个恰好穿过二维平面上若干个
已知点的多项式函数。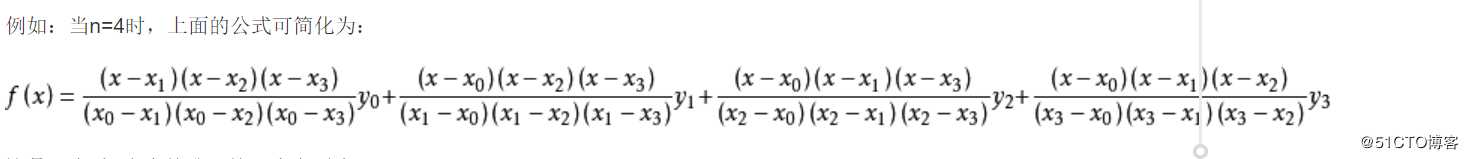

from scipy.interpolate import lagrange
x = [3, 6, 9]
y = [10, 8, 4]
lagrange(x,y)
#poly1d([ -0.11111111, 0.33333333,
10.
])
#如果U7>:*? (tyyyyyyyyyyyy(要进行插值操作,可以:
lagrange(x, y)(10)
# 2.222222牛顿插值法( scipy 未实现)
牛顿插值法是曲线拟合插值法中的一种,适合采用所有的数据都精确的情况下。
多数据源数据仓库化。
实体识别
同名异义
异名同义
单位不统一
冗余属性识别
同一属性多次出现
同一属性命名不一致导致重复
规范化处理数据,便于使用。
简单函数变换
常用来将不具有正态分布的数据变换成具有正态分布的数据。
规范化
最小-最大规范化
零-均值规范化(使用最多)
小数定标规范化
连续属性离散化
等宽法
等频法
聚类
属性构造
推导属性
小波变换
新型数据分析工具
降低错误数据对建模的影响,减少存储成本
属性规约
数值规约
直方图
聚类
抽样
参数回归
根据挖掘目标和数据形式的不同,可以建立分类与预测、聚类分析、关联规则、时序模式、偏差检测等
模型。
如餐饮行业想知道哪些用户会离我而去,哪些用户可能成为VIP。
常用的分类和预测算法:
python常用分类预测模型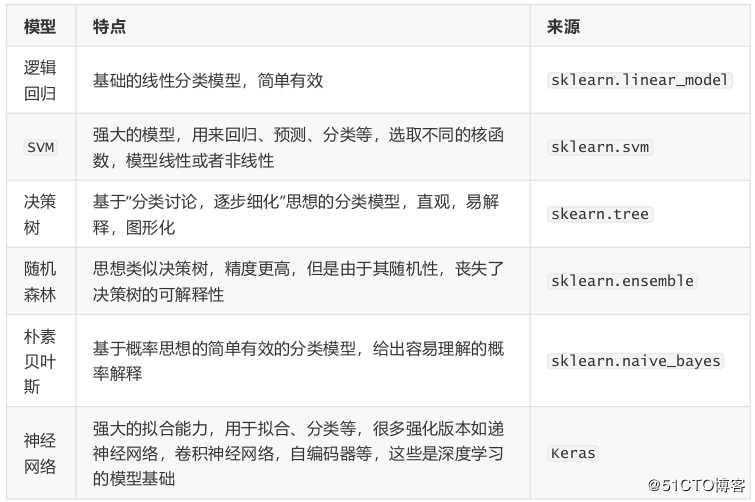
聚类分析
群体上的考究。
和分类不同,这里所有的数据都是事先没有类别的。
Keras这是非监督的学习算法。
原理:给定一组数据,根据数据自身距离或者相似度将其划分为若干组,原则为组内距离最小而组
间距离最大。
常用聚类方法。
划分方法(分裂):K-Means算法(K-平均)、 K-MEDOIDS 算法(K-中心点)、 CLARANS 算
法(基于选择的算法)
层次分析方法:BIRCH算法(平均迭代规约和聚类)、CURE算法(代表点聚类)、
CHAMELEON算法(动态模型)
基于密度的方法: DBSCAN 算法(基于高密度连接区域)、 DENCLUE算法 (密度分布函
数)、OPTICS算法(对象排序识别)
基于网格的方法:STING算法(统计信息网络)、 CLIOUE 算法(聚类高维空间)、WAVE-
CLUSTER算法(小波变换)
基于模型的方法:统计学方法、神经网络方法 - 常用聚类分析算法
import numpy as np
import pandas as pd
def create_csv():
"""测试删除缺失值的数据准备"""
#创建一个带有缺失值的DataFrame对象
df = pd.DataFrame(np.arange(12).reshape((3, 4)),
index=[‘user1‘, ‘user2‘, ‘user3‘],
columns=[‘views‘, ‘likes‘, ‘transfers‘, ‘saves‘])
#第一行前2列, np.nan缺失值
df.iloc[:1, :2] = np.nan
#将数据存储到csv文件中
df.to_csv(‘doc/data-clean.csv‘)
def drop_null_data():
# 返回市DataFrame对象
df = pd.read_csv(‘doc/data-clean.csv‘)
#df1 = df.dropna() # 默认情况下,将有缺失值的一行信息或者多行信息删除
df1 = df.dropna(axis=1) # axis=1, 删除有缺失值的一列或者多列(不建议使用)
print(df1)
if __name__ == ‘__main__‘:
drop_null_data()import numpy as np
import pandas as pd
#生成DataFrame数据(一般是从文件加载出来的)
df = pd.DataFrame(np.arange(12).reshape(4, 3),
index=[‘user1‘, ‘user2‘, ‘user3‘, ‘user4‘],
columns=[‘price‘, ‘count‘, ‘info‘]
)
#df.price获取price这一列信息。 iloc通过索引进行定位
"""
price count info
user1 NaN 1 2
user2 3.0 4 5
