标签:存储 连接mysql 统计 max red mamicode pass 显示 语法
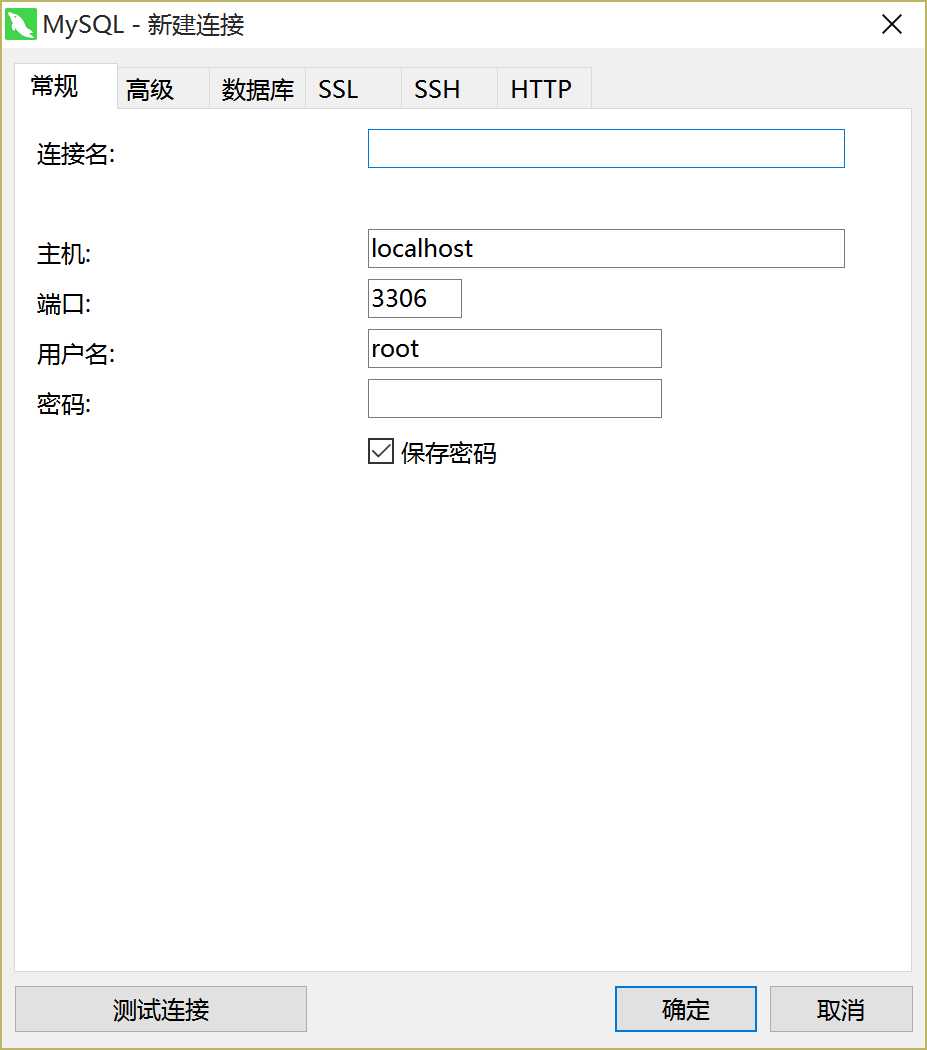
(1)?Connection Name(连接名):这个文本框,就是让你给此次连接起个昵称而已,因此随便写。
(2) hostname(主机名): 添加数据库服务端所在的主机IP
(3) port(端口号):MySQL的端口号,一般情况下都是默认的3306
(4) username(用户名):即你要使用哪个用户进行登陆数据库服务端。如,超级管理员root, 或者是其他普通用户。
(5) password(密码):你所使用的用户对应的密码
(6) default schema:表示你要连接MySQL里的哪个数据库(数据存储空间)。
# 向表t_users插入一条数据,并且给每一个字段进行赋值,小括号中的是字段对应的值。要保证顺序。
INSERT INTO t_users VALUES(‘lily‘, 21, ‘female‘, 172, 60);
INSERT INTO t_users VALUES(‘lucy‘, 21, ‘female‘, 171, 60);
# 向表t_users插入一条数据,并且对部分字段进行赋值
INSERT INTO t_users (uname, age, gender) VALUES(‘JimGreen‘, 22, ‘male‘);
# 向表t_users插入一条数据,并且对部分字段进行赋值,字段的顺序可以随意,但是要保证values后面的值要和前面的字段匹配
INSERT INTO t_users (age, gender, uname) VALUES(10, ‘male‘, ‘polly‘);
在进行数据的删除、修改、查询的时候,可以使用where对数据进行一个过滤。
= :相等比较(类似于java中的==)
!= <> : 表示不相等
< >= <= : 大小比较
BETWEEN...AND... : 在xxx和xxx之间
IN(set) :在括号中所有值之间取
IS NULL
AND、OR、NOT
# 删除数据
DELETE FROM t_student;
# 按照条件进行删除 WHERE
DELETE FROM t_student WHERE sname = ‘韦一笑‘;
# 删除掉表中所有的数据
TRUNCATE TABLE t_student;
DELETE 和 TRUNCATE
# 将所有的数据中的年龄都修改为60
UPDATE t_student SET sage = 60;
# 将姓名为‘张三丰‘的数据年龄改成60
UPDATE t_student SET sage = 60 WHERE sname=‘张三丰‘;
# 将姓名为‘谢逊‘的数据年龄改成50, java成绩修改成60
UPDATE t_student SET sage = 50, score_java = 60 WHERE sname = ‘谢逊‘;
# 将姓名为‘灭绝师太‘的数据mysql成绩在现有基础上加10
UPDATE t_student SET score_mysql = score_mysql / 10 where sname = ‘灭绝师太‘;
最简单的查询语句:
select...from....
