标签:范围 大量 java 新建 eve 计算 rod 方向 images

1、SOA
SOA的提出是在企业计算领域,就是要将紧耦合的系统,划分为面向业务的,粗粒度,松耦合,无状态的服务。
服务发布出来供其他服务调用,一组互相依赖的服务就构成了SOA架构下的系统。
基于这些基础的服务,可以将业务过程用类似BPEL流程的方式编排起来,而BPEL反映的是业务处理的过程,这些过程对于业务人员更为直观,调整也比hardcode的代码更容易。
当然企业还需要对服务治理,比如服务注册库,监控管理等。
我们知道企业计算领域,如果不是交易系统的话,并发量都不是很大的,所以大多数情况下,一台服务器就容纳将许许多多的服务,这些服务采用统一的基础设施,可能都运行在一个应用服务器的进程中。
虽然说是面向服务了,但还是单一的系统。
2、微服务
而微服务架构大体是从互联网企业兴起的,由于大规模用户,对分布式系统的要求很高,如果像企业计算那样的系统,伸缩就需要多个容纳续续多多的服务的系统实例,前面通过负载均衡使得多个系统成为一个集群。
但这是很不方便的,互联网企业迭代的周期很短,一周可能发布一个版本,甚至可能每天一个版本,而不同的子系统的发布周期是不一样的。
而且,不同的子系统也不像原来企业计算那样采用集中式的存储,使用昂贵的Oracle存储整个系统的数据,二是使用
MongoDB,HBase,Cassandra等NOSQL数据库和Redis,
memcache等分布式缓存。
那么就倾向采用以子系统为分割,不同的子系统采用自己的架构,那么各个服务运行自己的Web容器中,当需要增加
计算能力的时候,只需要增加这个子系统或服务的实例就好了,当升级的时候,可以不影响别的子系统。
这种组织方式大体上就被称作微服务架构。 微服务与SOA相比,更强调分布式系统的特性,比如横向伸缩性,服务发
现,负载均衡,故障转移,高可用。
互联网开发对服务治理提出了更多的要求,比如多版本,比如灰度升级,比如服务降级,比如分布式跟踪,这些都是
在SOA实践中重视不够的。
Docker容器技术的出现,为微服务提供了更便利的条件,比如更小的部署单元,每个服务可以通过类似Node.js或
Spring Boot的技术跑在自己的进程中。
可能在几十台计算机中运行成千上万个Docker容器,每个容器都运行着服务的一个实例。随时可以增加某个服务的实
例数,或者某个实例崩溃后,在其他的计算机上再创建该服务的新的实例。
要围绕业务模块进行拆分,拆分粒度应该保证微服务具有业务的独立性与完整性,尽可能少的存在服务依赖,链式调用。
但是,在实际开发过程中,有的时候单体架构更加适合当前的项目。
实际上,微服务的设计并不是一蹴而就的,它是一个设计与反馈过程。
因此,我们在设计之初可以将服务的粒度设计的大一些,并考虑其可扩展性,随着业务的发展,进行动态地拆分也是
一个不错的选择。
REST的名称"表现层状态转化"中,省略了主语。"表现层"其实指的是"资源"(Resources)的"表现层"。
所谓"资源",就是网络上的一个实体,或者说是网络上的一个具体信息。
它可以是一段文本、一张图片、一首歌曲、一种服务,总之就是一个具体的实在。
你可以用一个URI(统一资源定位符)指向它,每种资源对应一个特定的URI。
要获取这个资源,访问它的URI就可以,因此URI就成了每一个资源的地址或独一无二的识别符。
客户端用到的手段,只能是HTTP协议。具体来说,就是HTTP协议里面,四个表示操作方式的动词:GET、POST、
PUT、DELETE。
它们分别对应四种基本操作:GET用来获取资源,POST用来新建资源(也可以用于更新资源),PUT用来更新资源,
DELETE用来删除资源。
实际上呢,不是所有的东西都是“资源”,尤其是在业务系统中,缺点如下:
有个接口是更新订单状态,你是用上面的GET POST PUT DELETE 哪个呢,看样子应该是PUT,但是路径呢PUT /tickets/12
我有时候多个接口 ,更新订单收款状态,更新订单支款状态,更新订单结算状态;
Restful 的路径明显不友好不够用;
再比如,批量删除,DELETE还好用么,DELETE /tickets/12 #删除ticekt 12 这种形式如果要传数组怎么办,url是不是不够友好?
再比如,Resuful要求 GET /tickets # 获取ticket列表 。我们曾经有个需求,对方会把不超过1000个订单id传给我们,我们系统过滤其中一部分特殊订单;这也是个查询服务,用GET /tickets # 获取ticket列表的形式,1000个订单id显然是超过GET url长度的,这里也不合适;再者,我想开发多个条件查询列表服务,路径这么浅显然不合适;
实际业务中,我们webapi的路径是这样的:systemAlias/controller/action
总结下规则:
简单查询尽量用GET,好处是可以直接带查询参数copy api路径;
复杂查询和更新用POST,用的最多;
不用PUT和DELETE,原因是增加复杂度,并没有带来什么好处
看看BAT的很多openapi,也是写着restful,实际没有严格遵守,都是get和post,这是也很多人不知道put和delete的原因
如:

分布式数据管理(CRUD)解决方案之前,有必要介绍下 CAP 原理和最终一致性相关概念。
CAP 原理(CAP Theorem)
在足球比赛里,一个球员在一场比赛中进三个球,称之为帽子戏法(Hat-trick)。在分布式数据系统中,也有一个帽子原理(CAP Theorem),不过此帽子非彼帽子。CAP 原理中,有三个要素:
CAP 原理指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。
因此在进行分布式架构设计时,必须做出取舍。而对于分布式数据系统,分区容忍性是基本要求 ,否则就失去了价值,因此设计分布式数据系统,就是在一致性和可用性之间取一个平衡。
对于大多数 WEB 应用,其实并不需要强一致性,因此牺牲一致性而换取高可用性,是目前多数分布式数据库产品的方向。
当然,牺牲一致性,并不是完全不管数据的一致性,否则数据是混乱的,那么系统可用性再高分布式再好也没有了价值。
牺牲一致性,只是不再要求关系型数 据库中的强一致性,而是只要系统能达到最终一致性即可,考虑到客户体验,这个最终一致的时间窗口,要尽可能的对用户透明,也就是需要保障“用户感知到的一致性”。
通常是通过数据的多份异步复制来实现系统的高可用和数据的最终一致性的,“用户感知到的一致性”的时间窗口则 取决于数据复制到一致状态的时间。
最终一致性(eventually consistent)
对于一致性,可以分为从客户端和服务端两个不同的视角。
从客户端来看,一致性主要指的是多并发访问时更新过的数据如何获取的问题。
从服务端来看,则是更新如何复制分布到整个系统,以保证数据最终一致。
一致性是因为有并发读写才有的问题,因此在理解一致性的问题时,一定要注意结合考虑并发读写的场景。
从客户端角度,多进程并发访问时,更新过的数据在不同进程如何获取的不同策略,决定了不同的一致性。
对于关系型数据库,要求更新过的数据能被后续的 访问都能看到,这是强一致性 ;如果能容忍后续的部分或者全部访问不到,则是弱一致性 ; 如果经过一段时间后要求能访问到更新后的数据,则是最终一致性。
从服务端角度,如何尽快将更新后的数据分布到整个系统,降低达到最终一致性的时间窗口,是提高系统的可用度和用户体验非常重要的方面。
那么问题来了,如何实现数据的最终一致性呢?答案就在事件驱动架构。
在微服务架构中,每个微服务都有自己私有的数据集。不同微服务可能使用不同的SQL或者NoSQL数据库。尽管数据库架构有很强的优势,但是也面对数据分布式管理的挑战。第一个挑战就是如何在多服务之间维护业务数据一致性;第二个挑战是如何从多服务环境中获取一致性数据。
最佳解决办法是采用事件驱动架构。其中碰到的一个挑战是如何原子性的更新状态和发布事件。有几种方法可以解决此问题,包括将数据库视为消息队列和事件源等。
从目前技术应用范围和成熟度看,推荐使用第一种方式(本地事务发布事件),来实现事件投递原子化,即可靠事件投递。
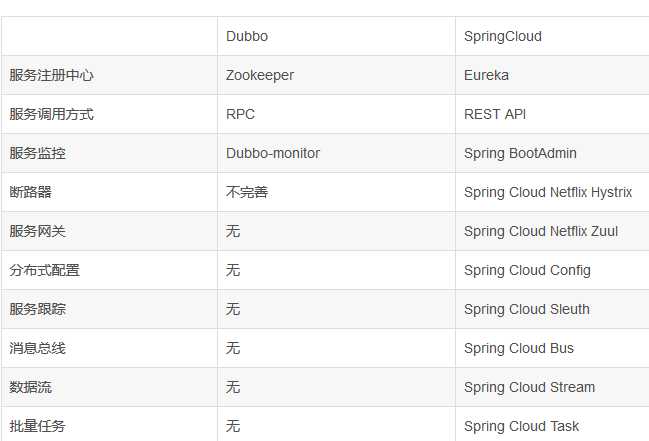
最大区别:SpringCloud抛弃了Dubbo的RPC通信,采用的是基于HTTP的REST方式。
总体来说,两者各有优势。
虽说后者服务调用的功能,但也避免了上面提到的原生RPC带来的问题。而且REST相比RPC更为灵活,服务提供方和调用方的依赖只依靠一纸契约,不存在代码级别的依赖,这在强调快速演化的微服务环境下,显得更加合适。
品牌机与组装机的区别:很明显SpringCloud比dubbo的功能更强大,覆盖面更广,而且能够与SpringFramework、SpringBoot、SpringData、SpringBatch等其他Spring项目完美融合,这些对于微服务至关重要。
使用Dubbo构建的微服务架构就像组装电脑、各环节我们选择自由度高,但是最总可能会因为内存质量而影响整体,但对于高手这也就不是问题。
而SpringCloud就像品牌机,在Spring Source的整合下,做了大量的兼容性测试,保证了机器拥有更高的稳定性。
收集了各方面的,当前公司的,还有自己收集总结的,下面的图片截取的有pdf,有如果有需要的自取.
各大公司面试题集合:
简历模板:


标签:范围 大量 java 新建 eve 计算 rod 方向 images
原文地址:https://www.cnblogs.com/xiaoxu456/p/12916130.html