user3 6.0 7 8
user4 NaN 10 11
"""
df.price.iloc[0] = np.nan
df.price.iloc[3] = 3
print("源数据: \n", df)
#使用均值填充
price_mean = df.price.mean() # 获取价格这一列的均值
df_mean = df[‘price‘].fillna(price_mean)
#使用中位数填充
price_median = df.price.median()
df_median = df[‘price‘].fillna(price_median)
print(df_median)
#众数填充
price_mode = df[‘price‘].mode() # 众数返回的是Series对象, 所以需要获取对应的索引
df_mode = df[‘price‘].fillna(price_mode[0])
print(df_mode)from datetime import date
import matplotlib.pyplot as plt
import seaborn as sns
import tushare as ts
#正常显示画图时出现的中文和负号
"""
Linux/Mac:
1. 寻找显示中文的字体库 fc-list :lang=zh
2. 实例化字体对象
my_font = font_manager.FontProperties(fname=‘字体库的文件名")
3. 指定中文字体时, 设置字体的属性
plt.title(‘中文标题‘, fontproperties=my_font)
"""
def draw_close(code):
"""
1. 近一月股票收盘价走势曲线
2. 5日均线、10日均线以及20日均线
3. 每日收盘价涨跌幅度 diff(差值)/pct_change(涨/跌幅百分比)
:param code: 股票编码
:return:
"""
#数据准备与样式设置
sns.set(style=‘whitegrid‘)
plt.rcParams[‘font.sans-serif‘] = [‘SimHei‘]
plt.rcParams[‘axes.unicode_minus‘] = False
end = date.today() # 日期对象
start = date(end.year, end.month - 1, end.day) # 日期对象
end = str(end)
start = str(start)
#获取code股票的过去一年的历史数据
df = ts.get_hist_data(code, start, end)
print(df)
#创建子图
ax1 = plt.subplot(3, 1, 1)
#获取收盘价df.close/df[‘close‘], 绘制曲线图
#plt.plot(df.index, df.close)
df[‘close‘].plot(ax=ax1, color=‘orange‘, ls=‘-.‘, label=‘收盘价‘)
df[‘open‘].plot(ax=ax1, color=‘b‘, ls=‘-‘, label=‘开盘价‘)
ax1.set_title("%s股票收盘价/收盘价走势曲线" % (code))
#loc指定图例的显示位置
ax1.legend(loc=‘upper right‘)
#创建子图
ax2 = plt.subplot(3, 1, 2)
ax2.set_title("%s股票均线走势曲线" % (code))
df[‘ma5‘].plot()
df[‘ma10‘].plot()
df[‘ma20‘].plot()
ax2.legend(loc=‘upper right‘)
#创建子图
ax3 = plt.subplot(3, 1, 3)
ax3.set_title("%s股票每日涨跌幅度曲线" % (code))
df[‘Daily Return‘] = df[‘close‘].pct_change()
df[‘Daily Return‘].plot(color=‘green‘)
plt.show()
if __name__ == ‘__main__‘:
draw_close(‘600848‘)标签:数据量 多数据源 vip 建立 错误 基于 dai prope request
原文地址:https://blog.51cto.com/13810716/2492187