标签:title and 探索 target 特征 info rgs 指定 dimens
代码来源: https://github.com/eriklindernoren/ML-From-Scratch
支持向量机代码:
from __future__ import division, print_function import numpy as np import cvxopt from mlfromscratch.utils import train_test_split, normalize, accuracy_score from mlfromscratch.utils.kernels import * from mlfromscratch.utils import Plot # Hide cvxopt output cvxopt.solvers.options[‘show_progress‘] = False class SupportVectorMachine(object): """The Support Vector Machine classifier. Uses cvxopt to solve the quadratic optimization problem. Parameters: ----------- C: float Penalty term. kernel: function Kernel function. Can be either polynomial, rbf or linear. power: int The degree of the polynomial kernel. Will be ignored by the other kernel functions. gamma: float Used in the rbf kernel function. coef: float Bias term used in the polynomial kernel function. """ def __init__(self, C=1, kernel=rbf_kernel, power=4, gamma=None, coef=4): #系数C self.C = C #核函数 self.kernel = kernel self.power = power self.gamma = gamma self.coef = coef self.lagr_multipliers = None self.support_vectors = None self.support_vector_labels = None self.intercept = None def fit(self, X, y): #样本数,特征数 n_samples, n_features = np.shape(X) # Set gamma to 1/n_features by default if not self.gamma: self.gamma = 1 / n_features # Initialize kernel method with parameters #初始化核函数的一些参数 self.kernel = self.kernel( power=self.power, gamma=self.gamma, coef=self.coef) # Calculate kernel matrix #计算核矩阵 kernel_matrix = np.zeros((n_samples, n_samples)) for i in range(n_samples): for j in range(n_samples): kernel_matrix[i, j] = self.kernel(X[i], X[j]) # Define the quadratic optimization problem #cvxopt是凸优化库 #cvxopt.matrix(array,dims)用于将array按dims进行重新排列 #np.outer用于计算两个向量的外积 P = cvxopt.matrix(np.outer(y, y) * kernel_matrix, tc=‘d‘) q = cvxopt.matrix(np.ones(n_samples) * -1) A = cvxopt.matrix(y, (1, n_samples), tc=‘d‘) b = cvxopt.matrix(0, tc=‘d‘) if not self.C: #Numpy.identity()输入n为行数或列数,返回一个n*n的对角阵, #对角线元素为1,其余为0。dtype可选,默认为float格式。 G = cvxopt.matrix(np.identity(n_samples) * -1) h = cvxopt.matrix(np.zeros(n_samples)) else: G_max = np.identity(n_samples) * -1 G_min = np.identity(n_samples) G = cvxopt.matrix(np.vstack((G_max, G_min))) h_max = cvxopt.matrix(np.zeros(n_samples)) h_min = cvxopt.matrix(np.ones(n_samples) * self.C) h = cvxopt.matrix(np.vstack((h_max, h_min))) # Solve the quadratic optimization problem using cvxopt minimization = cvxopt.solvers.qp(P, q, G, h, A, b) # Lagrange multipliers #np.ravel用于降维 lagr_mult = np.ravel(minimization[‘x‘]) # Extract support vectors # Get indexes of non-zero lagr. multipiers