一个完整的普通查询语句结构如下:
select [distinct].....from....[where....][group by .....][having.....][order by.....][limit.....]
在select语句中,可以对表或者是列起别名操作。在使用汉字作为列别名时,可以加单双引号,也可不加。表别名不能加单双引号。
select name 姓名, (year(now())-year(birth)) 年龄
from test1 t;
select e.empno 员工编号,e.ename,e.job,mgr ‘领导编号‘,hiredate,sal,comm,deptno from emp e;
作用:用于条件筛选或过滤
1)关系表达式: >,>=,<,<=,=,!=,<>
2)多条件连接符: and,or, [not] between ..and..
3)集合操作: [not] in (set),
>all(set), <all(set), >any(set), <any(set)
注意:mysql不支持简单的集合查询操作,但是支持子查询,是针对于all和any集合操作来说的。
4)模糊查询: like
_:占位符,表示匹配任意一个字符
%:表示匹配任意N个字符,大于等于0.
--查询工资大于1600的所有员工的编号,姓名,职位,工资
select empno,ename,job,sal from emp where sal>1600
--查询工资大于1600并且小于2500的所有员工的编号,姓名,职位,工资
select empno,ename,job,sal from emp where sal>1600 and sal<2500;
select empno,ename,job,sal from emp where sal between 1600 and 2500;
--查询10,20号部门的所有员工的信息。
select * from emp where deptno not in (10,20);
--查询不是10号部门中姓名第二个字符是m的员工信息。
select * from emp where deptno<>10 and ename like ‘_m%‘;
用于查询排序的,通常放置在一个查询语句的最后部分。
语法: order by colName [asc|desc] [,colName [asc|desc]]
asc:升序, 默认情况就是升序
desc:降序
--查询员工表中的所有员工信息,按照工资降序排序
select * from emp order by sal desc;
--查询员工表中的所有员工信息,按照工资降序排序,如果相同,再按照奖金升序排序
select * from emp order by sal desc,comm asc;
1.需求:
有的时候,需要分组统计一些,最大值,最小值,平均值,和,总数之类的这样的信息,此时需要分组查询。
2.聚合函数:也叫分组函数
- count(): 统计每组满足的记录总数
- max():统计每组满足条件的最大值
- min():统计每组满足条件的最小值
- avg():统计每组满足条件的平均值
- sum():统计每组满足条件的总和。
注意:
- 所有的聚合函数,都会忽略字段为null的那条记录。
- count(*),不会忽略null值所在的行记录,即通常用于统计总行数。
在分组查询时,只有分组字段可以写在select子句中,其他不是分组的字段,不应该写在select子句中,无意义
多字段进行分组:
A B 字段组合情况下:组的数组最多为 m*n
1 a 1001
1 b 1002
2 b
2 c
3 a
3 b
1 a 1003
1 b 1004
聚合函数处理null值,可以使用ifnull(colName, value).
--案例:查询每个部门中的每种职位的最高工资,最低工资,工资之和
select deptno,job ,max(sal),min(sal),sum(sal) from emp group by job,deptno;
--案例: 查询所有员工的平均工资,平均奖金 使用ifnull函数
select avg(ifnull(sal,0)),avg(ifnull(comm,0)) from emp;
只能使用在分组查询子句后面。起到再过滤的作用。
--查询部门平均工资大于1000部门号,平均工资。
select deptno,avg(ifnull(sal,0)),max(sal) avg_sal from emp group by deptno having avg(ifnull(sal,0)) >1000;
--查询每种职位的最高工资大于1500的职位、最高工资,平均工资,平均奖金。
select job,max(sal),avg(ifnull(sal,0)),avg(ifnull(comm,0)) from emp group by job having max(sal)>1500;
有的时候,我们需要查询表中有那些不同的数据。不需要重复出现,此时可以使用distinct关键字进行去重处理
注意:distinct关键字只能放在select关键字之后。
比如: 查询有那些部门号
需求:当一页的数据量过大时,我们可以进行分页显示操作。注意:分页查询时,一般都要进行先排序,再分页。
关键字limit.
语法:limit m[,n];
m 表示从第几条记录开始查询,
n表示要查询的记录数目。
注意:mysql的记录index从0开始。
一个参数的含义:limit n
表示从0开始查询n条记录
--案例1:每页5条记录,查询第二页的数据。
select empno,ename from emp limit 5,5;
--案例2:查询第page页的数据, 每页大小为pageSize。limit的写法如下:
limit (page-1)*pageSize , pageSize
标签:存储 连接mysql 统计 max red mamicode pass 显示 语法
原文地址:https://www.cnblogs.com/dch-21/p/12872099.html