标签:copyright 操作 its 有一个 efault trap 监听端口 解决方案 expected
一、netty 为啥要进行拆包粘包处理
简单点描述,netty底层通讯是走的TCP协议,接收到的都是字节流,然后以字节字节队列的形式存在缓存堆里面。而TCP协议每一次最大接收的字节长度是1024个字节,一旦超过这个长度,那么就会出现一下各种形式:
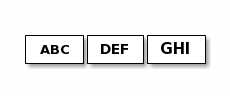
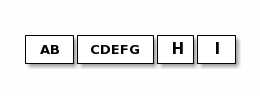
所以在字节长度超过1024的时候,一个完整的包可能会被TCP拆分成多个包进行发送,也有可能把多个小的包封装成一个大的数据包发送,这就是所谓的TCP粘包和拆包问题。
二、解决方案
netty基于以上问题也提供了一些组件,比如:
/* * Copyright 2012 The Netty Project * * The Netty Project licenses this file to you under the Apache License, * version 2.0 (the "License"); you may not use this file except in compliance * with the License. You may obtain a copy of the License at: * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, WITHOUT * WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the * License for the specific language governing permissions and limitations * under the License. */ package io.netty.handler.codec; import java.nio.ByteOrder; import java.util.List; import io.netty.buffer.ByteBuf; import io.netty.channel.ChannelHandlerContext; import io.netty.handler.codec.serialization.ObjectDecoder; /** * A decoder that splits the received {@link ByteBuf}s dynamically by the * value of the length field in the message. It is particularly useful when you * decode a binary message which has an integer header field that represents the * length of the message body or the whole message. * <p> * {@link LengthFieldBasedFrameDecoder} has many configuration parameters so * that it can decode any message with a length field, which is often seen in * proprietary client-server protocols. Here are some example that will give * you the basic idea on which option does what. * * <h3>2 bytes length field at offset 0, do not strip header</h3> * * The value of the length field in this example is <tt>12 (0x0C)</tt> which * represents the length of "HELLO, WORLD". By default, the decoder assumes * that the length field represents the number of the bytes that follows the * length field. Therefore, it can be decoded with the simplistic parameter * combination. * <pre> * <b>lengthFieldOffset</b> = <b>0</b> * <b>lengthFieldLength</b> = <b>2</b> * lengthAdjustment = 0 * initialBytesToStrip = 0 (= do not strip header) * * BEFORE DECODE (14 bytes) AFTER DECODE (14 bytes) * +--------+----------------+ +--------+----------------+ * | Length | Actual Content |----->| Length | Actual Content | * | 0x000C | "HELLO, WORLD" | | 0x000C | "HELLO, WORLD" | * +--------+----------------+ +--------+----------------+ * </pre> * * <h3>2 bytes length field at offset 0, strip header</h3> * * Because we can get the length of the content by calling * {@link ByteBuf#readableBytes()}, you might want to strip the length * field by specifying <tt>initialBytesToStrip</tt>. In this example, we * specified <tt>2</tt>, that is same with the length of the length field, to * strip the first two bytes. * <pre> * lengthFieldOffset = 0 * lengthFieldLength = 2 * lengthAdjustment = 0 * <b>initialBytesToStrip</b> = <b>2</b> (= the length of the Length field) * * BEFORE DECODE (14 bytes) AFTER DECODE (12 bytes) * +--------+----------------+ +----------------+ * | Length | Actual Content |----->| Actual Content | * | 0x000C | "HELLO, WORLD" | | "HELLO, WORLD" | * +--------+----------------+ +----------------+ * </pre> * * <h3>2 bytes length field at offset 0, do not strip header, the length field * represents the length of the whole message</h3> * * In most cases, the length field represents the length of the message body * only, as shown in the previous examples. However, in some protocols, the * length field represents the length of the whole message, including the * message header. In such a case, we specify a non-zero * <tt>lengthAdjustment</tt>. Because the length value in this example message * is always greater than the body length by <tt>2</tt>, we specify <tt>-2</tt> * as <tt>lengthAdjustment</tt> for compensation. * <pre> * lengthFieldOffset = 0 * lengthFieldLength = 2 * <b>lengthAdjustment</b> = <b>-2</b> (= the length of the Length field) * initialBytesToStrip = 0 * * BEFORE DECODE (14 bytes) AFTER DECODE (14 bytes) * +--------+----------------+ +--------+----------------+ * | Length | Actual Content |----->| Length | Actual Content | * | 0x000E | "HELLO, WORLD" | | 0x000E | "HELLO, WORLD" | * +--------+----------------+ +--------+----------------+ * </pre> * * <h3>3 bytes length field at the end of 5 bytes header, do not strip header</h3> * * The following message is a simple variation of the first example. An extra * header value is prepended to the message. <tt>lengthAdjustment</tt> is zero * again because the decoder always takes the length of the prepended data into * account during frame length calculation. * <pre> * <b>lengthFieldOffset</b> = <b>2</b> (= the length of Header 1) * <b>lengthFieldLength</b> = <b>3</b> * lengthAdjustment = 0 * initialBytesToStrip = 0 * * BEFORE DECODE (17 bytes) AFTER DECODE (17 bytes) * +----------+----------+----------------+ +----------+----------+----------------+ * | Header 1 | Length | Actual Content |----->| Header 1 | Length | Actual Content | * | 0xCAFE | 0x00000C | "HELLO, WORLD" | | 0xCAFE | 0x00000C | "HELLO, WORLD" | * +----------+----------+----------------+ +----------+----------+----------------+ * </pre> * * <h3>3 bytes length field at the beginning of 5 bytes header, do not strip header</h3> * * This is an advanced example that shows the case where there is an extra * header between the length field and the message body. You have to specify a * positive <tt>lengthAdjustment</tt> so that the decoder counts the extra * header into the frame length calculation. * <pre> * lengthFieldOffset = 0 * lengthFieldLength = 3 * <b>lengthAdjustment</b> = <b>2</b> (= the length of Header 1) * initialBytesToStrip = 0 * * BEFORE DECODE (17 bytes) AFTER DECODE (17 bytes) * +----------+----------+----------------+ +----------+----------+----------------+ * | Length | Header 1 | Actual Content |----->| Length | Header 1 | Actual Content | * | 0x00000C | 0xCAFE | "HELLO, WORLD" | | 0x00000C | 0xCAFE | "HELLO, WORLD" | * +----------+----------+----------------+ +----------+----------+----------------+ * </pre> * * <h3>2 bytes length field at offset 1 in the middle of 4 bytes header, * strip the first header field and the length field</h3> * * This is a combination of all the examples above. There are the prepended * header before the length field and the extra header after the length field. * The prepended header affects the <tt>lengthFieldOffset</tt> and the extra * header affects the <tt>lengthAdjustment</tt>. We also specified a non-zero * <tt>initialBytesToStrip</tt> to strip the length field and the prepended * header from the frame. If you don‘t want to strip the prepended header, you * could specify <tt>0</tt> for <tt>initialBytesToSkip</tt>. * <pre> * lengthFieldOffset = 1 (= the length of HDR1) * lengthFieldLength = 2 * <b>lengthAdjustment</b> = <b>1</b> (= the length of HDR2) * <b>initialBytesToStrip</b> = <b>3</b> (= the length of HDR1 + LEN) * * BEFORE DECODE (16 bytes) AFTER DECODE (13 bytes) * +------+--------+------+----------------+ +------+----------------+ * | HDR1 | Length | HDR2 | Actual Content |----->| HDR2 | Actual Content | * | 0xCA | 0x000C | 0xFE | "HELLO, WORLD" | | 0xFE | "HELLO, WORLD" | * +------+--------+------+----------------+ +------+----------------+ * </pre> * * <h3>2 bytes length field at offset 1 in the middle of 4 bytes header, * strip the first header field and the length field, the length field * represents the length of the whole message</h3> * * Let‘s give another twist to the previous example. The only difference from * the previous example is that the length field represents the length of the * whole message instead of the message body, just like the third example. * We have