标签:表数据 路线图 技术栈 过程 identity tab 实例 结果 名称
原文:.net core 基于Dapper 的分库分表开源框架(core-data)
感觉很久没写文章了,最近也比较忙,写的相对比较少,抽空分享基于Dapper 的分库分表开源框架core-data的强大功能,更好的提高开发过程中的效率;
在数据库的数据日积月累的积累下,业务数据库中的单表数据想必也越来越大,大到百万、千万、甚至上亿级别的数据,这个时候就很有必要进行数据库读写分离、以及单表分多表进行存储,提高性能,但是呢很多人不知道怎么去分库分表,也没有现成的分库分表的成熟框架,故不知道怎么下手,又怕影响到业务;现在我给大家推荐core-data的分库分表开源框架。框架开源地址:https://github.com/overtly/core-data
这里先来回顾下我上一篇文章中的技术栈路线图,如下:
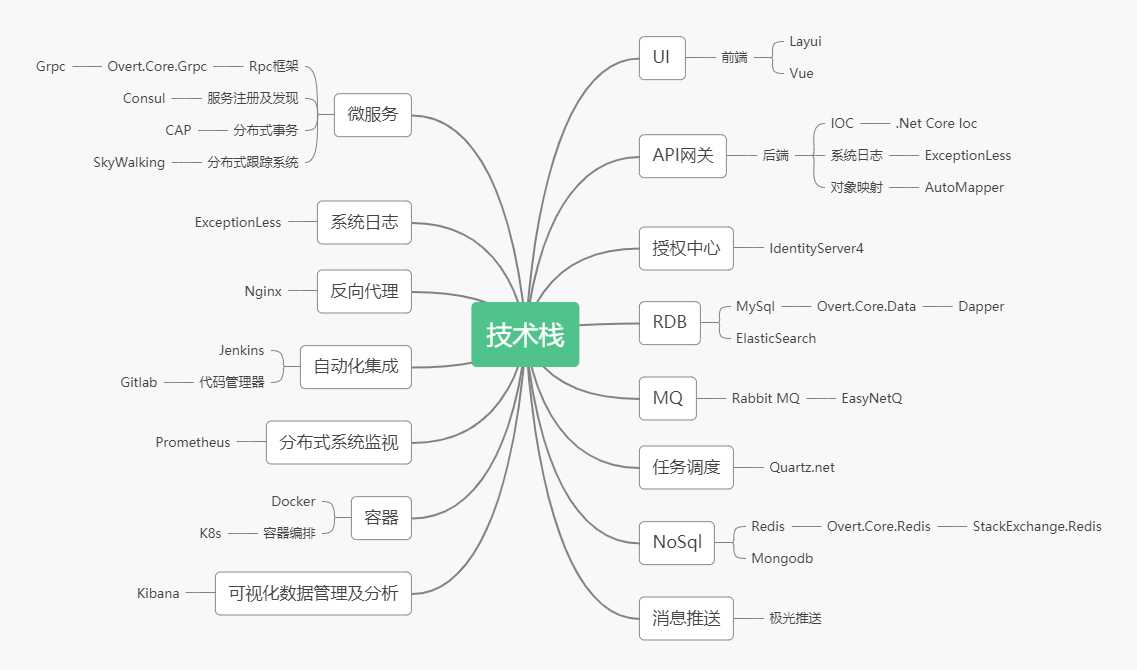
今天从这张技术栈图中来详细分享一切的基础数据库底层操作ORM。
上一篇文章.Net 微服务架构技术栈的那些事 中简单的介绍了core-data主要优势,如下:
这里都仅仅分享核心的内容代码,不把整个代码贴出来,有需要完整Demo源代码请访问 https://github.com/a312586670/NetCoreDemo
在我的解决方案的项目中 引用overt.core.data nuget包,如下图:
创建用户实体代码如下:
/// <summary>
/// 标注数据库对应的表名
/// </summary>
[Table("User")]
public class UserEntity
{
/// <summary>
/// 主键ID,标注自增ID
/// </summary>
[Key, DatabaseGenerated(DatabaseGeneratedOption.Identity)]
public int UserId { get; set; }
/// <summary>
/// 商户ID
/// </summary>
public int MerchantId { set; get; }
/// <summary>
/// 用户名
/// </summary>
public string UserName { get; set; }
/// <summary>
/// 真实姓名
/// </summary>
public string RealName { get; set; }
/// <summary>
/// 密码
/// </summary>
public string Password { get; set; }
/// <summary>
/// 添加时间
/// </summary>
public DateTime AddTime { get; set; }
}
代码中通过[Table("User")] 来和数据库表进行映射关联;
通过[Key, DatabaseGenerated(DatabaseGeneratedOption.Identity)] 标注自增主键.
