标签:main treemap 碰撞 循环 处理 直接插入 哈希 正是 拉链法
1、概述
HashMap是哈希表基于Map接口的实现,它允许null值和null键,它不是线程同步的,同时也不保证有序。Map的这种实现方式为get(取)和put(存)带来了比较好的性能。但是如果涉及到大量的遍历操作的话,就尽量不要把capacity设置得太高(或load factor设置得太低),否则会严重降低遍历的效率。影响HashMap性能的两个重要参数:“initial capacity”(初始化容量)和”load factor“(负载因子)。简单来说,容量就是哈希表桶的个数,负载因子就是键值对个数与哈希表长度的一个比值,当比值超过负载因子之后,HashMap就会进行rehash操作来进行扩容。
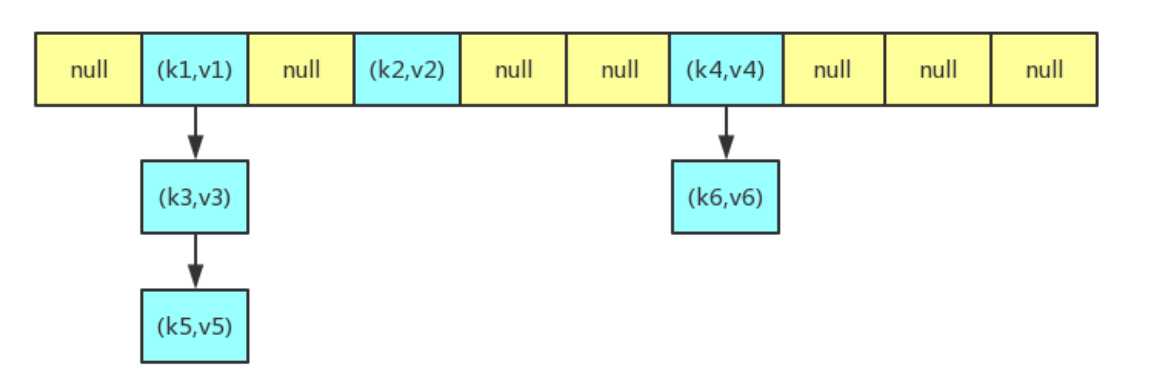
HashMap 的大致结构如下图所示,其中哈希表是一个数组,我们经常把数组中的每一个节点称为一个桶,哈希表中的每个节点都用来存储一个键值对。在插入元素时,如果发生冲突(即多个键值对映射到同一个桶上)的话,就会通过链表的形式来解决冲突。因为一个桶上可能存在多个键值对,所以在查找的时候,会先通过key的哈希值先定位到桶,再遍历桶上的所有键值对,找出key相等的键值对,从而来获取value。
2、属性
//默认的初始容量为16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
//最大的容量上限为2^30
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认的负载因子为0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//变成树型结构的临界值为8
static final int TREEIFY_THRESHOLD = 8;
//恢复链式结构的临界值为6
static final int UNTREEIFY_THRESHOLD = 6;
//哈希表
transientNode<K,V>[] table;
//哈希表中键值对的个数
transient int size;
//哈希表被修改的次数
transient int modCount;
//它是通过capacity*load factor计算出来的,当size到达这个值时,就会进行扩容操作int threshold;
/当哈希表的大小超过这个阈值,才会把链式结构转化成树型结构,否则仅采取扩容来尝试减少冲突
static final int MIN_TREEIFY_CAPACITY = 64;
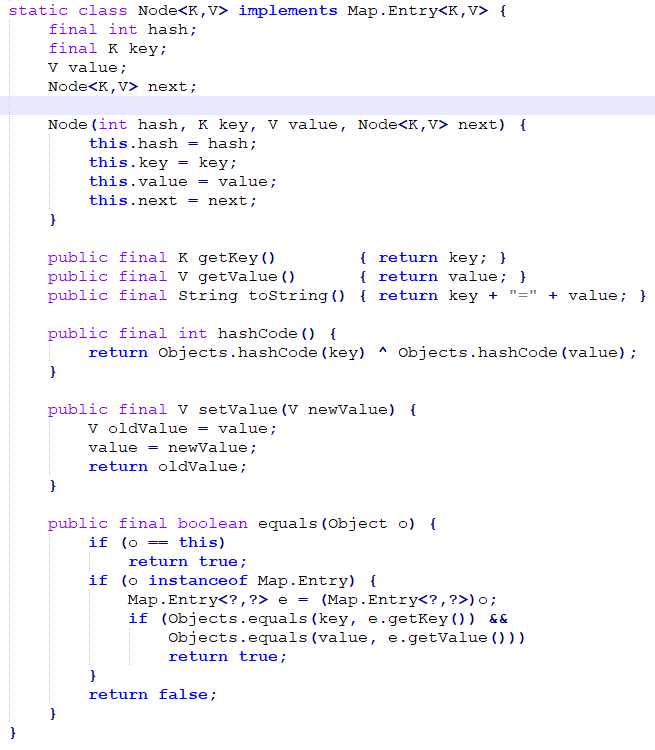
下面是Node 类的定义,它是HashMap 中的一个静态内部类,哈希表中的每一个节点都是Node 类型。我们可以看到,Node 类中有4 个属性,其中除了key 和value 之外,还有hash 和next 两个属性。hash 是用来存储key 的哈希值的,next 是在构建链表时用来指向后继节点的。
3、方法
put(K key,V value)
put方法比较复杂,实现步骤大致如下:
1)先通过hash值计算出key映射到哪个桶。
2)如果桶上没有碰撞冲突,则直接插入。
3)如果出现碰撞冲突了,则需要处理冲突:
(1)如果该桶使用红黑树处理冲突,则调用红黑树的方法插入。
(2)否则采用传统的链式方法插入。如果链的长度到达临界值,则把链转变为红黑树。
4)如果桶中存在重复的键,则为该键替换新值。
5)如果size大于阈值,则进行扩容。
get(Object key)
实现步骤大致如下:
1)通过hash值获取该key映射到的桶。
2)桶上的key就是要查找的key,则直接命中.
3)桶上的key不是要查找的key,则查看后续节点:
(1)如果后续节点是树节点,通过调用树的方法查找该key。
(2)如果后续节点是链式节点,则通过循环遍历链查找该key。
hash方法
在get方法和put方法中都需要先计算key映射到哪个桶上,然后才进行之后的操作,计算的主要代码如下:
(n -1) & hash
上面代码中的n指的是哈希表的大小,hash指的是key的哈希值,hash是通过下面这个方法计算出来的,采用了二次哈希的方式,其中key的hashCode方法是一个native方法:
static final int hash(Object key) {
int h;
return(key == null) ? 0: (h = key.hashCode()) ^ (h >>>16);
这个hash方法先通过key的hashCode方法获取一个哈希值,再拿这个哈希值与它的高16位的哈希值做一个异或操作来得到最后的哈希值,计算过程可以参考下图。为啥要这样做呢?注释中是这样解释的:如果当n很小,假设为64的话,那么n-1即为63(0x111111),这样的值跟hashCode()直接做与操作,实际上只使用了哈希值的后6位。如果当哈希值的高位变化很大,低位变化很小,这样就很容易造成冲突了,所以这里把高低位都利用起来,从而解决了这个问题

正是因为与的这个操作,决定了HashMap的大小只能是2的幂次方,想一想,如果不是2的幂次方,会发生什么事情?即使你在创建HashMap的时候指定了初始大小,HashMap在构建的时候也会调用下面这个方法来调整大小:

这个方法的作用看起来可能不是很直观,它的实际作用就是把cap变成第一个大于等于2的幂次方的数。例如,16还是16,13就会调整为16,17就会调整为32。
resize方法
HashMap在进行扩容时,使用的rehash方式非常巧妙,因为每次扩容都是翻倍,与原来计算(n-1)&hash的结果相比,只是多了一个bit位,所以节点要么就在原来的位置,要么就被分配到“原位置+旧容量”这个位置。例如,原来的容量为32,那么应该拿hash跟31(0x11111)做与操作;在扩容扩到了64的容量之后,应该拿hash跟63(0x111111)做与操作。新容量跟原来相比只是多了一个bit位,假设原来的位置在23,那么当新增的那个bit位的计算结果为0时,那么该节点还是在23;相反,计算结果为1时,则该节点会被分配到23+31的桶上。正是因为这样巧妙的rehash方式,保证了rehash之后每个桶上的节点数必定小于等于原来桶上的节点数,即保证了rehash之后不会出现更严重的冲突。
总结:
通过红黑树的方式来处理哈希冲突是我第一次看见!学过哈希,学过红黑树,就是从来没想到两个可以结合到一起这么用!按照原来的拉链法来解决冲突,如果一个桶上的冲突很严重的话,是会导致哈希表的效率降低至O(n),而通过红黑树的方式,可以把效率改进至O(logn)。相比链式结构的节点,树型结构的节点会占用比较多的空间,所以这是一种以空间换时间的改进方式。
HashMap的一些方法使用
package util;
import java.util.Map;
import java.util.Set;
import java.util.TreeMap;
import java.util.Collection;
import java.util.HashMap;
import java.util.Iterator;
//hashMap是不同步的,并且键值对可以为null;无序
public class HashMapDemo {
public static void main(String[] args) {
Map<String, String> hashmap= new TreeMap<String, String>();
//put
//添加键值对,键值不可重复
hashmap.put("a","97");
hashmap.put("b","98");
hashmap.put("c","99");
hashmap.put("d","100");
System.out.println("遍历:");
for(Map.Entry<String, String> entry : hashmap.entrySet()) {
System.out.println(entry.getKey()+"->"+entry.getValue());
}
//如果已经存在键,则将value替换,返回oldValue;
String oldValue = hashmap.put("a","不知道");
System.out.println("已将a的值替换,a的oldValue:"+oldValue);
//删除所有的映射
// hashmap.clear();
//containsKey,containsValue
//是否存在key value
boolean key = hashmap.containsKey("c");
