标签:com 频繁 check 磁盘 机制 而不是 不可 完整 优化参数
一、checkpoint检查点为什么产生因此永远不刷页写日志有两个条件:
缓冲池可以缓冲所有的数据
重做日志可以无限增大
显然以上条件后续无法满足,几个T的数据库,疯狂增长的日志。此时就需要一个完整的方案机制,去满足可行性条件,然后进行刷新。
?
二、checkpoint检查点解决什么
缩短数据库的恢复时间: checkpoint之前的已经刷盘,只需要恢复后边的重做日志
缓冲池不够用时,将脏页刷新到磁盘:同样缓冲池不够用的时候,也需要更新脏页到磁盘。
重做日志不可用时,刷新脏页:重做日志是组,循环使用,如果循环之前还需要用到之前的日志。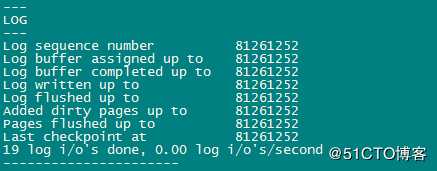
执行show engine innodb status \G;
Warnings:生产上这个checkpoint和flushed up 的pos经常不一致。
?
三、checkpoint检查点优化参数设置
两种类型:
Sharp Checkpoint 数据库关闭时刷新所有的脏页到磁盘
Fuzzy Checkpoint 只刷新一部分脏页到磁盘,而不是全部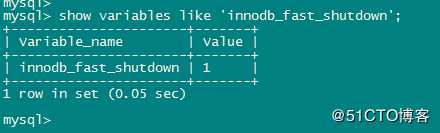
这个参数就是默认的工作方式。Sharp Checkpoint。
针对Fuzzy Checkpoint,以下几种情况会用到:
master thread checkpoint 差不多每秒或者每十秒刷新部分脏页到磁盘,异步,不影响查询操作。
flush_lru_list checkpoint 标签:com 频繁 check 磁盘 机制 而不是 不可 完整 优化参数
原文地址:https://blog.51cto.com/aklaus/2492933