从单表模式改成分表模式,并且按照商户的模式进行分表,代码实体代码改造如下:
/// <summary>
/// 标注数据库对于的表名
/// </summary>
[Table("User")]
public class UserEntity
{
/// <summary>
/// 主键ID,标注自增ID
/// </summary>
[Key, DatabaseGenerated(DatabaseGeneratedOption.Identity)]
public int UserId { get; set; }
/// <summary>
/// 商户ID
/// </summary>
[Submeter(Bit =2)]
public int MerchantId { set; get; }
/// <summary>
/// 用户名
/// </summary>
public string UserName { get; set; }
/// <summary>
/// 真实姓名
/// </summary>
public string RealName { get; set; }
/// <summary>
/// 密码
/// </summary>
public string Password { get; set; }
/// <summary>
/// 添加时间
/// </summary>
public DateTime AddTime { get; set; }
}
代码中 MerchantId 字段上添加了[Submeter(Bit =2)]标注,并且指定了Bit=2,将会分成根据MerchantId字段取二进制进行md5 hash 取前两位分成256张表
分表模式可以通过在字段上标注Submeter属性,我们先来看看框架对于这个标注的源代码,源代码如下:
/// <summary>
/// 分表标识
/// </summary>
public class SubmeterAttribute : Attribute
{
/// <summary>
/// 16进制位数
/// 1 16
/// 2 256
/// 3 4096
/// ...
/// </summary>
public int Bit { get; set; }
}
