标签:多表连接 方式 where alter 空值 lap 结构化 cat 需求
mysql常用参数:
-u? ? ? ? ? ? ?用户
-p? ? ? ? ? ? ?密码
-h? ? ? ? ? ? ?IP
-P? ? ? ? ? ? ?端口
-S? ? ? ? ? ? ?socket文件
-e? ? ? ? ? ? ?免交互执行命令
<? ? ? ? ? ? ? 导入SQL脚本
例子:
[root@db01 ~]# mysql -uroot -p -e "show databases;"

结构化的查询语言
关系型数据库通用的命令
遵循SQL92的标准(SQL_MODE)
DDL 数据定义语言 ???? create 和 drop
DCL 数据控制语言 grant 和 revoke
DML 数据操作语言 insert update 和 delete
DQL 数据查询语言???? select 和 show
库
库名字
库属性:字符集,排序规则
表
表名
表属性:存储引擎类型,字符集,排序规则
列名
列属性:数据类型,约束,其他属性
数据行
相当于MySQL的密码本(编码表)
show charset;
utf8 : 3个字节
utf8mb4 (建议): 4个字节,支持emoji
mysql> show collation;
对于英文字符串的,大小写的敏感
utf8mb4generalci 大小写不敏感
utf8mb4_bin 大小写敏感(存拼音,日文)
保证数据的正确性和标准性
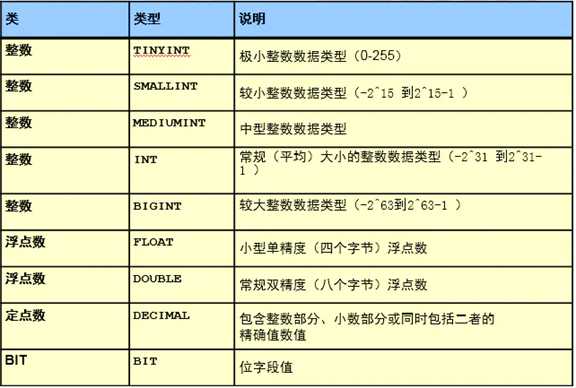
整数
tinyint : -128~127
int :-231~231-1
浮点数
略
说明:手机号是无法存储到int的。一般是使用char类型来存储收集号
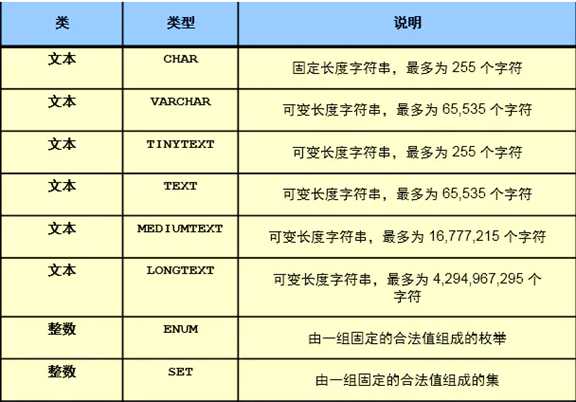
char(100)
定长字符串类型,不管字符串长度多长,都立即分配100个字符长度的存储空间,未占满的空间使用"空格"填充
varchar(100)
变长字符串类型,每次存储数据之前,都要先判断一下长度,按需分配此盘空间.
会单独申请一个字符长度的空间存储字符长度(少于255,如果超过255以上,会占用两个存储空间)
如何选择这两个数据类型?
enum 枚举数据类型
address enum(‘sz‘,‘sh‘,‘bj‘.....)
1 2 3
悬念,以上数据类型可能会影响到索引的性能
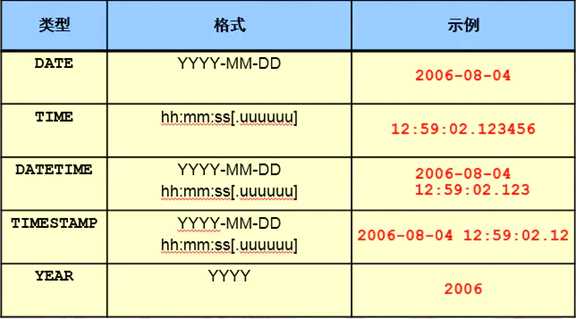
datetime
范围为从 1000-01-01 00:00:00.000000 至 9999-12-31 23:59:59.999999。
timestamp
范围为从 1970-01-01 00:00:00.000000 至 2038-01-19 03:14:07.999999。
列值不能为空,也是表设计的规范,尽可能将所有的列设置为非空。可以设置默认值为0
unique key :唯一键
列值不能重复
unsigned :无符号
针对数字列,非负数。
其他属性:
key :索引
可以在某列上建立索引,来优化查询
CREATE DATABASE zabbix CHARSET utf8mb4 COLLATE utf8mb4_bin;
SHOW DATABASES;
SHOW CREATE DATABASE zabbix;
DROP DATABASE syxk;
注意: 一定是从小往大了改,比如utf8--->utf8mb4.
