标签:相对 简单 ide adl 快排 div 思想 oid 情况下
快速排序(QuickSort)
划分的关键是要求出基准记录所在的位置pivotpos,编程时候的关键点
快速排序:
既然能把冒泡KO掉,马上就激起我们的兴趣,tnd快排咋这么快,一定要好好研究一下。
首先上图: 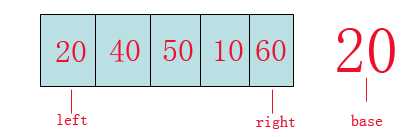
从图中我们可以看到:
left指针,right指针,base参照数。
其实思想是蛮简单的,就是通过第一遍的遍历(让left和right指针重合)来找到数组的切割点。
第一步:首先我们从数组的left位置取出该数(20)作为基准(base)参照物。
第二步:从数组的right位置向前找,一直找到比(base)小的数,如果找到,将此数赋给left位置(也就是将10赋给20),此时数组为:10,40,50,10,60, left和right指针分别为前后的10。
第三步:从数组的left位置向后找,一直找到比(base)大的数,如果找到,将此数赋给right的位置(也就是40赋给10),此时数组为:10,40,50,40,60,left和right指针分别为前后的40。
第四步:重复“第二,第三“步骤,直到left和right指针重合,最后将(base)插入到40的位置,此时数组值为: 10,20,50,40,60,至此完成一次排序。
第五步:此时20已经潜入到数组的内部,20的左侧一组数都比20小,20的右侧作为一组数都比20大,以20为切入点对左右两边数按照"第一,第二,第三,第四"步骤进行,最终快排大功告成。
快速排序具有最好的平均性能(average behavior),但最坏性能(worst case behavior)和插入排序相同,也是O(n^2)。比如一个序列5,4,3,2,1,要排为1,2,3,4,5。按照快速排序方法,每次只会有一个数据进入正确顺序,不能把数据分成大小相当的两份,很明显,排序的过程就成了一个歪脖子树,树的深度为n,那时间复杂度就成了O(n^2)。尽管如此,需要排序的情况几乎都是乱序的,自然性能就保证了。据书上的测试图来看,在数据量小于20的时候,插入排序具有最好的性能。当大于20时,快速排序具有最好的性能,归并(merge sort)和堆排序(heap sort)也望尘莫及,尽管复杂度都为nlog2(n)。
1、算法思想
快速排序是C.R.A.Hoare于1962年提出的一种划分交换排序。它采用了一种分治的策略,通常称其为分治法(Divide-and-ConquerMethod)。
(1) 分治法的基本思想
分治法的基本思想是:将原问题分解为若干个规模更小但结构与原问题相似的子问题。递归地解这些子问题,然后将这些子问题的解组合为原问题的解。
(2)快速排序的基本思想
设当前待排序的无序区为R[low..high],利用分治法可将快速排序的基本思想描述为:
①分解:
在R[low..high]中任选一个记录作为基准(Pivot),以此基准将当前无序区划分为左、右两个较小的子区间R[low..pivotpos-1)和R[pivotpos+1..high],并使左边子区间中所有记录的关键字均小于等于基准记录(不妨记为pivot)的关键字pivot.key,右边的子区间中所有记录的关键字均大于等于pivot.key,而基准记录pivot则位于正确的位置(pivotpos)上,它无须参加后续的排序。
注意:
划分的关键是要求出基准记录所在的位置pivotpos。划分的结果可以简单地表示为(注意pivot=R[pivotpos]):
R[low..pivotpos-1].keys≤R[pivotpos].key≤R[pivotpos+1..high].keys
其中low≤pivotpos≤high。
②求解:
通过递归调用快速排序对左、右子区间R[low..pivotpos-1]和R[pivotpos+1..high]快速排序。③组合:
因为当"求解"步骤中的两个递归调用结束时,其左、右两个子区间已有序。对快速排序而言,"组合"步骤无须做什么,可看作是空操作。
2、快速排序算法QuickSort
void QuickSort(SeqList R,int low,int high)
{ //对R[low..high]快速排序
int pivotpos; //划分后的基准记录的位置
if(low<high){//仅当区间长度大于1时才须排序
pivotpos=Partition(R,low,high); //对R[low..high]做划分
QuickSort(R,low,pivotpos-1); //对左区间递归排序
QuickSort(R,pivotpos+1,high); //对右区间递归排序
}
