标签:不可 dep str var 最新 而在 阻塞 har ble
在这篇文章中,我将从上一篇的一个小例子开始,跟你介绍一下InnoDB中的行锁。
在这里,会涉及到一个概念:两阶段加锁协议。
之后,我会介绍行锁中的S锁和X锁,以及这两种锁的作用。
但是我们会发现仅仅有行锁是不能解决幻读问题的,于是我会用例子的方式跟你介绍各种间隙锁。
最后,我会聊一聊粒度更大的表级锁和库锁。
在上一篇的文章中,我们用了这个具体的例子来解释MVCC:
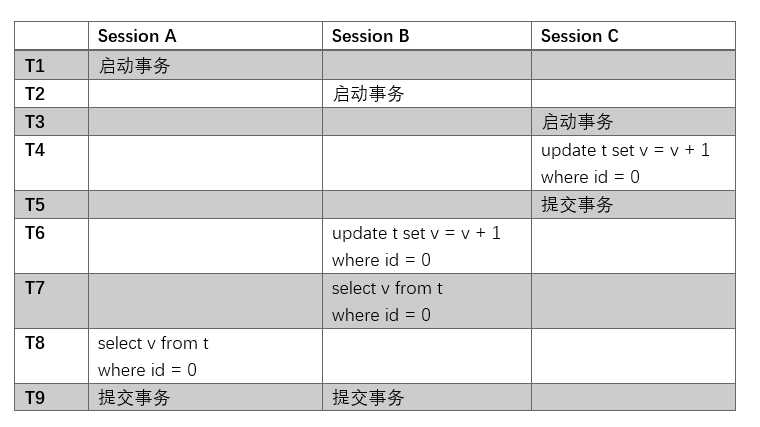
假设我们调换一下T5和T6:
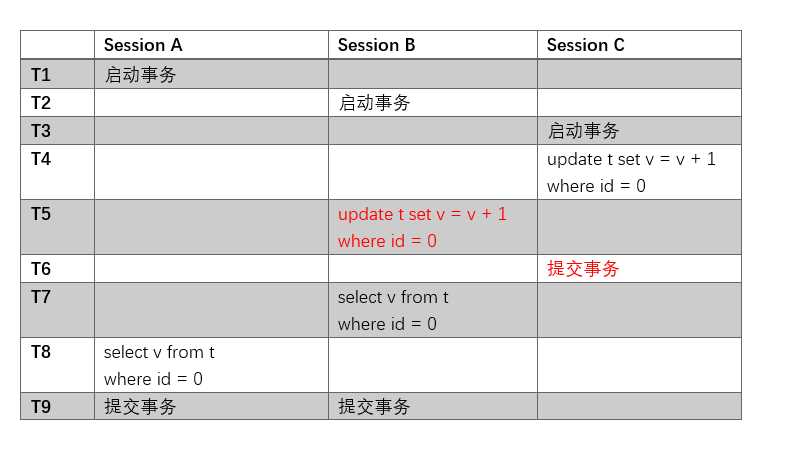
此时,T5是没有办法执行的。
原因是这样的:InnoDB在更新一行的时候,需要先获取这一行的行锁。
但是,当一条语句获取了行锁之后,不是这行语句执行完毕就能释放锁,而是要等到这个事务执行完毕,才会释放锁。
这里涉及到了两阶段加锁协议:它规定事务的加锁和解锁分为两个独立的阶段,加锁阶段只能加锁不能解锁,一旦开始解锁,则进入解锁阶段,不能再加锁。
然后我们再来说说共享锁(S锁,读锁)和排他锁(X锁,写锁)。
对于共享锁来说,如果一个事务获取了某一行的共享锁,则这个事务只能读这一行数据,而不能修改,并且其他事务也可以获取这一行数据的共享锁,读取这一行的数据,同样不能修改数据。
对于排它锁,只能被某一个事务获取。并且在获取排它锁之前,这一行数据上不能存在共享锁。一旦某一个事务获取了这一行的排它锁,那么只有这一个事务可以对这一行数据进行读写操作,其他事务对这一行数据的读写操作都会被阻塞。
此外,不仅仅只有更新操作,插入、删除操作也会获取这一行数据的X锁。
在这里我还要再介绍这两个概念:“快照读”和“当前读”。
你可能还会有印象,在上一篇内容中,我提到了所有的更新操作都必须是“当前读”,现在可以解释原理了,在更新一行数据的时候,InnoDB会对需要更新的那行数据加上X锁,直接获取最新的那一行数据。
与之相对的是“快照读”,也就是MVCC中的数据读取方式,利用“快照”来读取数据的方式,可以极大的提高事务的并发度。
但是并不是说select语句就只能读取快照,它也照样可以给需要读取的数据加锁,来读取最新的数据。也就是说,select语句也一样可以“当前读”。
下面这两个select语句,就是分别加了读锁(S锁,共享锁)和写锁(X锁,排他锁)。
mysql> select k from t where id=1 lock in share mode;
mysql> select k from t where id=1 for update;
注意,由于两阶段加锁协议的存在,如果你采用了一致性读,那么这个锁必须要等事务提交后才能解除。这是牺牲了并发度的一种做法。所以,如果所有的select语句,都加上了S锁,此时的“可重复读”,就变成了“序列化”。
还记得我们上面提到过的幻读吗?
现在你应该能够理解幻读产生的原因了:因为在插入数据的时候,InnoDB采用的是当前读,而读取数据的时候,由于MVCC的存在,采用的是快照读,这就造成了幻读。
但是我们在上面又提到了,select语句也一样可以采用“当前读”。那么,这样能解决幻读吗?