目标字符集一定是源字符集的严格超级.
CREATE DATABASE syxk;
SHOW CREATE DATABASE syxk;
ALTER DATABASE syxk CHARSET utf8mb4;
1.库名使用小写字符
2.库名不能以数字开头
3.不能是数据库内部的关键字
4.必须设置字符集.
表名,列名,列属性,表属性
create table stu(
列1 属性(数据类型、约束、其他属性),
列2 属性,
列3 属性
)
PRIMARY KEY : 主键约束,表中只能有一个,非空且唯一.
NOT NULL : 非空约束,不允许空值
UNIQUE KEY : 唯一键约束,不允许重复值
DEFAULT : 一般配合 NOT NULL 一起使用.
UNSIGNED : 无符号,针对数字列,非负数
COMMENT : 注释
AUTO_INCREMENT : 自增长的列
1. 表名小写字母,不能数字开头,
2. 不能是保留字符,使用和业务有关的表名
3. 选择合适的数据类型及长度
4. 每个列设置 NOT NULL + DEFAULT .对于数据0填充,对于字符使用有效字符串填充
5. 没个列设置注释
6. 表必须设置存储引擎和字符集
7. 主键列尽量是无关列数字列,最好是自增长
8. enum类型不要保存数字,只能是字符串类型
CREATE TABLE stu (
id INT PRIMARY KEY NOT NULL AUTO_INCREMENT COMMENT ‘学号‘,
sname VARCHAR(255) NOT NULL COMMENT ‘姓名‘,
age TINYINT UNSIGNED NOT NULL DEFAULT 0 COMMENT ‘年龄‘,
gender ENUM(‘m‘,‘f‘,‘n‘) NOT NULL DEFAULT ‘n‘ COMMENT ‘性别‘,
intime DATETIME NOT NULL DEFAULT NOW() COMMENT ‘入学时间‘
)ENGINE INNODB CHARSET utf8mb4 COMMENT ‘学生表‘;
SHOW TABLES;
SHOW CREATE TABLE stu;
DESC stu; #查看表结构
CREATE TABLE test LIKE stu;
DROP TABLE test;
1.在stu表中添加qq列
DESC stu;
ALTER TABLE stu ADD qq VARCHAR(20) NOT NULL COMMENT ‘qq号‘;
2.在sname后加微信列
ALTER TABLE stu ADD wechat VARCHAR(64) NOT NULL UNIQUE COMMENT ‘微信号‘ AFTER sname;
3.在id列前加一个新列num
ALTER TABLE stu ADD num INT NOT NULL UNIQUE COMMENT ‘身份证‘ FIRST ;
DESC stu;
4.把刚才添加的列都删掉(危险,生产中禁用操作)
ALTER TABLE stu DROP num;
DESC stu;
ALTER TABLE stu DROP qq;
ALTER TABLE stu DROP wechat;
5.修改sname数据类型的属性
DESC stu;
ALTER TABLE stu MODIFY sname VARCHAR(64) NOT NULL COMMENT ‘姓名‘;
6.将gender 改为 sex 数据类型改为 CHAR 类型 ***
ALTER TABLE stu CHANGE gender sex CHAR(4) NOT NULL COMMENT ‘性别‘;
说明:修改字符集,修改后的字符集一定是原字符集的严格超集
情况1:ALTER 语句是在原有数据的表中增加一个列,是需要对表结构进行更改,如果在生产环境中,这个表有可能是在频繁的访问的,还可能有一堆的业务过来,比如往里面插入行(增删改查),这种在线更改的DDL语句,是会进行锁表操作的。也就是这种语句是不合适在一个繁忙的时刻操作的(一定要避开生产的繁忙时刻) (建议:避开业务繁忙期)
情况 2:若紧急上线。操作流程
方式一:先将表的数据创建一个临时表,就是一模一样的表,copy出来(copy是不会锁表的,等于复制了一份,生成一个临时表)。然后进行临时表的变更,最后对原表进行替换。
方式二:pt-osc (工具)进行在线DDL,解决锁表的时间(另外8.0版本已经解决了这个问题)
?
