标签:函数 roo 代码 nts cts acid 维护 head ubi
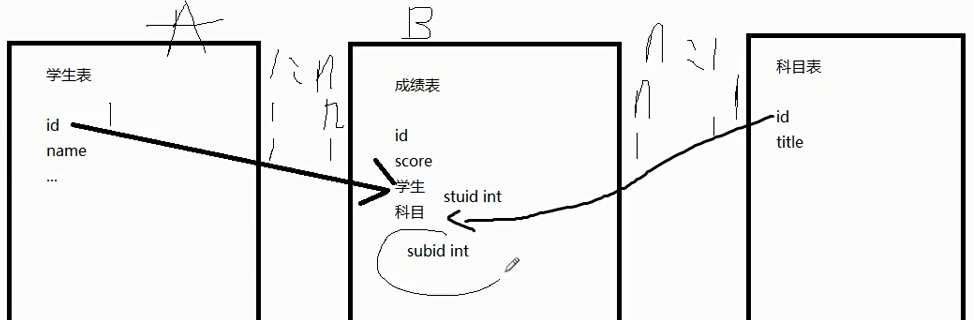
引用主键:把学生表的id引到成绩表。 一个学生对应多个成绩,学生和成绩是一对多,一个科目对应多个学生成绩,所以科目和成绩也是一对多(一对多就把关系字段存储在多的表中,多对对的话就新建一张表存关系)
create table scores(
id int primary key auto_increment,
stuid int,
subid int,
score decimal(5,2)
);
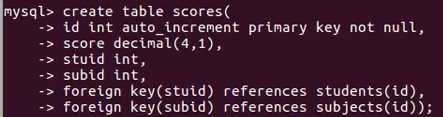
decimal(4,1)一共4位数,小数占一位
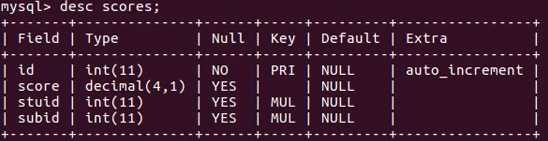
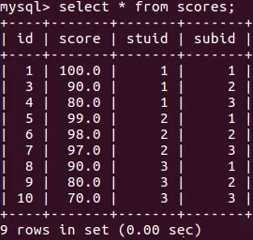
查看表scores的结构
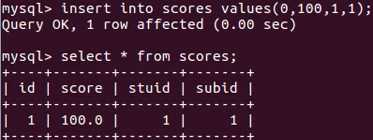
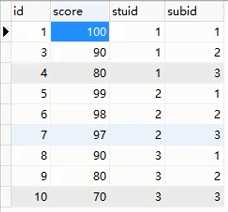
stuid=1的这个学生在subid=1的这个科目考了100分
alter table scores add constraint stu_sco foreign key(stuid) references students(id);
create table scores(
id int primary key auto_increment,
stuid int,
subid int,
score decimal(5,2),
foreign key(stuid) references students(id), foreign key(subid) references subjects(id) );
注:stuid指的是对这个表的哪个字段做外键,reference后边跟的是引用哪个表的哪个字段(一般就是主键)

把第一张表student中id=1的学生删了,那么在第二张表scores中所有stuid=1的学生都无效了,此时该怎么办?级联操作提供了四种方法
alter table scores add constraint stu_sco foreign key(stuid) references students(id) on delete cascade;
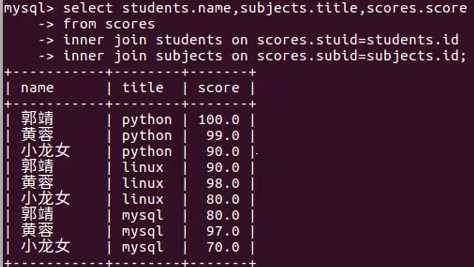
 这样不好看呀,中国人都是记名字,谁去记编号啊
这样不好看呀,中国人都是记名字,谁去记编号啊select students.name,subjects.stitle,scores.score
from scores
inner join students on scores.stuid=students.id
inner join subjects on scores.subid=subjects.id;
join后边写表的名字,on后边写关系(scores和student的关系)
 这样多好看呀!!
这样多好看呀!!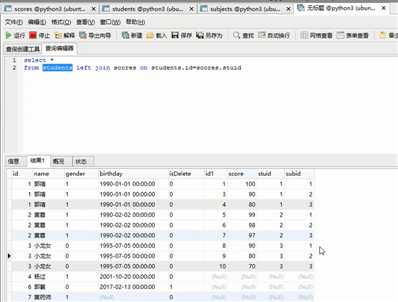
select students.name,avg(scores.score)
from scores
inner join students on scores.stuid=students.id
group by students.sname;
select students.name,avg(scores.score)
from scores
inner join students on scores.stuid=students.id
where students.gender=1
group by students.name;
select subjects.title,avg(scores.score)
from scores
inner join subjects on scores.subid=subjects.id
group by subjects.stitle; 分组操作:把科目相同的扔到一堆然后做聚合(平均)

select subjects.stitle,avg(scores.score),max(scores.score)
from scores
inner join subjects on scores.subid=subjects.id
where subjects.isdelete=0
group by subjects.stitle;