System.out.println("是否存在key c:"+key);
boolean value = hashmap.containsValue("100");
System.out.println("是否存在value 100:"+value);
//get()
//通过key得到value
String values = hashmap.get("c");
System.out.println("c的value:"+values);
//判断是否为空
boolean isempty = hashmap.isEmpty();
System.out.println("集合为空吗:"+isempty);
//keySet集合
Set<String> keyset = hashmap.keySet();
System.out.println("keyset:"+keyset);
// Iterator<String> it = keyset.iterator();
// while(it.hasNext()) {
// System.out.println(it.next());
// }
//putAll(),
//将hashmap里面的所有键值对复制到newHashMap中
Map<String,String> newHashMap = new HashMap<String,String>();
newHashMap.putAll(hashmap);
//判断指定的key是否有value,没有则把相应的value赋值给key,并返回null,
//如果有映射则返回映射的value
String ifvalues = hashmap.putIfAbsent("e", "101");//null
String ifvalues2 = hashmap.putIfAbsent("c", "200");
System.out.println("e是否有映射:"+ifvalues);
System.out.println("c是否有映射,有返回value:"+ifvalues2);
hashmap.remove("e");
//存在key,将其value替换,并返回oldValue
String replacevalue = hashmap.replace("c", "200");
System.out.println("c的指已经替换,c的oldValue:"+replacevalue);
//replace(K key, V oldValue, V newValue) 只有key和value完全符合才能替换
boolean replacevalue2 = hashmap.replace("c", "200","99");
System.out.println("替换成功?true:false:"+replacevalue2);
int size = hashmap.size();
System.out.println("size:"+size);
String Values = hashmap.getOrDefault("c","0");
System.out.println(Values);
//所有value
Collection<String> collection =hashmap.values();
System.out.println("所有value"+collection);
// Iterator<String> it = collection.iterator();
// while(it.hasNext()) {
// System.out.println(it.next());
// }
//遍历打印
// System.out.println("遍历:");
// for(Map.Entry<String, String> entry : hashmap.entrySet()) {
// System.out.println(entry.getKey()+"->"+entry.getValue());
// }
}
}
运行结果,这里取值特殊没有体现出HashMap的无序性。

标签:main treemap 碰撞 循环 处理 直接插入 哈希 正是 拉链法
原文地址:https://www.cnblogs.com/lgh544/p/12889645.html