答案是能解决其中一种情况的幻读。
比如我们在上一篇文章中举的关于幻读的例子:
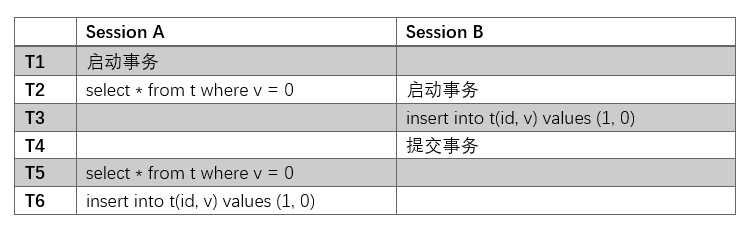
现在你能理解了,因为这里的select是快照读,而事务B的插入操作对于事务A来说是不可见的。如果在T5时刻,事务A的sql语句是select * from t where v = 0 for update,即采用当前读的话,是可以看得到事务B所提交的数据的,这样的话,就避免了幻读的情况。
那如果在T2时刻,事务A的语句就是select * from t where v = 0 for update会怎么样的?
如果在T2时刻就使用了“当前读”,那么T3时刻事务B是无法进行插入操作的。你可以理解为,T2时刻,InnoDB把v=0的数据,都给加上了一把锁。
因为这行sql语句把v=0的数据行都锁住了,所以没有办法再插入一行v=0的数据。
这听起来似乎没什么不对的,但是你仔细想一想,InnoDB中的行锁,锁住的是已经存在的数据。而对于即将要插入的数据,为什么也会被锁住呢?这是不符合行锁的定义的。
这个时候就可以说到间隙锁了。
简单来讲,就是这条语句不仅会锁住所查询的那行数据,还会把这行数据周围的间隙锁住,不让其他事务插入。
也就是说,行锁是锁住已有的数据,而间隙锁,是锁住即将要插入的位置,不让其他数据插入。
在官方文档有这么一句话:
Gap locking can be disabled explicitly. This occurs if you change the transaction isolation level to READ COMMITTED or enable the
innodb_locks_unsafe_for_binlogsystem variable (which is now deprecated).
也就是说,间隔锁在“可重复读”事务隔离级别是默认生效的。所以,MySQL在“可重复读”的事务隔离级别下,是有办法解决幻读问题的。
下面我们来看看哪些情况InnoDB会给数据加上间隔锁,并且这里的间隔锁范围有多大,注意,下面列举的四种情况,指的是where条件中的字段的索引类型。
先定义这么一个表:
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
`c` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `a` (`a`),
KEY `b` (`b`)
) ENGINE=InnoDB;
id是主键,a是一个唯一索引,b是一个普通索引,c不包含任何的索引字段。
然后插入以下的这些数据:
insert into t values(0,0,0,0),(5,5,5,5),(10,10,10,10);
然后我们开始分析各种情况。
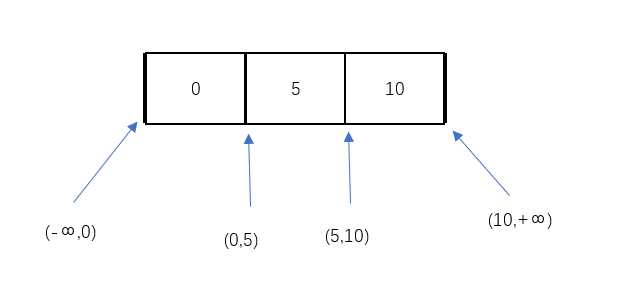
因为没有其他的数据,所以主键索引在数据页内的编排如上图,并且含有4个空隙。这里说的“空隙”,指的是数据可以插入的位置。
比如我要插入一个id为3的数据,这条数据就会插入到位于(0,5)这个空隙内。
下面我们开始尝试:

毫无疑问T3时刻的sql语句是会被阻塞的,原因是id = 5的这行数据已经被加锁了。那么,会不会存在有间隙锁呢?
因为这是一个主键索引,InnoDB必须保证id = 5的数据是唯一的,所以对于id=5的周围,比如(0,5)和(5,10),不需要再加间隙锁了。

那么换一个条件再试试,我们查找id大于6且id小于8的数据,此时事务B中的语句同样会被阻塞。
这是因为,在主键索引没有命中的时候,会对所在的空白范围,全部加锁。注意,我这里说的是未命中的所有空白范围,哪怕我这里的查找条件是大于6且小于8,但是加锁的范围不是(6,8),而是(5,10)。
你可以简单的理解为:从查找条件的最小值开始,往前找到第一个索引值;并且从查找条件的最大值开始,往后找到第一个索引值,这个范围就是加锁的范围。
你可能还会有一个疑问,如果是select * from t where id = 8 for update会怎么样呢?这个问题和上面一样,只要未命中,就加范围锁,锁住空隙(5,10)。
总结一下:对于主键索引来说,命中了,就只加行锁;没命中,则对查找范围的最小值往前找第一个主键,查找范围的最大值往后找第一个主键,并对这个范围加上间隙锁。

对于唯一索引来说,和主键索引其实是差不多的。当索引命中之后,因为唯一索引同样保证了索引的唯一性,所以不需要给这行数据的周围加上间隙锁,只会给命中的数据加锁。
但是这里和主键索引不同的地方是,在给唯一索引a = 5加锁的同时,还会回表,将a = 5对应的主键id = 5这行记录加锁。所以,事务B的修改也同样会被阻塞。
这也是为了防止造成数据不一致的情况,比如我把a = 5的这行数据删了,然后事务B又通过这行数据的主键来对这行数据进行操作。
对于带有范围的查找,和上面主键索引的间隙锁规则是一样的,这里不再赘述。值得注意的是,在唯一索引中,只要命中了,就会相应的给这条索引对应的主键id也加锁。
还需要补充一点,当主键索引和唯一索引直接命中的时候,如下图所示,InnoDB除了给a = 5这行数据加了行锁,还可能给(5, 5)这个间隙加了间隙锁,这样的说法听起来很奇怪。

因为事务A是给a = 5这行数据加了行锁,而行锁只能针对已经存在的数据,不能加到即将插入的数据上;此外,当事务A执行这条语句的时候,事务B是会被阻塞的。直到事务A提交,事务B才会提示唯一索引重复。也就是说,在事务B执行这行语句的时候,是无法访问id = 5这行数据的,事务B不知道id = 5到底存不存在。
所以我才说:当索引直接命中的时候,还会加上这么一个小小的间隙锁。我没有查到这方面的资料,如果你能解释的话,请留言告诉我。
对于普通索引来说,与唯一索引最大的区别,就是普通索引不是必须唯一的,也就是说,当插入数据的时候,可能会有重复的情况。
而在上面的内容中我们也发现了一个规律:InnoDB的间隙锁,就是为了防止新插入的数据影响查找结果。
所以对于普通索引来说,还需要防止新插入的数据和原数据一样的情况(因为唯一索引不需要担心这么一种情况)。
下面我们举例说明,在此之前先插入一行数据:
insert into t values(8,8,5,8);
那么此时我们的索引b,是这样的:
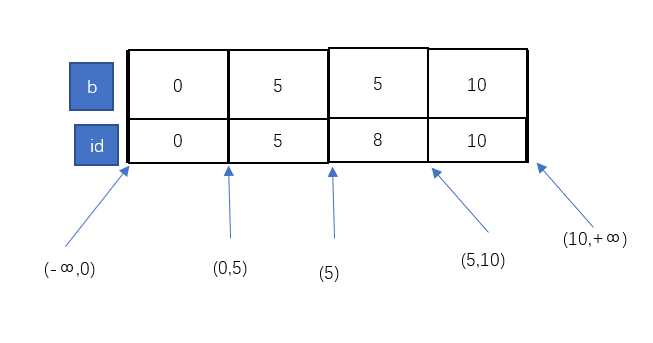
因为是非唯一索引的原因,在两个b = 5的间隙,也能插入数据。