开源框架中其中一个获得分表的表名称的扩展方法,仅仅只贴了一个扩展方法,有兴趣的可以下载开源框架进行源码阅读。
/// <summary>
/// 获取表名
/// </summary>
/// <param name="entity">实体实例</param>
/// <param name="tableNameFunc"></param>
/// <returns></returns>
public static string GetTableName<TEntity>(this TEntity entity, Func<string> tableNameFunc = null) where TEntity : class, new()
{
if (tableNameFunc != null)
return tableNameFunc.Invoke();
var t = typeof(TEntity);
var mTableName = t.GetMainTableName();
var propertyInfo = t.GetProperty<SubmeterAttribute>();
if (propertyInfo == null) // 代表没有分表特性
return mTableName;
// 获取分表
var suffix = propertyInfo.GetSuffix(entity);
return $"{mTableName}_{suffix}";
}
/// <summary>
/// 获取后缀(默认根据SubmeterAttribute 标注的位数进行Md5 hash 进行分表)
/// </summary>
/// <param name="val"></param>
/// <param name="bit"></param>
/// <returns></returns>
internal static string GetSuffix(string val, int bit = 2)
{
if (string.IsNullOrEmpty(val))
throw new ArgumentNullException($"分表数据为空");
if (bit <= 0)
throw new ArgumentOutOfRangeException("length", "length必须是大于零的值。");
