标签:append 表格 bsp beautiful alt finally img 词条 admin
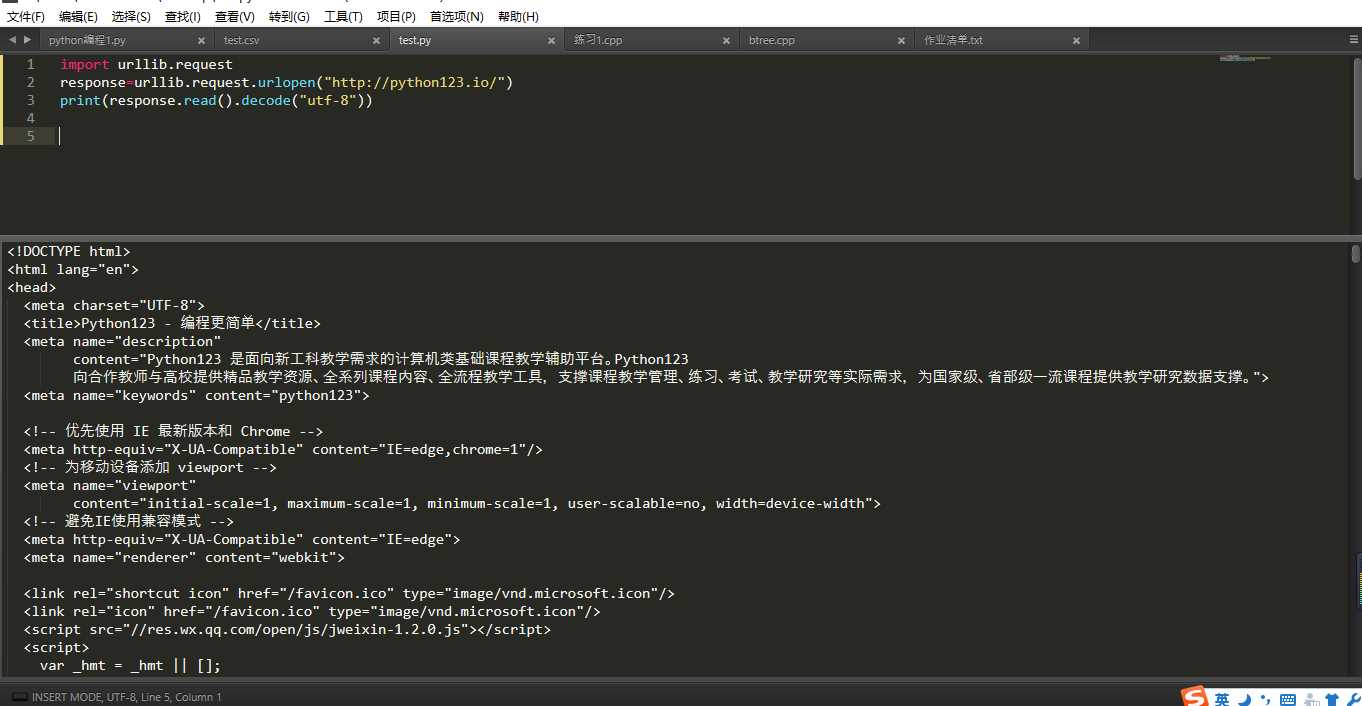
1.利用urllib库爬取python123.io网站的html代码
1 import urllib.request 2 response=urllib.request.urlopen("http://python123.io/") 3 print(response.read().decode("utf-8"))
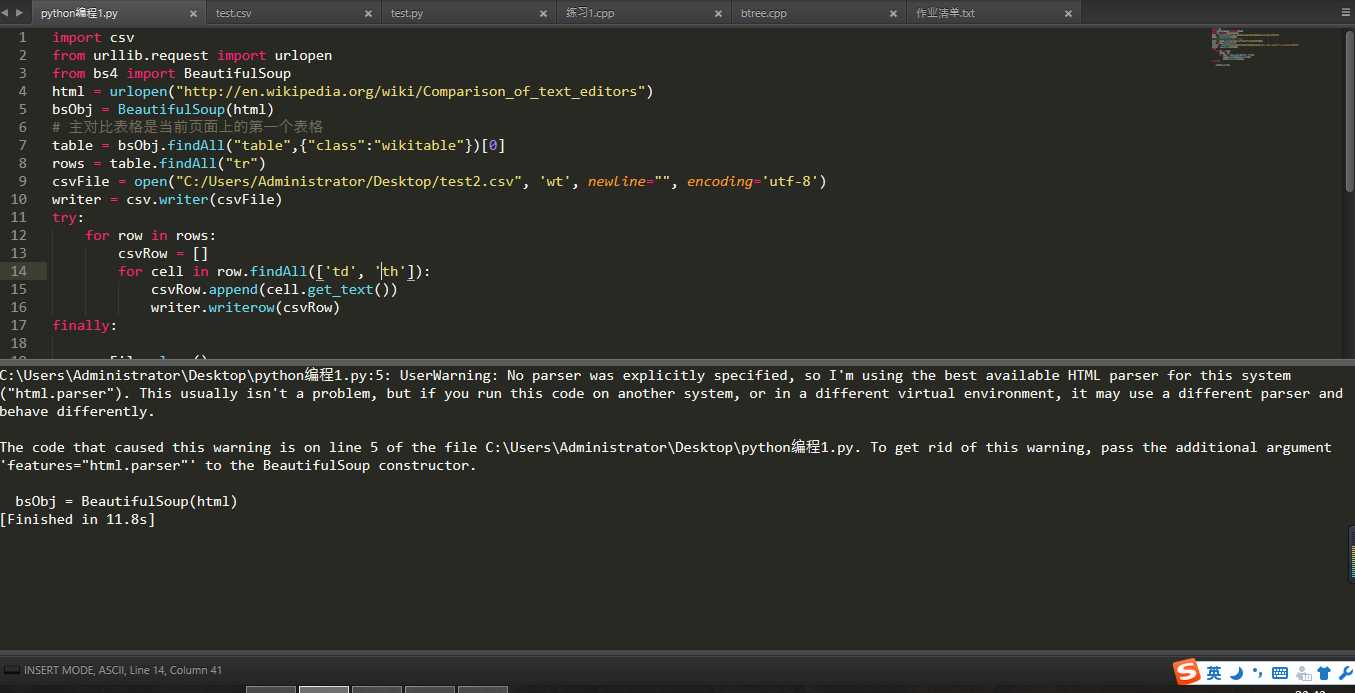
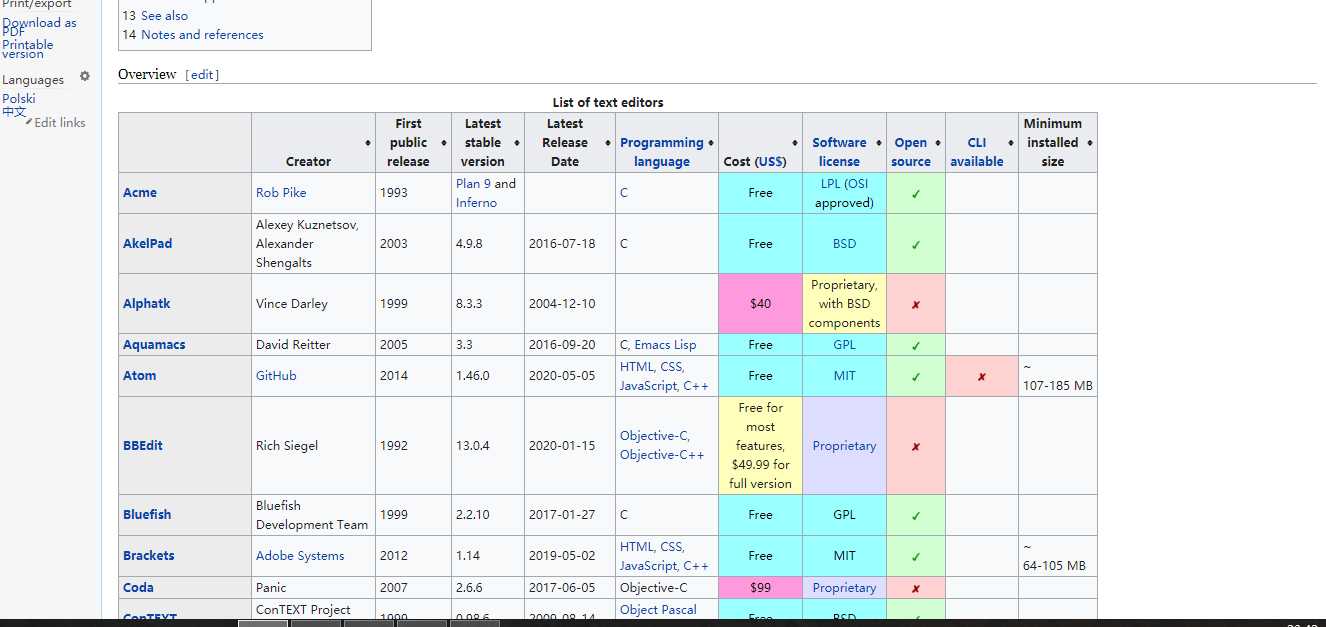
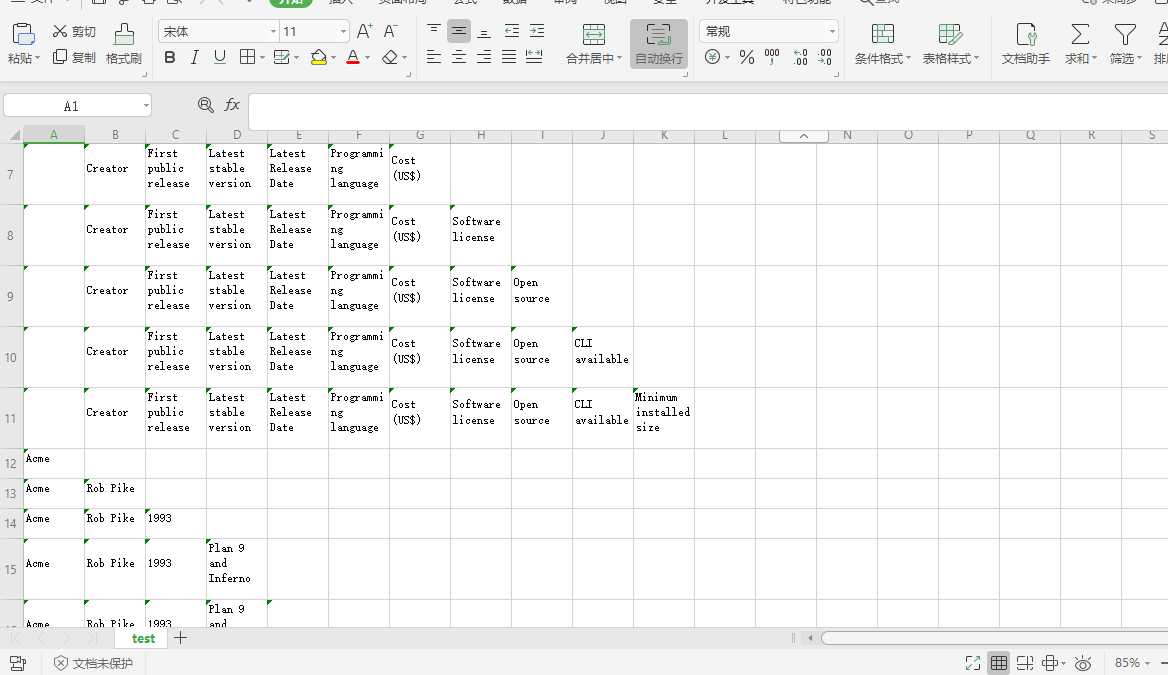
