标签:alt 保存 tno $0 --nodeps border 部分 limits install
修改计算机名
hostnamectl set-hostname hadoop1
文件操作
touch test.txt 创建文件
echo 内容 > test.txt 覆盖内容到文件
echo 内容 >> test.txt 追加内容到文件
Jps 通过jps指令查找应用程序进程号PID
ps -ef |grep 进程号 --查找应用程序日志位置
tail -f file 实时查看文件末尾
tail -f 100 file 实时查看文件末尾100行
tail file 查看文件末尾
nl 带行号输出内容
ln -s 目标目录 软链接地址 创建软链接
rm -rf 软链接地址 删除软连接
ln -snf 新目标目录 软链接地址 修改软连接
# history 查看已经执行过历史命令
wc -l test.txt 统计行数
wc -c test.txt 统计字节数
wc -w test.txt 统计单词数
cut 命令
cut test.txt -c 1 截取文档每行的第一个字符
cut test.txt -c 1,3 截取文档每行的第一个和第三个字符
cut test.txt -c 1-3 截取文档每行的第一个至第三个字符
cut test.txt -f 1 -d " " 将文档每行用“ ”空格进行分割,显示第一列
cut test.txt -f 1,3 -d " " 将文档每行用“ ”空格进行分割,显示第一列和第三列
cut test.txt -f 1,3 -d " " 将文档每行用“ ”空格进行分割,显示第一列至第三列
sort sort.txt 将内容按行排序
sort sort.txt -r 以相反的顺序来排序。
sort -u sort.txt 将内容去重
date命令
data -s 20:20:20 设置时间
w 用于显示目前登入系统的用户信息
uname -a 显示系统内核
cat /proc/cpuinfo 查看CPU信息
cat /proc/meminfo 查看内存信息
压缩解压命令
tar -xvf file.tar 解压.tar压缩文件
tar -zxvf file.tar.gz 解压 tar.gz压缩文件,同时可以解压 .tar
tar -cf file.tar file //创建包含file的压缩文件
gzip -d file.gz 解压 file.gz
权限命令
chmod 777 file 为所有用户添加 读、写、执行权限,三个数字分别表示User、Group、及Other的权限。
chmod -R 777 file 对目前目录下的所有文件与子目录进行相同的权限变更(即以递回的方式逐个变更)
数字详解:
r 读取权限为4,w 写权限为2,x执行权限为1
若要给予读、写、执行权限则:4+2+1=7
若要给予读、写权限则:4+2=6
若要给予读、执行权限则:4+1=5
chown hadoop:hadoop file 将file的用户和用户组都改成hadoop
chown -R hadoop:hadoop file 将file及file子文件的用户和用户组都改成hadoop
用户管理
cd /home 用户目录存储位置
useradd 用户名 添加新用户
password 用户名 为用户设置密码
userdel 用户名 删除用户但保存用户目录
userdel -r 用户名 删除用户及用户目录
usermod -g 更改的用户组 用户名 ; 修改用户组
设置普通用户拥有root权限
vim /etc/sudoers
在root ALL=(ALL) ALL 下面添加用户
例如 hadoop=(ALL) ALL
用户组管理
groupadd 组名 添加用户组
groupdel 组名; 删除用户组
groupmod -n 新组名 老组名;修改用户组
cat /etc/group ; 查看用户组
搜索查找命令
find / -name file; 从根目录开始向下查找file同名文件
find /opt -path "/opt/pdsh*" -prune -o -name "test*" -print;在 /pot中查找,并排除 /opt/pdsh* 目录查找
cat test.txt | grep a 显示所有包含a的行
cat test.txt | grep -v a 显示所有不包含a的行
ls | grep -n test 显示包含 test名称的文件及文件夹,并显示所在行数
which ll ; 查找ll命令所在目录
ps -ef | grep PID 查找某进程