var result = Encoding.Default.GetBytes(val.ToString()); //tbPass为输入密码的文本框
var md5Provider = new MD5CryptoServiceProvider();
var output = md5Provider.ComputeHash(result);
var hash = BitConverter.ToString(output).Replace("-", ""); //tbMd5pass为输出加密文本
var suffix = hash.Substring(0, bit).ToUpper();
return suffix;
}
源代码中通过SubmeterAttribute 特性进行对字段进行标注分表,可以传对应的bit参数进行框架默认的分表策略进行分表,但是很多情况下我们需要自定义分表策略,那我们应该怎么去自定义分表策略呢?我们先等一下来实践自定义分表策略,先来创建用户的Repository,代码如下
IUserRepository:
public interface IUserRepository : IBaseRepository<UserEntity>
{
}
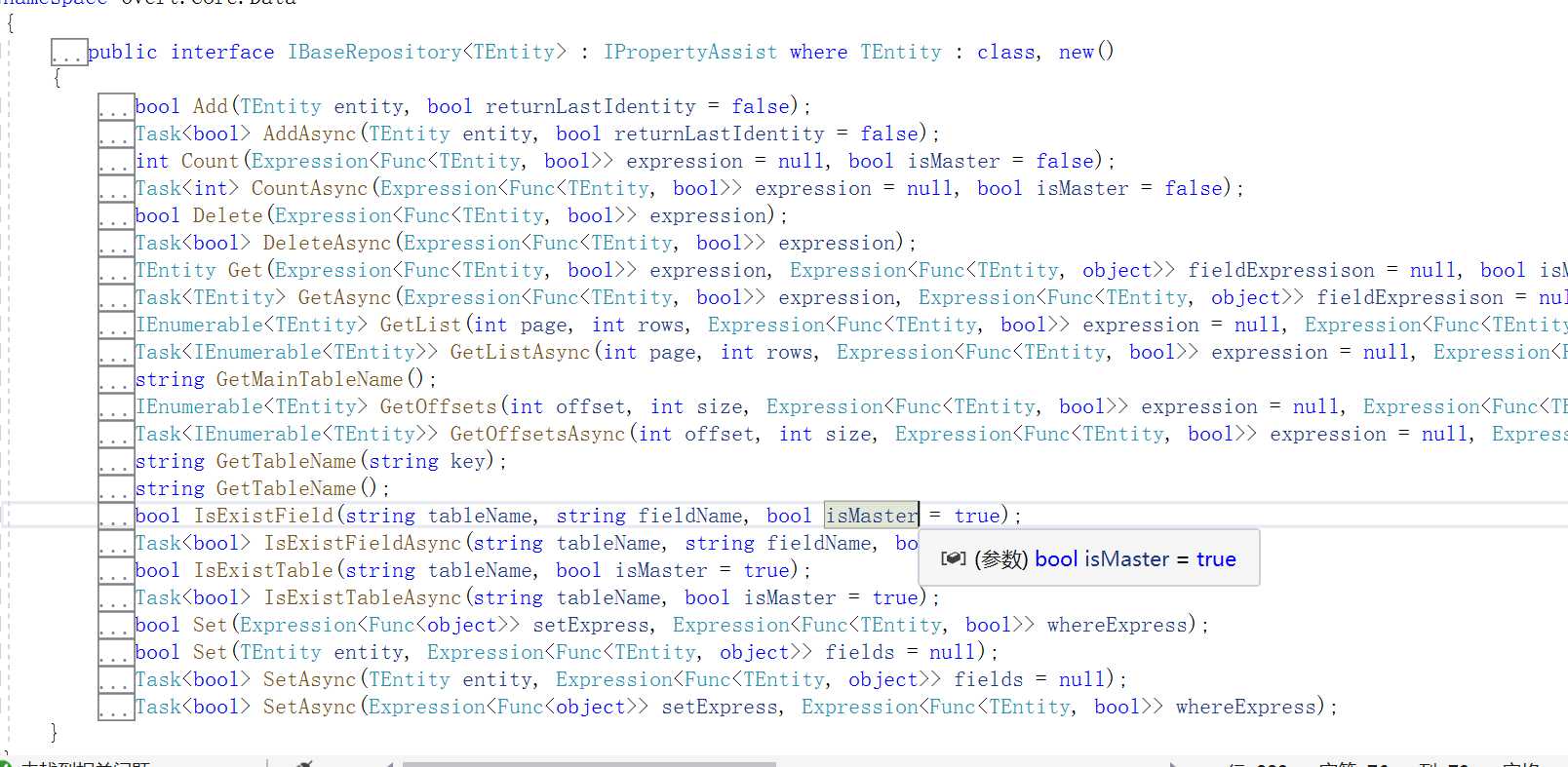
需要继承IBaseRepository<T>的接口,该接口默认实现了基本的方法,开源框架中IBaseRepository<T>代码方法如下图:
创建完IUserRepository接口后,我们来创建它的实现UserRepository,代码如下:
public class UserRepository : BaseRepository<UserEntity>, IUserRepository
{
public UserRepository(IConfiguration configuration)
: base(configuration, "user")
{
}
}
从代码中UserRepository类继承了BaseRepository<T>类,我们来看看这个abstract类的基本结构,如下图:
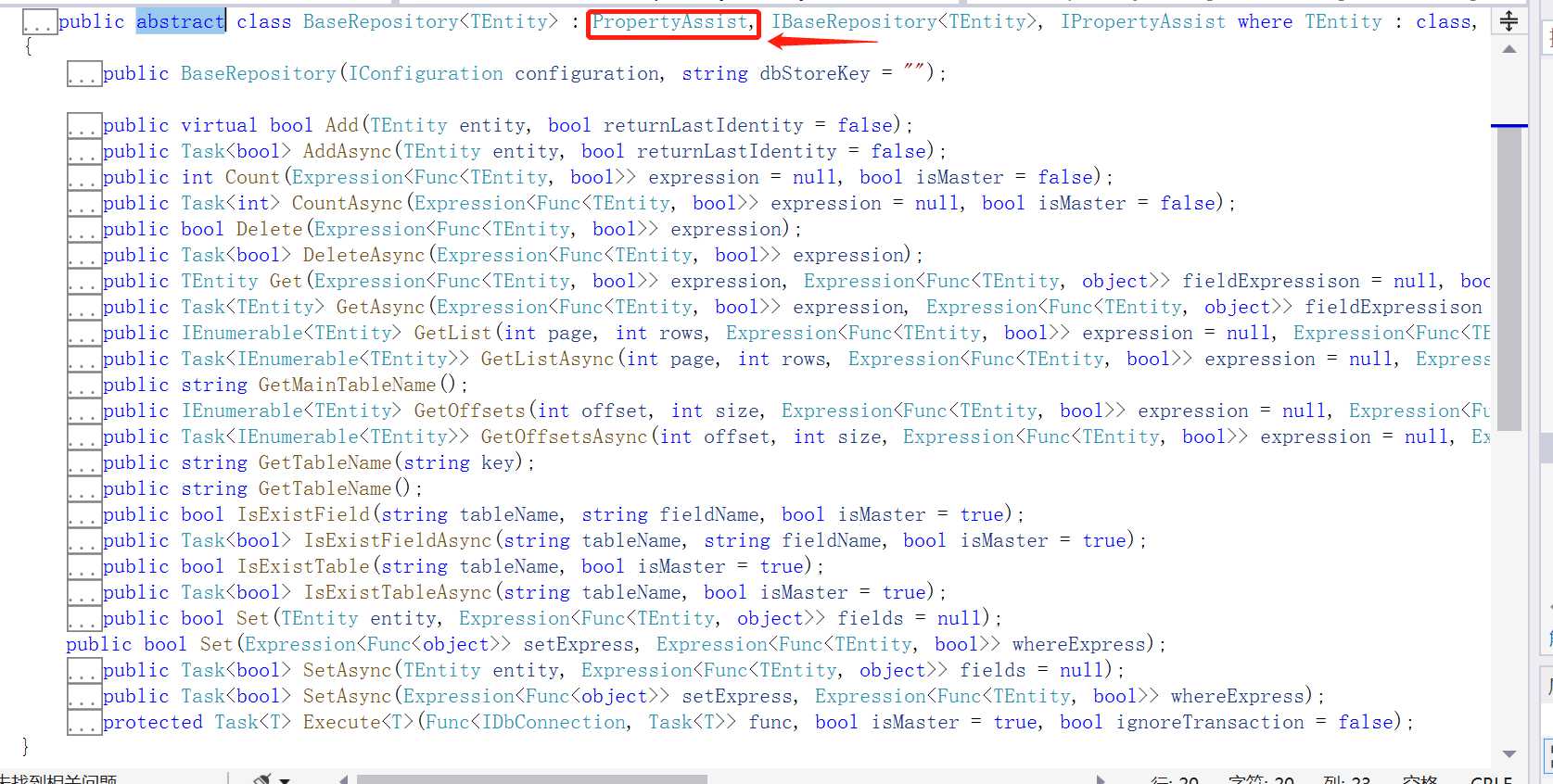