to count the length of HDR1 and Length into <tt>lengthAdjustment</tt>. * Please note that we don‘t need to take the length of HDR2 into account * because the length field already includes the whole header length. * <pre> * lengthFieldOffset = 1 * lengthFieldLength = 2 * <b>lengthAdjustment</b> = <b>-3</b> (= the length of HDR1 + LEN, negative) * <b>initialBytesToStrip</b> = <b> 3</b> * * BEFORE DECODE (16 bytes) AFTER DECODE (13 bytes) * +------+--------+------+----------------+ +------+----------------+ * | HDR1 | Length | HDR2 | Actual Content |----->| HDR2 | Actual Content | * | 0xCA | 0x0010 | 0xFE | "HELLO, WORLD" | | 0xFE | "HELLO, WORLD" | * +------+--------+------+----------------+ +------+----------------+ * </pre> * @see LengthFieldPrepender */ public class LengthFieldBasedFrameDecoder extends ByteToMessageDecoder { private final ByteOrder byteOrder; private final int maxFrameLength; private final int lengthFieldOffset; private final int lengthFieldLength; private final int lengthFieldEndOffset; private final int lengthAdjustment; private final int initialBytesToStrip; private final boolean failFast; private boolean discardingTooLongFrame; private long tooLongFrameLength; private long bytesToDiscard; /** * Creates a new instance. * * @param maxFrameLength * the maximum length of the frame. If the length of the frame is * greater than this value, {@link TooLongFrameException} will be * thrown. * @param lengthFieldOffset * the offset of the length field * @param lengthFieldLength * the length of the length field */ public LengthFieldBasedFrameDecoder( int maxFrameLength, int lengthFieldOffset, int lengthFieldLength) { this(maxFrameLength, lengthFieldOffset, lengthFieldLength, 0, 0); } /** * Creates a new instance. * * @param maxFrameLength * the maximum length of the frame. If the length of the frame is * greater than this value, {@link TooLongFrameException} will be * thrown. * @param lengthFieldOffset * the offset of the length field * @param lengthFieldLength * the length of the length field * @param lengthAdjustment * the compensation value to add to the value of the length field * @param initialBytesToStrip * the number of first bytes to strip out from the decoded frame */ public LengthFieldBasedFrameDecoder( int maxFrameLength, int lengthFieldOffset, int lengthFieldLength, int lengthAdjustment, int initialBytesToStrip) { this( maxFrameLength, lengthFieldOffset, lengthFieldLength, lengthAdjustment, initialBytesToStrip, true); } /** * Creates a new instance. * * @param maxFrameLength * the maximum length of the frame. If the length of the frame is * greater than this value, {@link TooLongFrameException} will be * thrown. * @param lengthFieldOffset * the offset of the length field * @param lengthFieldLength * the length of the length field * @param lengthAdjustment * the compensation value to add to the value of the length field * @param initialBytesToStrip * the number of first bytes to strip out from the decoded frame * @param failFast * If <tt>true</tt>, a {@link TooLongFrameException} is thrown as * soon as the decoder notices the length of the frame will exceed * <tt>maxFrameLength</tt> regardless of whether the entire frame * has been read. If <tt>false</tt>, a {@link TooLongFrameException} * is thrown after the entire frame that exceeds <tt>maxFrameLength</tt> * has been read. */ public LengthFieldBasedFrameDecoder( int maxFrameLength, int lengthFieldOffset, int lengthFieldLength, int lengthAdjustment, int initialBytesToStrip, boolean failFast) { this( ByteOrder.BIG_ENDIAN, maxFrameLength, lengthFieldOffset, lengthFieldLength, lengthAdjustment, initialBytesToStrip, failFast); } /** * Creates a new instance. * * @param byteOrder * the {@link ByteOrder} of the length field * @param maxFrameLength * the maximum length of the frame. If the length of the frame is * greater than this value, {@link TooLongFrameException} will