ps aux|greo xxx //查看系统中所有进程
kill -9 PID 强制杀死进程
netstat -nlp |grep :22 //查找占用22端口的进程
netstat -anp |grep 进程号 ;//查看进程的网络信息
crontab 定时任务
crontab -e 编辑 crontab任务
crontab -l 列出crontab任务
rpm包
rpm -qa 列出所有安装了的rpm包
rpm -ivh 包名 ;安装rpm包
rpm -e 包名 ;删除包
rom -e --nodeps ;删除包,不检查依赖
nohup command >myout.file 2>&1 &
grep:
grep test a ;从a开头的文件中搜索test的行
grep test aa bb cc ;从aa bb cc 三个文件中搜索test的行
grep -r ;以递归的方式查找符合条件的文件,包括子目录的文件
grep -i pattern files :不区分大小写地搜索。默认情况区分大小写,
grep -l pattern files :只列出匹配的文件名,
grep -L pattern files :列出不匹配的文件名,
grep -w pattern files :只匹配整个单词,而不是字符串的一部分(如匹配’magic’,而不是’magical’),
grep -C number pattern files :匹配的上下文分别显示[number]行,
grep pattern1 | pattern2 files :显示匹配 pattern1 或 pattern2 的行,
例如:grep "abc\|xyz" testfile 表示过滤包含abc或xyz的行
grep pattern1 files | grep pattern2 :显示既匹配 pattern1 又匹配 pattern2 的行。
grep -n pattern files 即可显示行号信息
grep -c pattern files 即可查找总行数
这里还有些用于搜索的特殊符号:
\< 和 \> 分别标注单词的开始与结尾。
例如:
grep man * 会匹配 ‘Batman’、’manic’、’man’等,
grep ‘\<man’ * 匹配’manic’和’man’,但不是’Batman’,
grep ‘\<man\>’ 只匹配’man’,而不是’Batman’或’manic’等其他的字符串。
‘^’:指匹配的字符串在行首,
‘$’:指匹配的字符串在行尾,
vim相关使用方法
:[range]s/pattern/string/[c,e,g,i]
| range | 指的是範圍,1,7 指從第一行至第七行,1,$ 指從第一行至最後一行,也就是整篇文章,也可以 % 代表。還記得嗎? % 是目前編輯的文章,# 是前一次編輯的文章。 |
| pattern | 就是要被替換掉的字串,可以用 regexp 來表示。 |
| string | 將 pattern 由 string 所取代。 |
| c | confirm,每次替換前會詢問。 |
| e | 不顯示 error。 |
| g | globe,不詢問,整行替換。 |
| i | ignore 不分大小寫。 |
:n,$s/aa/bb/g 从第N行到最后一行所有的aa替换为bb
:s/aa/bb/g 将当前行所有aa替换为bb
sed 命令
sed 之后追加 -i 才会修改文件。不追加只输出在控制台中,不对文件进行修改
sed 2,3cnewtext 等同于 sed 2,3c\newtext 等同于 sed "2,3c newtext " test.txt 将第2-3行的内容取代成为newtext
sed 1anewtext test.txt 在第一行后添加newtext
sed 1inewtest test.txt 在第一行前添加 newtext,当前文本作为第一行
sed 1d test.txt 删除第一行
sed 1,3d test.txt 删除第一行至第三行
sed 2,$\d test.txt 删除第二行至最后一行
sed inewtext test.txt 在每一行上方添加newtext
sed 1s/a/newtext/ test.txt 将第一行的第一个a替换为newtext
sed 1s/a/newtext/g test.txt 将第一行所有的a替换为newtext
sed s/a/newtext/g test.txt 将所有的a替换为newtext
sed 1,2s/a/newtext/g test.txt 将第一行第二行的a替换为newtext