} //QuickSort
注意:
为排序整个文件,只须调用QuickSort(R,1,n)即可完成对R[l..n]的排序。
#include<stdio.h> void quickSort(int a[],int left,int right) { int i=left; int j=right; int temp=a[left]; if(left>=right) return; while(i!=j) { while(i<j&&a[j]>=temp) j--; if(j>i) a[i]=a[j];//a[i]已经赋值给temp,所以直接将a[j]赋值给a[i],赋值完之后a[j],有空位 while(i<j&&a[i]<=temp) i++; if(i<j) a[j]=a[i]; } a[i]=temp;//把基准插入,此时i与j已经相等R[low..pivotpos-1].keys≤R[pivotpos].key≤R[pivotpos+1..high].keys quickSort(a,left,i-1);/*递归左边*/ quickSort(a,i+1,right);/*递归右边*/ } int main() { int a[9]={8,2,6,12,1,9,5,5,10}; int i; quickSort(a,0,8);/*排好序的结果*/ for(i=0;i<8;i++) printf("%4d",a[i]); getchar(); return 0; }
#include<stdio.h> int partition(int a[],int left,int right) { int i=left; int j=right; int temp=a[i]; while(i<j) { while(i<j && a[j]>=temp) j--; if(i<j) a[i]=a[j]; while(i<j && a[i]<=temp) i++; if(i<j) a[j]=a[i]; } a[i]=temp; return i; } void quickSort(int a[],int left,int right) { int dp; if(left<right) { dp=partition(a,left,right); quickSort(a,left,dp-1); quickSort(a,dp+1,right); } } int main() { int a[9]={5,4,9,1,7,6,2,3,8}; quickSort(a,0,8); for(int i=0;i<9;i++) { printf("%d ",a[i]); } return 0; }
快速排序的最坏情况基于每次划分对主元的选择。基本的快速排序选取第一个元素作为主元。这样在数组已经有序的情况下,每次划分将得到最坏的结果。一种比较常见的优化方法是随机化算法,即随机选取一个元素作为主元。这种情况下虽然最坏情况仍然是O(n^2),但最坏情况不再依赖于输入数据,而是由于随机函数取值不佳。实际上,随机化快速排序得到理论最坏情况的可能性仅为1/(2^n)。所以随机化快速排序可以对于绝大多数输入数据达到O(nlogn)的期望时间复杂度。一位前辈做出了一个精辟的总结:“随机化快速排序可以满足一个人一辈子的人品需求。”
随机化快速排序的唯一缺点在于,一旦输入数据中有很多的相同数据,随机化的效果将直接减弱。对于极限情况,即对于n个相同的数排序,随机化快速排序的时间复杂度将毫无疑问的降低到O(n^2)。解决方法是用一种方法进行扫描,使没有交换的情况下主元保留在原位置。
无论适用哪一种方法来选择pivot,由于我们不知道各个元素间的相对大小关系(若知道就已经排好序了),所以我们无法确定pivot的选择对划分造成的影响。因此对各种pivot选择法而言,最坏情况和最好情况都是相同的。我们从直觉上可以判断出最坏情况发生在每次划分过程产生的两个区间分别包含n-1个元素和1个元素的时候(设输入的表有n个元素)。下面我们暂时认为该猜测正确,在后文我们再详细证明该猜测。对于有n个元素的表L[p..r],由于函数Partition的计算时间为θ(n),所以快速排序在序坏情况下的复杂性有递归式如下T(1)=θ(1),T(n)=T(n-1)+T(1)+θ(n) (1)用迭代法可以解出上式的解为T(n)=θ(n2)。这个最坏情况运行时间与插入排序是一样的。
如果每次划分过程产生的区间大小都为n/2,则快速排序法运行就快得多了。这时有T(n)=2T(n/2)+θ(n),T(1)=θ(1) (3)
标签:相对 简单 ide adl 快排 div 思想 oid 情况下
原文地址:https://www.cnblogs.com/cxy2020/p/12863545.html