idx = lagr_mult > 1e-7 # Get the corresponding lagr. multipliers self.lagr_multipliers = lagr_mult[idx] # Get the samples that will act as support vectors self.support_vectors = X[idx] # Get the corresponding labels self.support_vector_labels = y[idx] # Calculate intercept with first support vector self.intercept = self.support_vector_labels[0] for i in range(len(self.lagr_multipliers)): self.intercept -= self.lagr_multipliers[i] * self.support_vector_labels[ i] * self.kernel(self.support_vectors[i], self.support_vectors[0]) def predict(self, X): y_pred = [] # Iterate through list of samples and make predictions for sample in X: prediction = 0 # Determine the label of the sample by the support vectors for i in range(len(self.lagr_multipliers)): prediction += self.lagr_multipliers[i] * self.support_vector_labels[ i] * self.kernel(self.support_vectors[i], sample) prediction += self.intercept y_pred.append(np.sign(prediction)) return np.array(y_pred)
其中使用到的部分函数:

Cvxopt.solvers.qp(P,q,G,h,A,b)
标准形式:
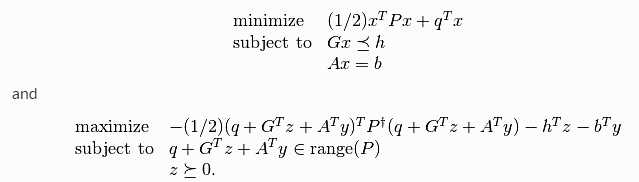
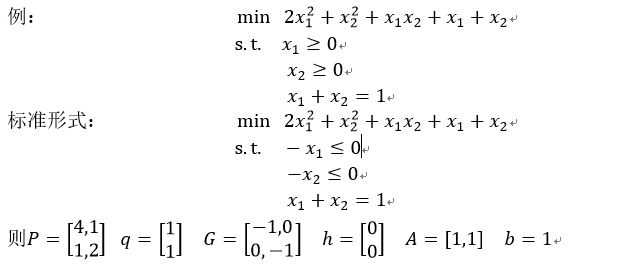

核函数定义:
import numpy as np def linear_kernel(**kwargs): def f(x1, x2): return np.inner(x1, x2) return f def polynomial_kernel(power, coef, **kwargs): def f(x1, x2): return (np.inner(x1, x2) + coef)**power return f def rbf_kernel(gamma, **kwargs): def f(x1, x2): distance = np.linalg.norm(x1 - x2) ** 2 return np.exp(-gamma * distance) return f
np.inner()用于返回两个向量的内积。np.linalg.norm()用于求范数,ord参数指定使用的范数,如果没有指定,则是求整体矩阵元素平方和再开根号。
运行主代码:
from __future__ import division, print_function import numpy as np from sklearn import datasets # Import helper functions import sys sys.path.append("/content/drive/My Drive/learn/ML-From-Scratch/") from mlfromscratch.utils import train_test_split, normalize, accuracy_score, Plot from mlfromscratch.utils.kernels import * from mlfromscratch.supervised_learning import SupportVectorMachine def main(): data = datasets.load_iris() X = normalize(data.data[data.target != 0]) y = data.target[data.target != 0] y[y == 1] = -1 y[y == 2] = 1 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33) clf = SupportVectorMachine(kernel=polynomial_kernel, power=4, coef=1) clf.fit(X_train, y_train) y_pred = clf.predict(X_test) accuracy = accuracy_score(y_test, y_pred) print ("Accuracy:", accuracy) # Reduce dimension to two using PCA and plot the results Plot().plot_in_2d(X_test, y_pred, title="Support Vector Machine", accuracy=accuracy) if __name__ == "__main__": main()
使用的数据集是sklearn自带的鸢尾花数据集,划分后的训练集大小为:
(67, 4) (67,)
需要注意的是鸢尾花数据集中有三类,分别是0,1,2类,这里只提取了其中的第1,2类,并且对样本进行了标准化,对标签重新进行编号,记为+1和-1.