sed "\%测试%d" test.txt 删除包含测试的行
sed ‘/^$/d‘ test.txt 删除所有空行
sed -i "\$a \* softnofile 65536" /etc/security/limits.conf --在最后一行插入数据
awk ‘{print$1,$4}’ text.txt 将文本按照tab和空格进行分割,显示第一列和第四列
awk ‘length>4‘ log.txt 显示每行字符超过4的行
awk -F, ‘{print$1,$4}’ text.txt 将文本按照“,”进行分割,显示第一列和第四列
awk -F‘[ \t,]‘ ‘{print$1,$4}‘ log.txt 将文本按照 空格,逗号,tab 进行分割,显示第一列和第四列
awk -va=1 -F‘[ \t,]‘ ‘{print$1+a,$2a}‘ log.txt 定义变量a=1,将文本按照 空格,逗号,tab 进行分割,显示第一列和第四列,其中在第一列的值上面进行增加变量a的值,在第二列行拼接变量a的值
awk -f test.awk log.txt ,执行脚本文件 test.awk
awk ‘$1>10{print$1,$2}‘ log.txt,将文本按照tab和空格进行分割,查找第一列值大于10的行,显示第一和第二列
awk ‘$2 ~ /1/ {print $2,$4}‘ log.txt 将文本按照tab和空格进行分割,模糊查找第二列包含1的行
awk ‘BEGIN{printf" %4s %10s %20s\n","a","b","c";printf"-------------\n"}{printf"%4s %10s %20s\n",$1,$2,$3}‘ log.txt 格式化输出 第一二三列
| 变量 | 描述 |
|---|---|
| $n | 当前记录的第n个字段,字段间由FS分隔 |
| $0 | 完整的输入记录 |
| ARGC | 命令行参数的数目 |
| ARGIND | 命令行中当前文件的位置(从0开始算) |
| ARGV | 包含命令行参数的数组 |
| CONVFMT | 数字转换格式(默认值为%.6g)ENVIRON环境变量关联数组 |
| ERRNO | 最后一个系统错误的描述 |
| FIELDWIDTHS | 字段宽度列表(用空格键分隔) |
| FILENAME | 当前文件名 |
| FNR | 各文件分别计数的行号 |
| FS | 字段分隔符(默认是任何空格) |
| IGNORECASE | 如果为真,则进行忽略大小写的匹配 |
| NF | 一条记录的字段的数目 |
| NR | 已经读出的记录数,就是行号,从1开始 |
| OFMT | 数字的输出格式(默认值是%.6g) |
| OFS | 输出记录分隔符(输出换行符),输出时用指定的符号代替换行符 |
| ORS | 输出记录分隔符(默认值是一个换行符) |
| RLENGTH | 由match函数所匹配的字符串的长度 |
| RS | 记录分隔符(默认是一个换行符) |
| RSTART | 由match函数所匹配的字符串的第一个位置 |
| SUBSEP | 数组下标分隔符(默认值是/034) |
cat /proc/cpuinfo |grep "physical id"|sort |uniq|wc -l --查看CPU个数
cat /proc/cpuinfo |grep "processor"|wc -l --查看逻辑CPU个数,也就是线程数
cat /proc/cpuinfo --查看CPU所有信息
cat /proc/meminfo --查看内存信息
iostat -mx 2 --查看磁盘IO状态,参数中的2 为两秒更新一次,如果没有这个命令可以通过 yum install sysstat
df -h --查看磁盘空间
df -T --查看磁盘格式
lsblk 能够查看盘与分区以及ssd盘,用fdisk查看盘可能识别不到ssd
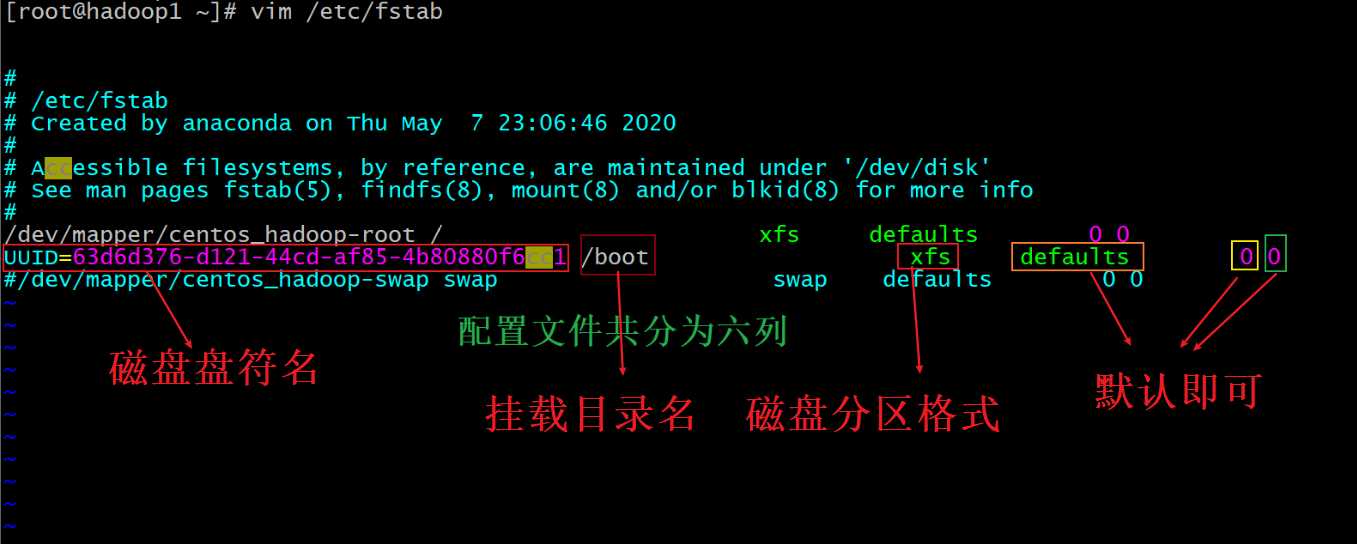
cat /etc/fstab 查看磁盘挂载信息,新加磁盘要手动永久挂在需要在这个配置文件里添加,6列。如果这个文件写错了,重启服务器正常模式下是启动不了的!!
第一列是盘符名,挂载目录名,磁盘格式,后面三列默认的 defaults,0,0 即可
标签:alt 保存 tno $0 --nodeps border 部分 limits install
原文地址:https://www.cnblogs.com/mrma/p/12844974.html