be * thrown. * @param lengthFieldOffset * the offset of the length field * @param lengthFieldLength * the length of the length field * @param lengthAdjustment * the compensation value to add to the value of the length field * @param initialBytesToStrip * the number of first bytes to strip out from the decoded frame * @param failFast * If <tt>true</tt>, a {@link TooLongFrameException} is thrown as * soon as the decoder notices the length of the frame will exceed * <tt>maxFrameLength</tt> regardless of whether the entire frame * has been read. If <tt>false</tt>, a {@link TooLongFrameException} * is thrown after the entire frame that exceeds <tt>maxFrameLength</tt> * has been read. */ public LengthFieldBasedFrameDecoder( ByteOrder byteOrder, int maxFrameLength, int lengthFieldOffset, int lengthFieldLength, int lengthAdjustment, int initialBytesToStrip, boolean failFast) { if (byteOrder == null) { throw new NullPointerException("byteOrder"); } if (maxFrameLength <= 0) { throw new IllegalArgumentException( "maxFrameLength must be a positive integer: " + maxFrameLength); } if (lengthFieldOffset < 0) { throw new IllegalArgumentException( "lengthFieldOffset must be a non-negative integer: " + lengthFieldOffset); } if (initialBytesToStrip < 0) { throw new IllegalArgumentException( "initialBytesToStrip must be a non-negative integer: " + initialBytesToStrip); } if (lengthFieldOffset > maxFrameLength - lengthFieldLength) { throw new IllegalArgumentException( "maxFrameLength (" + maxFrameLength + ") " + "must be equal to or greater than " + "lengthFieldOffset (" + lengthFieldOffset + ") + " + "lengthFieldLength (" + lengthFieldLength + ")."); } this.byteOrder = byteOrder; this.maxFrameLength = maxFrameLength; this.lengthFieldOffset = lengthFieldOffset; this.lengthFieldLength = lengthFieldLength; this.lengthAdjustment = lengthAdjustment; lengthFieldEndOffset = lengthFieldOffset + lengthFieldLength; this.initialBytesToStrip = initialBytesToStrip; this.failFast = failFast; } @Override protected final void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception { Object decoded = decode(ctx, in); if (decoded != null) { out.add(decoded); } } private void discardingTooLongFrame(ByteBuf in) { long bytesToDiscard = this.bytesToDiscard; int localBytesToDiscard = (int) Math.min(bytesToDiscard, in.readableBytes()); in.skipBytes(localBytesToDiscard); bytesToDiscard -= localBytesToDiscard; this.bytesToDiscard = bytesToDiscard; failIfNecessary(false); } private static void failOnNegativeLengthField(ByteBuf in, long frameLength, int lengthFieldEndOffset) { in.skipBytes(lengthFieldEndOffset); throw new CorruptedFrameException( "negative pre-adjustment length field: " + frameLength); } private static void failOnFrameLengthLessThanLengthFieldEndOffset(ByteBuf in, long frameLength, int lengthFieldEndOffset) { in.skipBytes(lengthFieldEndOffset); throw new CorruptedFrameException( "Adjusted frame length (" + frameLength + ") is less " + "than lengthFieldEndOffset: " + lengthFieldEndOffset); } private void exceededFrameLength(ByteBuf in, long frameLength) { long discard = frameLength - in.readableBytes(); tooLongFrameLength = frameLength; if (discard < 0) { // buffer contains more bytes then the frameLength so we can discard all now in.skipBytes((int) frameLength); } else { // Enter the discard mode and discard everything received so far. discardingTooLongFrame = true; bytesToDiscard = discard; in.skipBytes(in.readableBytes()); } failIfNecessary(true); } private static void failOnFrameLengthLessThanInitialBytesToStrip(ByteBuf in, long frameLength, int initialBytesToStrip) { in.skipBytes((int) frameLength); throw new CorruptedFrameException( "Adjusted frame length (" + frameLength + ") is less " + "than initialBytesToStrip: " + initialBytesToStrip); } /** * Create a frame out of the {@link ByteBuf} and return it. * * @param ctx the {@link