开源框架中BaseRepository<T>抽象类继承了PropertyAssist类,我们再来看看它的有哪些方法,如下图:
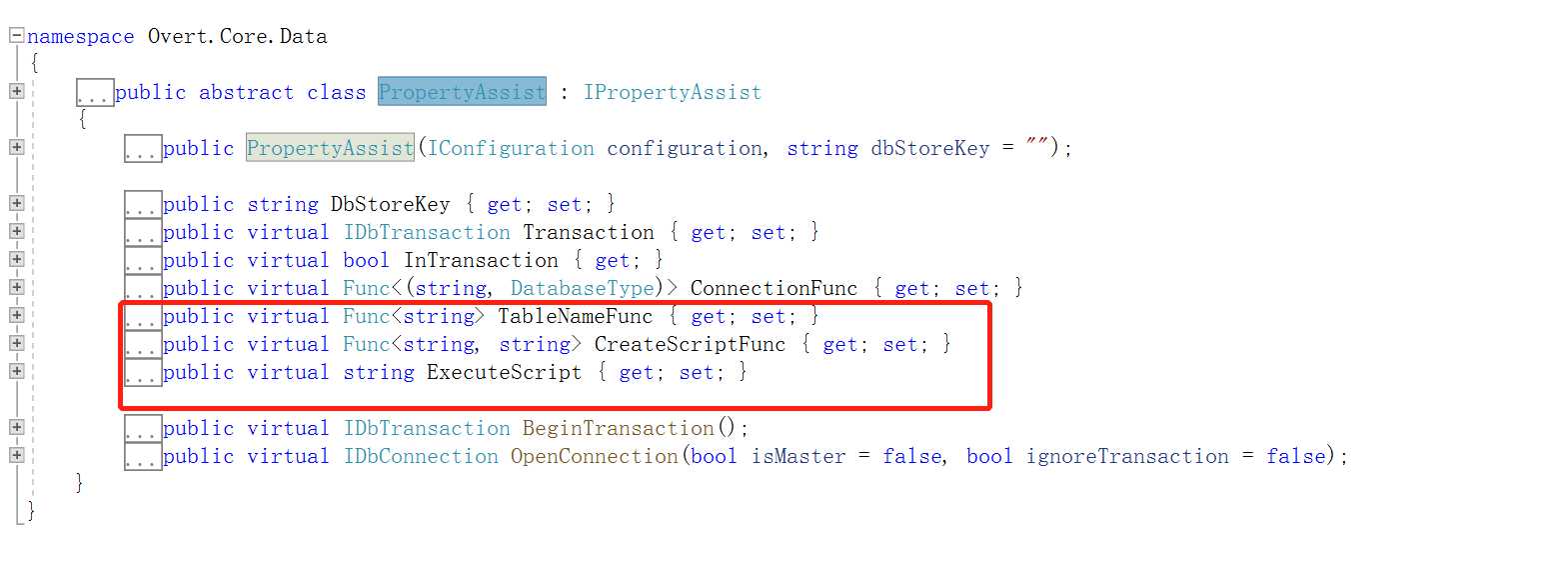
从图中可以看到定义了一系列的virtual方法,那既然是virtual方法我们就可以进行重写
CreateScriptFunc:自动创建脚本数据表方法TableNameFunc:可以进行自定义分表策略我们来实现上面提出的自定义分表策略问题(根据商户Id来进行分表,并且自动把不存在的表进行初始化创建),代码改造如下:
IUserRepository:
public interface IUserRepository : IBaseRepository<UserEntity>
{
int MerchantId { set; get; }
}
UserRepository 代码改造如下:
public class UserRepository : BaseRepository<UserEntity>, IUserRepository
{
public UserRepository(IConfiguration configuration)
: base(configuration, "user")
{
}
/// <summary>
/// 用于根据商户ID来进行分表
/// </summary>
public int MerchantId { set; get; }
//自定义分表策略
public override Func<string> TableNameFunc => () =>
{
var tableName = $"{GetMainTableName()}_{MerchantId}";
return tableName;
};
//自动创建分表的脚本
public override Func<string, string> CreateScriptFunc => (tableName) =>
{
//MySql
return "CREATE TABLE `" + tableName + "` (" +
" `UserId` int(11) NOT NULL AUTO_INCREMENT," +
" `UserName` varchar(200) DEFAULT NULL," +
" `Password` varchar(200) DEFAULT NULL," +
