标签:read oca 列表 默认 unicode 不用 other 解压 字段

所有从文件里读出来的内容都是字符串;
1、read(),每次读取整个文件,返回为一个字符串,可以read(size),size是字节
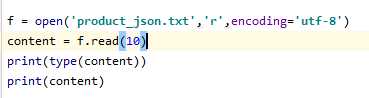
2、readlines()也是读取整个文件,返回一个列表,每行为列表的一个元素, 每行的换行符也读出来‘\n’


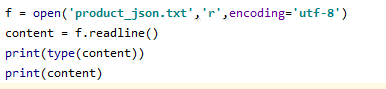
3、readline(),每次读取一行,返回的也是一个字符串,
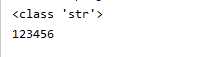
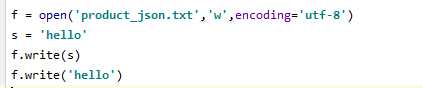
4、write(),和read(),readline()对应,是将字符串写入到文件中
5、writelines(),和readlines(),方法对应,接收一个字符串列表作为参数,写入到文件中,换行符不会自动加入,需要显式的加入换行符

with open() as f , 写法,不用关闭文件;
列表生成式;
l1 = [ i for i in range(10)]
l2 = [str(i) for i in range(65,91)]
l3 = [i*i for i in range(97,123)]
__init__.py中变量:__all__关联了一个模块列表,当执行from xx import *时,就会导入列表中的模块,__all__ = [‘t1‘, ‘t2‘]
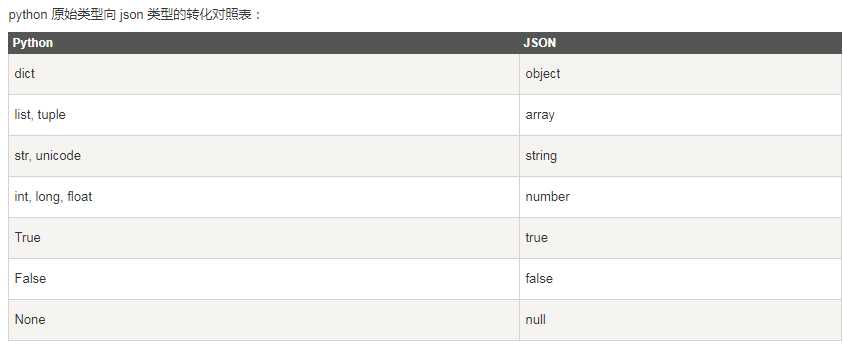
json.dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)
import json
data1 = [ { ‘key1‘ : ‘球鞋‘, ‘key2‘ : ‘vanss‘, ‘key3‘ : 665 } ]
data2 = { ‘key1‘ : ‘球鞋‘, ‘key2‘ : ‘vanss‘, ‘key3‘ : 665 }
data3 = ‘abcdef‘
data4 = False
data5 = 123456.3333
json1 = json.dumps(data1,indent=2,ensure_ascii=False)
json2 = json.dumps(data2,indent=2,ensure_ascii=False)
json3 = json.dumps(data3)
json4 = json.dumps(data4)
json5 = json.dumps(data5)

json.loads 用于解码 JSON 数据。该函数返回 Python 字段的数据类型; json对象格式需要转化为str
import json
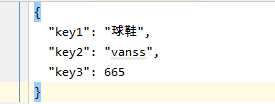
json1 = ‘{"key1": "球鞋", "key2": "vanss", "key3": 665}‘
data = json.loads(json1)
print(data)
{‘key1‘: ‘球鞋‘, ‘key2‘: ‘vanss‘, ‘key3‘: 665}
将一个python值转换成json格式并存入指定文件,用法如下:
import json
json1 = {"key1": "球鞋", "key2": "vanss", "key3": 665}
with open(‘tjs.txt‘,‘w‘) as f:
json.dump(json1,f,ensure_ascii=False,indent=2)
将一个指定json格式文件转换成python值。比如把前一个例子中data.json文件数据还原成dict格式数据:
import json
with open(‘tjs.txt‘,‘r‘) as f:
data = json.load(f)
print(type(data))
print(data)

标签:read oca 列表 默认 unicode 不用 other 解压 字段
原文地址:https://www.cnblogs.com/whcp855/p/12840914.html