ChannelHandlerContext} which this {@link ByteToMessageDecoder} belongs to * @param in the {@link ByteBuf} from which to read data * @return frame the {@link ByteBuf} which represent the frame or {@code null} if no frame could * be created. */ protected Object decode(ChannelHandlerContext ctx, ByteBuf in) throws Exception { if (discardingTooLongFrame) { discardingTooLongFrame(in); } if (in.readableBytes() < lengthFieldEndOffset) { return null; } int actualLengthFieldOffset = in.readerIndex() + lengthFieldOffset; long frameLength = getUnadjustedFrameLength(in, actualLengthFieldOffset, lengthFieldLength, byteOrder); if (frameLength < 0) { failOnNegativeLengthField(in, frameLength, lengthFieldEndOffset); } frameLength += lengthAdjustment + lengthFieldEndOffset; if (frameLength < lengthFieldEndOffset) { failOnFrameLengthLessThanLengthFieldEndOffset(in, frameLength, lengthFieldEndOffset); } if (frameLength > maxFrameLength) { exceededFrameLength(in, frameLength); return null; } // never overflows because it‘s less than maxFrameLength int frameLengthInt = (int) frameLength; if (in.readableBytes() < frameLengthInt) { return null; } if (initialBytesToStrip > frameLengthInt) { failOnFrameLengthLessThanInitialBytesToStrip(in, frameLength, initialBytesToStrip); } in.skipBytes(initialBytesToStrip); // extract frame int readerIndex = in.readerIndex(); int actualFrameLength = frameLengthInt - initialBytesToStrip; ByteBuf frame = extractFrame(ctx, in, readerIndex, actualFrameLength); in.readerIndex(readerIndex + actualFrameLength); return frame; } /** * Decodes the specified region of the buffer into an unadjusted frame length. The default implementation is * capable of decoding the specified region into an unsigned 8/16/24/32/64 bit integer. Override this method to * decode the length field encoded differently. Note that this method must not modify the state of the specified * buffer (e.g. {@code readerIndex}, {@code writerIndex}, and the content of the buffer.) * * @throws DecoderException if failed to decode the specified region */ protected long getUnadjustedFrameLength(ByteBuf buf, int offset, int length, ByteOrder order) { buf = buf.order(order); long frameLength; switch (length) { case 1: frameLength = buf.getUnsignedByte(offset); break; case 2: frameLength = buf.getUnsignedShort(offset); break; case 3: frameLength = buf.getUnsignedMedium(offset); break; case 4: frameLength = buf.getUnsignedInt(offset); break; case 8: frameLength = buf.getLong(offset); break; default: throw new DecoderException( "unsupported lengthFieldLength: " + lengthFieldLength + " (expected: 1, 2, 3, 4, or 8)"); } return frameLength; } private void failIfNecessary(boolean firstDetectionOfTooLongFrame) { if (bytesToDiscard == 0) { // Reset to the initial state and tell the handlers that // the frame was too large. long tooLongFrameLength = this.tooLongFrameLength; this.tooLongFrameLength = 0; discardingTooLongFrame = false; if (!failFast || firstDetectionOfTooLongFrame) { fail(tooLongFrameLength); } } else { // Keep discarding and notify handlers if necessary. if (failFast && firstDetectionOfTooLongFrame) { fail(tooLongFrameLength); } } } /** * Extract the sub-region of the specified buffer. * <p> * If you are sure that the frame and its content are not accessed after * the current {@link #decode(ChannelHandlerContext, ByteBuf)} * call returns, you can even avoid memory copy by returning the sliced * sub-region (i.e. <tt>return buffer.slice(index, length)</tt>). * It‘s often useful when you convert the extracted frame into an object. * Refer to the source code of {@link ObjectDecoder} to see how this method * is overridden to avoid memory copy. */ protected ByteBuf extractFrame(ChannelHandlerContext ctx, ByteBuf buffer, int index, int length) { return buffer.retainedSlice(index, length); } private void fail(long frameLength) { if (frameLength > 0) { throw new TooLongFrameException( "Adjusted frame length exceeds " + maxFrameLength + ": " + frameLength + " - discarded"); } else { throw new TooLongFrameException( "Adjusted frame length exceeds " + maxFrameLength + " - discarding"); } } }