" `RealName` varchar(200) DEFAULT NULL," +
" `AddTime` datetime DEFAULT NULL," +
" `MerchantId` int(11) NOT NULL," +
" PRIMARY KEY(`UserId`)" +
") ENGINE = InnoDB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8mb4; ";
};
}
我们再来看看开源框架的基类代码结构截图,如下:
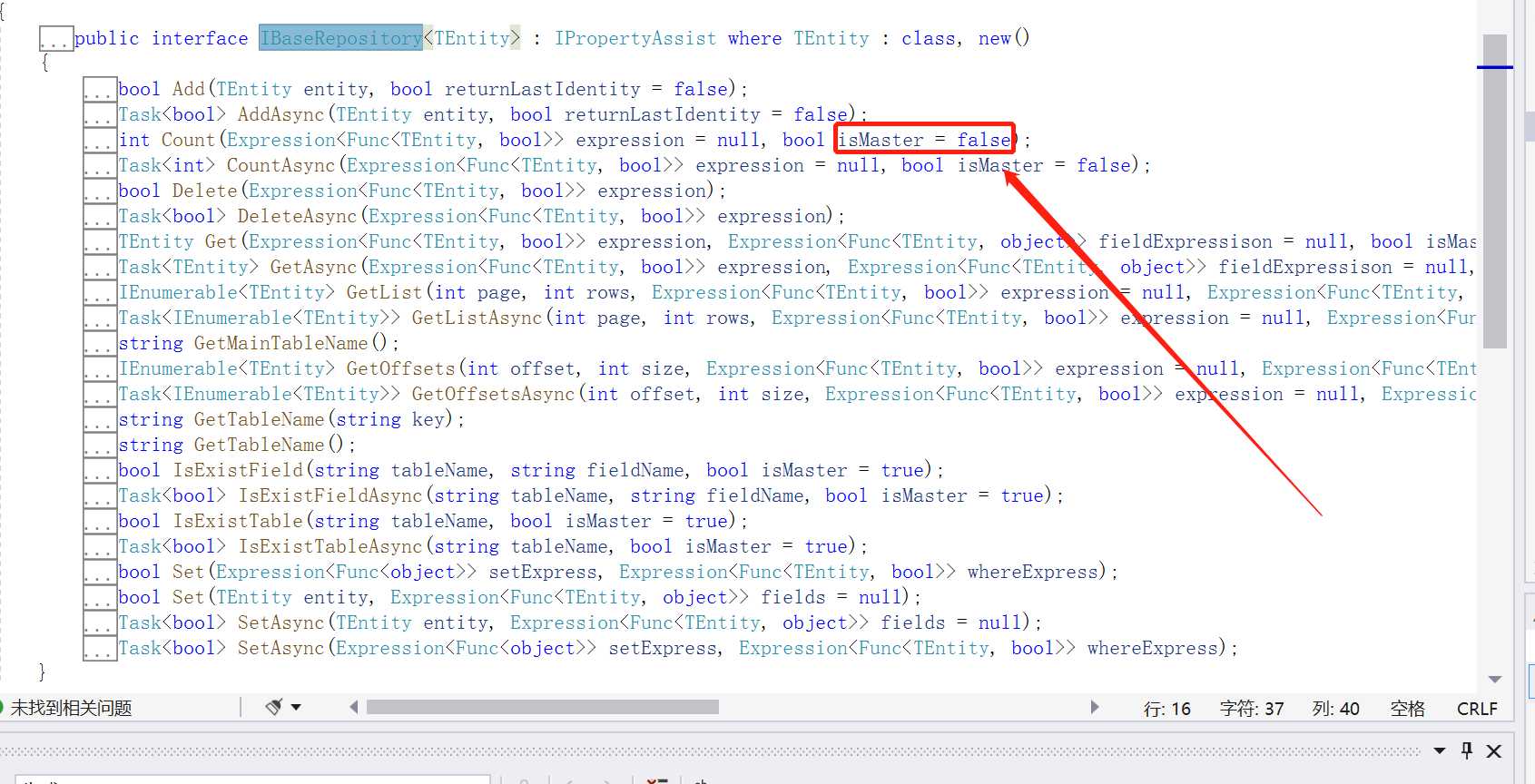
对于查询的基本常用的方法都有一个isMaster=false的参数,该参数就是用于是否读取主库,用于基本的主从数据库的分离,也就是读写分离,那改怎么配置读写分离数据库呢
链接字符串如下图:

分别指定了主从数据库的链接字符串.
我们来分析源代码,核心框架源代码如下:
/// <summary>
/// 连接配置信息获取
/// 1. master / secondary
/// 2. xx.master / xx.secondary
/// </summary>
public class DataSettings
{
#region Static Private Members
static readonly string _connNmeOfMaster = "master";
static readonly string _connNameOfSecondary = "secondary";
static readonly string _connNameOfPoint = ".";
static string _connNameOfPrefix = "";
#endregion
#region Private Member
/// <summary>
/// 主库
/// </summary>
private string Master
{
get { return $"{_connNameOfPrefix}{_connNmeOfMaster}"; }
}
/// <summary>
/// 从库
/// </summary>
private string Secondary