2.网络数据采集的一个常用功能就是获取 HTML 表格并写入 CSV 文件。维基百科的文本编 辑器对比词条(https://en.wikipedia.org/wiki/Comparison_of_text_editors)中用了许多复杂 的 HTML 表格,用到了颜色、链接、排序,以及其他在写入 CSV 文件之前需要忽略的 HTML 元素。用 BeautifulSoup 和 get_text() 函数,你可以用十几行代码完成这件事:
1 import csv 2 from urllib.request import urlopen 3 from bs4 import BeautifulSoup 4 html = urlopen("http://en.wikipedia.org/wiki/Comparison_of_text_editors") 5 bsObj = BeautifulSoup(html) 6 # 主对比表格是当前页面上的第一个表格 7 table = bsObj.findAll("table",{"class":"wikitable"})[0] 8 rows = table.findAll("tr") 9 csvFile = open("C:/Users/Administrator/Desktop/test2.csv", ‘wt‘, newline="", encoding=‘utf-8‘) 10 writer = csv.writer(csvFile) 11 try: 12 for row in rows: 13 csvRow = [] 14 for cell in row.findAll([‘td‘, ‘th‘]): 15 csvRow.append(cell.get_text()) 16 writer.writerow(csvRow) 17 finally: 18 19 csvFile.close()
标签:append 表格 bsp beautiful alt finally img 词条 admin
原文地址:https://www.cnblogs.com/yeu4h3uh2/p/12913893.html