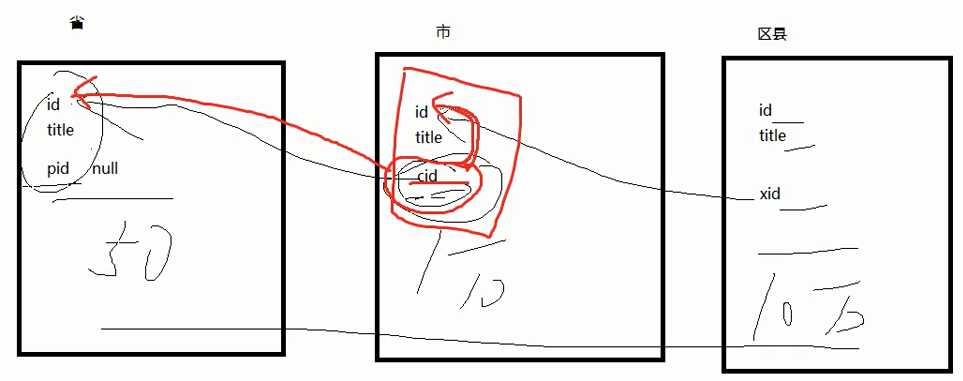
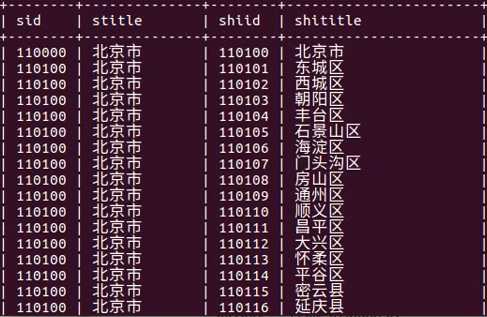
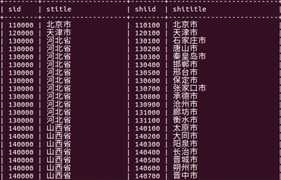
自关联:物理上是一张表,逻辑上是多(三)张表;连接成功就是一张大表(比如学生和成绩在一起的大表)
本表当中的某个字段引用这个表当中的主键(这个表当中的外键引用这个表当中的主键),自关联查询必须起别名(如果都一样都是areas就没法区分谁是谁了)


reference后边跟的是自己,表示自引用
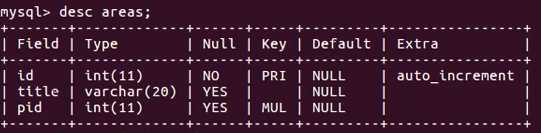
创建表:

查看表:

把areas.sql文件放在桌面上,命令:退到桌面,再连接数据库,再showdatabases,show tables
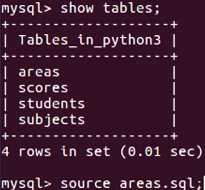


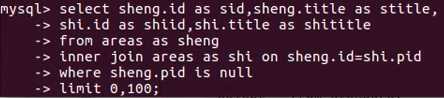
把市过滤掉:
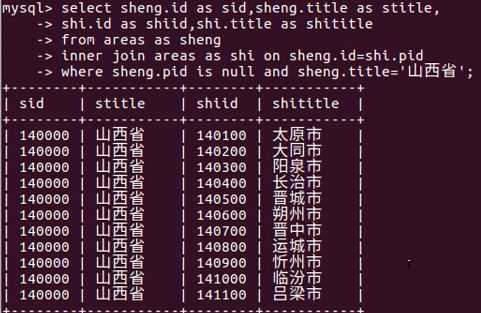
create view stuscore as
select students.*,scores.score from scores
inner join students on scores.stuid=students.id;
stuscore是创建的视图的名字,为了它不和表名冲突,一般这个名字以v开头,视图和表时放在一起的

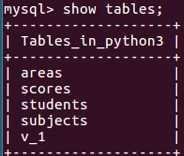
select * from stuscore;这一句就代表刚刚那一大坨代码,如果想修改这个视图用alter

show create table students;
alter table ‘表名‘ engine=innodb;
开启begin;
提交commit;
回滚rollback;
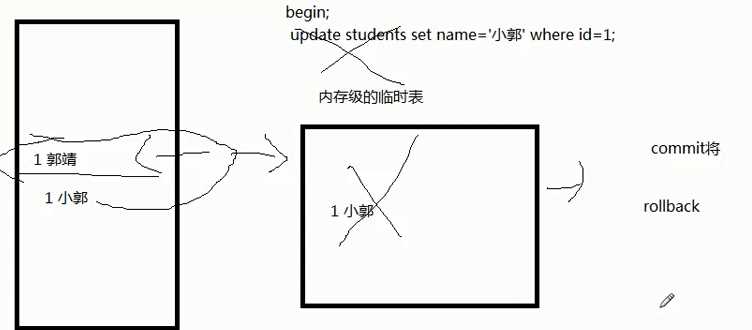
表里有个数据叫1郭靖,比如说要做一个updat操作,首先执行begin把1郭靖这条数据锁起来,想删除修改这个数据都不行,然后在临时的一个表中把数据改成1小郭,再执行commit提交确定刚刚的更改,rollback放弃刚刚的操作(begin后边的 所有操作都放弃)还是原来的数据1郭靖(commit和roolback二选一,要么提交要么放弃)

终端1:
select * from students;
------------------------
终端2:
begin;
insert into students(sname) values(‘张飞‘);
终端1:
select * from students;
终端2:
commit;
------------------------
终端1:
select * from students;
终端1:
select * from students;
------------------------
终端2:
begin;
insert into students(sname) values(‘张飞‘);
终端1:
select * from students;
终端2:
rollback;
------------------------
终端1:
select * from students;标签:函数 roo 代码 nts cts acid 维护 head ubi
原文地址:https://www.cnblogs.com/fenglivoong/p/12916236.html