部分数据及对应标签如下:
[[0.69198788 0.34599394 0.58626751 0.24027357] [0.70779525 0.31850786 0.60162596 0.1887454 ] [0.73239618 0.38547167 0.53966034 0.15418867] [0.69299099 0.34199555 0.60299216 0.19799743] [0.72712585 0.26661281 0.60593821 0.18178146]] [ 1 -1 -1 1 1]
这里使用的核函数是多项式核函数,上面已经给出了其具体代码,这里设定power=4, coef=1。
以该输入为例,我们一步步探索整个支持向量机运行的过程:
(1)fit()函数传入X_train和y_train,n_samples=67,n_features=4
(2)这里的gamma用不上,定义了多项式核函数:(x1⋅x2+1)**4
(3)计算核矩阵,其大小是(67,67)
(4)计算P,q,A,b,大小分别是
P: (67, 67) q: (67, 1) A: (1, 67) b: (1, 1)
(5)计算G,h
G: (134, 67)
h: (134, 1)
(6)计算minimization
{ ‘x‘: <67x1 matrix, tc=‘d‘>, ‘y‘: <1x1 matrix, tc=‘d‘>, ‘s‘: <134x1 matrix, tc=‘d‘>, ‘z‘: <134x1 matrix, tc=‘d‘>, ‘status‘: ‘optimal‘, ‘gap‘: 6.025067170026107e-06, ‘relative gap‘: 2.658291994898124e-07, ‘primal objective‘: -22.66518193482733, ‘dual objective‘: -22.6651879598945, ‘primal infeasibility‘: 5.244963534670188e-16, ‘dual infeasibility‘: 1.4242235222101717e-14, ‘primal slack‘: 1.992950796227594e-08, ‘dual slack‘: 2.0187091588623967e-08, ‘iterations‘: 8 }
接着取出键为x的那一项<67x1 matrix, tc=‘d‘>,再分别计算以下项:
lagr_mult: [9.99999993e-01 3.11335122e-07 5.76626923e-08 9.99999986e-01 9.99999960e-01 8.40647046e-09 1.62550393e-08 9.99999990e-01 8.80788872e-09 7.47600294e-09 9.99999993e-01 1.38140431e-08 9.99999841e-01 1.84408877e-08 4.45365428e-08 9.99999993e-01 9.99999994e-01 7.31294539e-09 9.99999981e-01 2.81302345e-01 4.29885349e-08 9.99999993e-01 6.50674166e-08 1.53345935e-08 9.99999997e-01 9.99999980e-01 1.60572220e-08 4.62959213e-09 1.74974625e-08 9.99999994e-01 6.71173485e-09 1.57489685e-08 9.99999965e-01 9.99999988e-01 1.01875501e-08 3.19854125e-01 1.93465392e-08 9.99999991e-01 9.99999969e-01 1.58210493e-08 9.99999992e-01 6.53854743e-08 9.49484746e-09 9.99999991e-01 9.99999975e-01 1.33182181e-08 2.74386270e-07 9.99999985e-01 9.58193356e-09 1.42607893e-08 1.44826324e-08 9.99999988e-01 9.99999991e-01 1.05018808e-08 9.99999983e-01 8.02961322e-09 6.01155709e-01 3.54164542e-07 9.99999994e-01 9.99999972e-01 3.49899863e-08 1.56995796e-08 9.99999986e-01 9.99999949e-01 1.95124926e-08 1.13750234e-07 3.24069998e-09] idx: [ True True False True True False False True False False True False True False False True True False True True False True False False True True False False False True False False True True False True False True True False True False False True True False True True False False False True True False True False True True True True False False True True False True False] self.lagr_multipliers: [9.99999993e-01 3.11335122e-07 9.99999986e-01 9.99999960e-01 9.99999990e-01 9.99999993e-01 9.99999841e-01 9.99999993e-01 9.99999994e-01 