标签:参数 div ima png xmx htm 倾斜 开启 负载均衡
#增加reducer任务数量(拉取数量分流) set mapred.reduce.tasks=20; #在同一个sql中的不同的job是否可以同时运行,默认为false set hive.exec.parallel=true; #增加同一个sql允许并行任务的最大线程数 set hive.exec.parallel.thread.number=8; #设置reducer内存大小 set mapreduce.reduce.memory.mb=4096; set mapreduce.reduce.java.opts=-Xmx3584m; -- -Xmx 设置堆的最大空间大小。
#mapjoin相关设置,小表加载到内存,无reduce
set hive.mapjoin.smalltable.filesize=25000000; -- 刷入内存表的大小(字节)。注意:设置太大也不会校验,所以要根据自己的数据集调整
set hive.auto.convert.join = true; -- 开启mapjoin,默认false
set hive.mapjoin.followby.gby.localtask.max.memory.usage=0.6 ;--map join做group by操作时,可使用多大的内存来存储数据。若数据太大则不会保存在内存里,默认0.55
set hive.mapjoin.localtask.max.memory.usage=0.90; -- 本地任务可以使用内存的百分比,默认值:0.90
-- 在设置成false时,可以手动的指定mapjoin /*+ MAPJOIN(c) */ 。-->c:放到内存中的表
select /*+ MAPJOIN(c) */ * from user_install_status u
inner join country_dict c
on u.country=c.code
-- 如果不是做innerjoin, 做left join 、right join
-- A left join B, 把B放到内存
-- A right join B, 把A放到内存
#设置执行引擎
set hive.execution.engine=mr; -- 执行MapReduce任务,也可以设置为spark
-- 设置内存大小
set mapreduce.reduce.memory.mb=8192; -- reduce 设置的是 Container 的内存上限,这个参数由 NodeManager 读取并进行控制,当 Container 的内存大小超过了这个参数值,NodeManager 会负责 kill 掉 Container
set mapreduce.reduce.java.opts=-Xmx6144m; -- reduce Java 程序可以使用的最大堆内存数,要小于 mapreduce.reduce.memory.mb
set mapreduce.map.memory.mb=8192; -- map申请内存大小
set mapreduce.map.java.opts=-Xmx6144m;
#动态分区设置,参考:https://www.cnblogs.com/cssdongl/p/6831884.html
set hive.exec.dynamic.partition=true; 是开启动态分区
set hive.exec.dynamic.partition.mode=nonstrict; 这个属性默认值是strict,就是要求分区字段必须有一个是静态的分区值,当前设置为nonstrict,那么可以全部动态分区
#其他
-- 开始负载均衡
set hive.groupby.skewindata=true
-- 开启map端combiner
set hive.map.aggr=true
参数调节:
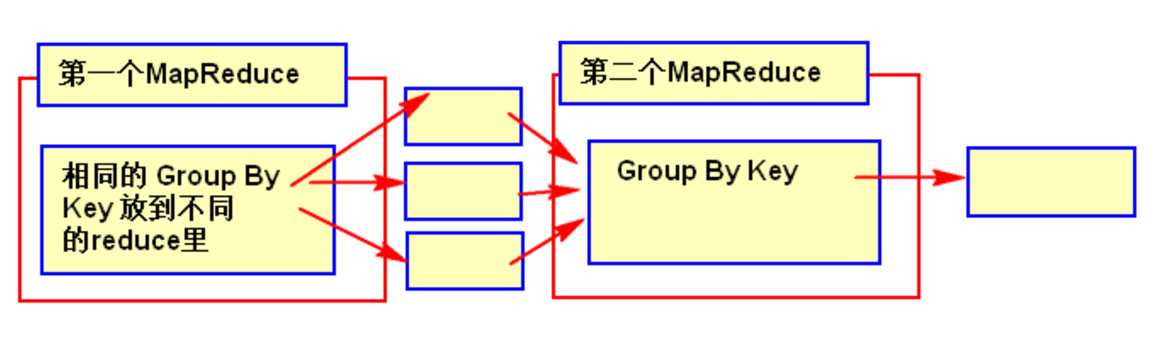
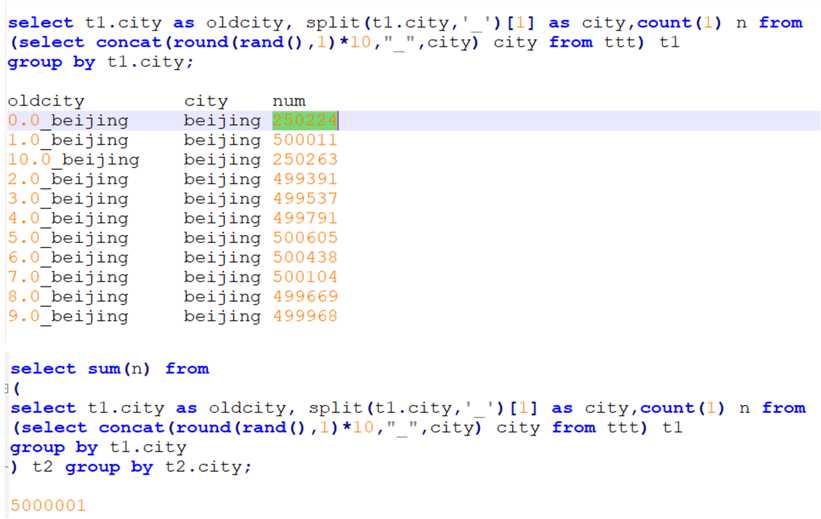
SQL 语句调节:
标签:参数 div ima png xmx htm 倾斜 开启 负载均衡
原文地址:https://www.cnblogs.com/xiexiandong/p/12865923.html