通过源码我们可以知道核心方法是:
protected Object decode(ChannelHandlerContext ctx, ByteBuf in) throws Exception { if (discardingTooLongFrame) { discardingTooLongFrame(in); } if (in.readableBytes() < lengthFieldEndOffset) { return null; } int actualLengthFieldOffset = in.readerIndex() + lengthFieldOffset; long frameLength = getUnadjustedFrameLength(in, actualLengthFieldOffset, lengthFieldLength, byteOrder); if (frameLength < 0) { failOnNegativeLengthField(in, frameLength, lengthFieldEndOffset); } frameLength += lengthAdjustment + lengthFieldEndOffset; if (frameLength < lengthFieldEndOffset) { failOnFrameLengthLessThanLengthFieldEndOffset(in, frameLength, lengthFieldEndOffset); } if (frameLength > maxFrameLength) { exceededFrameLength(in, frameLength); return null; } // never overflows because it‘s less than maxFrameLength int frameLengthInt = (int) frameLength; if (in.readableBytes() < frameLengthInt) { return null; } if (initialBytesToStrip > frameLengthInt) { failOnFrameLengthLessThanInitialBytesToStrip(in, frameLength, initialBytesToStrip); } in.skipBytes(initialBytesToStrip); // extract frame int readerIndex = in.readerIndex(); int actualFrameLength = frameLengthInt - initialBytesToStrip; ByteBuf frame = extractFrame(ctx, in, readerIndex, actualFrameLength); in.readerIndex(readerIndex + actualFrameLength); return frame; }
所以根据自己得协议,写了一个实现方式:
public class MessageEncoder extends ByteToMessageDecoder { @Override protected final void decode(ChannelHandlerContext ctx, ByteBuf buffer, List<Object> out) throws Exception { // 可读长度必须大于基本长度 if (buffer.readableBytes() >= 12) { // 记录包头开始的index int beginReader = buffer.readerIndex(); // 标记包头开始的index buffer.markReaderIndex(); // 读到了协议的开始标志,结束while循环 String startDataStr = buffer.getByte(0)+""+buffer.getByte(1)+""; if (startDataStr.equals("7188")) { } else { buffer.skipBytes(buffer.readableBytes()); return; } // 消息的长度 // String dataLen = buffer.getByte(10)+""+buffer.getByte(11)+""; String commond = ByteBufUtil.hexDump(buffer); String str = commond.substring(20,24); Integer length = Integer.parseInt(str.substring(2,4)+str.substring(0,2),16); System.out.println("内容区数据包长度:"+length); // 判断请求数据包数据是否到齐 if (buffer.readableBytes() < length+14) { // 还原读指针 buffer.readerIndex(beginReader); return; } // 读取data数据 //buffer.readBytes(length+14); out.add(buffer.readSlice(length+14).retain()); } } }
public void start() throws Exception { new Thread(new Runnable() { @Override public void run() { EventLoopGroup group = new NioEventLoopGroup(); EventLoopGroup workerGroup = new NioEventLoopGroup(); try { ServerBootstrap sb = new ServerBootstrap(); sb.group(group, workerGroup) // 绑定线程池 .channel(NioServerSocketChannel.class) // 指定使用的channel .localAddress(port)// 绑定监听端口 .childHandler(new ChannelInitializer<SocketChannel>() { // 绑定客户端连接时候触发操作 @Override protected void initChannel(SocketChannel ch) throws Exception { System.out.println("connected...; Client:" + ch.remoteAddress()); ch.pipeline()/* * .addLast("logging",new * LoggingHandler(LogLevel. * ERROR )) */ .addLast(new MessageEncoder()) .addLast(new EchoServerHandler()); // 客户端触发操作 } }); ChannelFuture cf; cf = sb.bind().sync(); cf.channel().closeFuture().sync(); // 关闭服务器通道 System.out.println(EchoServer.class + " started and listen on " + cf.channel().localAddress()); } catch (InterruptedException e) { logger.error("listen Exception,the msg is >>"+e); e.printStackTrace(); } // 服务器异步创建绑定 finally { group.shutdownGracefully(); workerGroup.shutdownGracefully(); } } }).start(); }
这个写法是基于自定义协议,然后又是非规范协议的操作来实现的。比如类似下面16进制组合ascii码的协议:
475831393530303810d901000069da
标签:copyright 操作 its 有一个 efault trap 监听端口 解决方案 expected
原文地址:https://www.cnblogs.com/zcsheng/p/12910665.html