{
get
{
return $"{_connNameOfPrefix}{_connNameOfSecondary}";
}
}
#endregion
/// <summary>
/// 获取链接名称
/// </summary>
/// <param name="isMaster"></param>
/// <param name="store">不能包含点</param>
/// <returns></returns>
private string Key(bool isMaster = false, string store = "")
{
_connNameOfPrefix = string.IsNullOrEmpty(store) ? "" : $"{store}{_connNameOfPoint}";
var connName = string.Empty;
if (isMaster)
connName = Master;
else
connName = Secondary;
return connName;
}
}
代码中根据isMaster 参数来进行读写数据库链接参数的获取,以达到读写分离的功能,同时还支持前缀的配置支持,也开源自由配置多个数据库进行读取,只需要构造函数中获取配置即可。
上面的分表Demo 单元测试运行后的结果例子如下图:

已经按照MerchantId 字段进行分表
到这里用户表已经根据商户ID进行分表存储了,这样就做到了读写分离及自定义分表策略存储数据,core-data 开源框架还支持更多的强大功能,实现了一系列的基础CRUD的方法,不用写任何的sql语句,Where表达式的支持,同时可以自定义复杂的sql语句,更多请访问框架开源地址:https://github.com/overtly/core-data.
完整的Demo 代码 已经放在github上,Demo代码结构图如下:
地址:https://github.com/a312586670/NetCoreDemo
.net core 基于Dapper 的分库分表开源框架(core-data)
标签:表数据 路线图 技术栈 过程 identity tab 实例 结果 名称
原文地址:https://www.cnblogs.com/lonelyxmas/p/12833870.html