9.99999981e-01 2.81302345e-01 9.99999993e-01 9.99999997e-01 9.99999980e-01 9.99999994e-01 9.99999965e-01 9.99999988e-01 3.19854125e-01 9.99999991e-01 9.99999969e-01 9.99999992e-01 9.99999991e-01 9.99999975e-01 2.74386270e-07 9.99999985e-01 9.99999988e-01 9.99999991e-01 9.99999983e-01 6.01155709e-01 3.54164542e-07 9.99999994e-01 9.99999972e-01 9.99999986e-01 9.99999949e-01 1.13750234e-07] self.support_vectors: [[0.72785195 0.32870733 0.56349829 0.21131186] [0.71491405 0.30207636 0.59408351 0.21145345] [0.72460233 0.37623583 0.54345175 0.19508524] [0.76467269 0.31486523 0.53976896 0.15743261] [0.73122464 0.31338199 0.56873028 0.20892133] [0.71562645 0.3523084 0.56149152 0.22019275] [0.71366557 0.28351098 0.61590317 0.17597233] [0.71066905 0.35533453 0.56853524 0.21320072] [0.73089855 0.30454106 0.58877939 0.1624219 ] [0.73544284 0.35458851 0.55158213 0.1707278 ] [0.71524936 0.40530797 0.53643702 0.19073316] [0.71171214 0.35002236 0.57170319 0.21001342] [0.70779525 0.31850786 0.60162596 0.1887454 ] [0.73659895 0.33811099 0.56754345 0.14490471] [0.72366005 0.32162669 0.58582004 0.17230001] [0.72634846 0.38046824 0.54187901 0.18446945] [0.73081412 0.34743622 0.56308629 0.16772783] [0.75519285 0.33928954 0.53629637 0.16417236] [0.75384916 0.31524601 0.54825394 0.17818253] [0.72155725 0.32308533 0.56001458 0.24769876] [0.70631892 0.37838513 0.5675777 0.18919257] [0.71529453 0.31790868 0.59607878 0.17882363] [0.73260391 0.36029701 0.55245541 0.1681386 ] [0.70558934 0.32722984 0.58287815 0.23519645] [0.69299099 0.34199555 0.60299216 0.19799743] [0.73350949 0.35452959 0.55013212 0.18337737] [0.73337886 0.32948905 0.54206264 0.24445962] [0.74714194 0.33960997 0.54337595 0.17659719] [0.71576546 0.30196356 0.59274328 0.21249287] [0.69589887 0.34794944 0.57629125 0.25008866] [0.69333409 0.38518561 0.57777841 0.1925928 ] [0.69595601 0.3427843 0.59208198 0.21813547] [0.70610474 0.3258945 0.59747324 0.1955367 ] [0.76923077 0.30769231 0.53846154 0.15384615] [0.73923462 0.37588201 0.52623481 0.187941 ]] self.support_vector_labels: [ 1 1 -1 -1 1 1 1 1 1 -1 -1 1 -1 -1 1 -1 -1 -1 -1 1 -1 1 -1 1 1 -1 1 -1 1 1 -1 1 1 -1 -1]
最后一步:
# Calculate intercept with first support vector self.intercept = self.support_vector_labels[0] for i in range(len(self.lagr_multipliers)): self.intercept -= self.lagr_multipliers[i] * self.support_vector_labels[ i] * self.kernel(self.support_vectors[i], self.support_vectors[0])
需要好多数学知识以及矩阵之间的运算,还是有很多不理解其这么计算的原因,再慢慢摸索了。
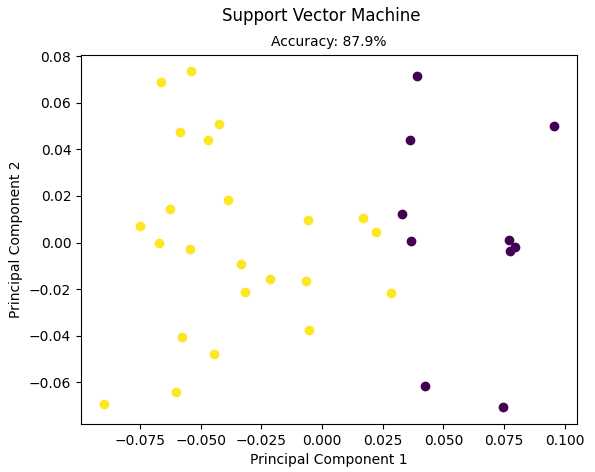
结果:
Accuracy: 0.8787878787878788
标签:title and 探索 target 特征 info rgs 指定 dimens
原文地址:https://www.cnblogs.com/xiximayou/p/12821256.html