如图所示,我们这次把查找条件换成了b = 5。此时,我们插入的数据id = 1,理论上应该要插入(0,5)这个间隙内,但是由于间隙锁的存在,插入将被阻塞。
换一句话说,只要此时插入的数据b = 5,那么就一定无法插入。
而对于未命中的条件,规则和上文中说到的一样,根据查找条件的最小值往前找到第一个一个索引,再根据这个条件的最大值往后找到第一个索引,构成间隙锁的范围。
此外,与唯一索引一样,所有命中的数据行,都会回表将主键id也锁住。

可以看到,我们的查找条件是c = 5,直接命中了数据。此时我们插入的数据是c = 6,看起来和事务A无关,但是出乎意料的是,事务B还是会被阻塞。
直接说结论:对于不含有索引的查找项来说,会锁住所有的间隙和所有的数据。
关于幻读的问题的一些case,到这里就研究完了(但是我不确定有没有遗漏,如果有,还请你留言告诉我)。
在最后还需要说一个概念,行锁与间隔锁,合称next-key lock。并且需要注意的是,只有在可重复读的事务隔离级别中,才会有间隔锁。并且可重复读是遵循两阶段锁协议,所有加锁的资源,都是在事务提交或者回滚的时候才释放的。所以,在防止幻读产生的时候,同样降低了并发度。
在上一节说完了行级锁之后,我们再来聊聊表级锁。
表级锁有两种,一种是显式添加的,一种是隐式添加的。
还记得我们在上文中提到的读锁和写锁的特点吗,这点在表锁中是一样的。
给表加上了写锁,意味着只有这个会话拥有读写这个表的权限;给表加上了读锁,才能读取这个表上的数据,并且可以多个线程共享读锁,但是,只有当某个表上没有读锁时,才能给这个表加上写锁。
下面是给表加锁的语法:
lock tables table_name read
lock tables table_name write
MDL指的是(Metadata Lock),指的是元数据锁。
MDL也分为了读锁和写锁,功能和上面提到的一样。
只不过MDL不需要像表锁那样显式的使用,它会在访问一个表的时候会被自动加上。其中,在某个表对数据进行操作(包括insert,delete,update,select)的时候,会隐式的加上MDL读锁,在修改表的结构的时候,会加上写锁。
这样做的目的是,防止在一个事务操作数据的时候,表结构被另一个事务给修改了。或者在某一个事务修改表结构的时候,不允许其他的事务操作数据。
顾名思义,库锁就是对整个数据库实例加锁。
MySQL提供了一个加全局读锁的方法,命令是Flush tables with read lock (FTWRL)。
使用过这个命令之后,相当于对全库增加了一个读锁,此时其他线程的数据更新语句(数据的增删改)、数据定义语句(包括建表、修改表结构等)和更新类事务的提交语句都会被阻塞。
全局锁的典型使用场景是,做全库逻辑备份。当然了,实现这个功能,我们也可以使用“可重复读”的事务隔离级别,做一次快照读,依然可以实现备份的功能。只不过,有些引擎并没有实现这个事务隔离级别。
首先,谢谢你能看到这里。
在这篇文章中,尤其是间隙锁部分的内容,我没有查到太多的资料,所以很多内容都是我自己的理解。所以如果你发现了一些bad case,请你留言告诉我。又或者你发现了我哪里的理解是不对的,也请你留言告诉我,谢谢!
当然了,如果有哪里是我讲的不够明白的,也欢迎留言交流~
PS:如果有其他的问题,也可以在公众号找到我,欢迎来找我玩~

标签:不可 dep str var 最新 而在 阻塞 har ble
原文地址:https://www.cnblogs.com/hongjijun/p/12880218.html