mysql> grant SELECT,INSERT,UPDATE,DELETE on wordpress.* to wordpress@‘10.0.0.%‘ identified by ‘123‘;
mysql> revoke delete on wordpress.* from ‘wordpress‘@‘10.0.0.%‘;
mysql> show grants for wordpress@‘10.0.0.%‘;
DESC stu;
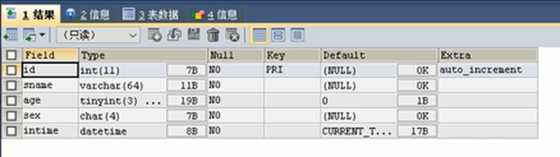
1.最偷懒
INSERT stu VALUES(1,‘zs‘,18,‘m‘,NOW());
SELECT * FROM stu;
2.最规范
INSERT INTO stu(id,sname,age,sex,intime)
VALUES (2,‘ls‘,19,‘f‘,NOW());
3.针对性的录入数据
INSERT INTO stu(sname,age,sex)
VALUES (‘w5‘,11,‘m‘);
4.一次性录入多行
INSERT INTO stu(sname,age,sex)
VALUES
(‘aa‘,11,‘m‘),
(‘bb‘,12,‘f‘),
(‘cc‘,13,‘m‘);
UPDATE stu SET sname=‘aaa‘;
SELECT * FROM stu;
UPDATE stu SET sname=‘bb‘ WHERE id=6;
DELETE FROM stu;
DELETE FROM stu WHERE id=9;
生产中屏蔽delete功能
使用update替代delete
ALTER TABLE stu ADD isdel TINYINT DEFAULT 0 ;
UPDATE stu SET isdel=1 WHERE id=7;
SELECT * FROM stu WHERE is_del=0;
select
show
mysql> select @@basedir; #查看软件安装目录
mysql> select @@port; #查看当前数据库的端口
mysql> select @@innodb_flush_log_at_trx_commit;
mysql> show variables like ‘innodb%‘; #模糊查询
mysql> select database(); #查看当前的库
mysql> select now(); #查看当前的时间
select 列1,列2 from 表 where 条件 group by 条件 having 条件 order by 条件 limit
select user,count(name) from 表 where 列 group by user having 列 order by 列 limit;
语句顺序即如下:(不能乱)
可以单独使用.但这个顺序不能乱,不然语法错误。
select 列
from 表
where 条件
group by 条件
having 条件
order by 条件
limit
World 数据库
city 城市表
country 国家表
countrylanguage 国家的语言
city表结构 desc city;
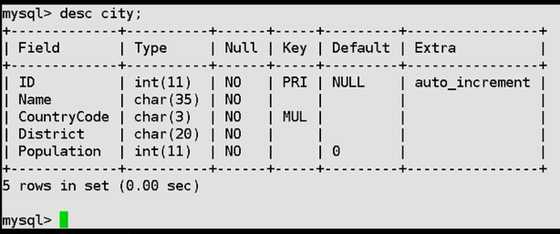
ID : 城市序号/ID(1-...)
name : 城市名字
countrycode : 国家代码,例如:CHN,USA
district : 区域: 中国
省
美国
洲
population : 人口数
如何熟悉数据库业务?
select 列,列,列 from 表
例子:
select 列,列,列 from 表 where 过滤条件
查询中国所有的城市名和人口数
SELECT NAME,population FROM city
WHERE countrycode=‘CHN‘;
世界上小于100人的城市名和人口数
SELECT NAME,population FROM city
查询中国人口数量大于1000w的城市名和人口
SELECT NAME,population FROM city
WHERE countrycode=‘CHN‘ AND population>8000000;
查询中国或美国的城市名和人口数
SELECT NAME,population FROM city
WHERE countrycode=‘CHN‘ OR countrycode=‘USA‘;
查询人口数量在500w到600w之间的城市名和人口数
SELECT NAME,population FROM city
WHERE population>5000000 AND population<6000000;
或者:
SELECT NAME,population FROM city
WHERE population BETWEEN 5000000 AND 6000000;
查询一下contrycode中带有CH开头,城市信息
SELECT * FROM city
WHERE countrycode LIKE ‘CH%‘;
注意:不要出现类似于 %CH%,前后都有百分号的语句,因为不走索引,性能极差
如果业务中有大量需求,我们用"ES(数据库)"来替代
例子:
查询中国或美国的城市信息.
SELECT NAME,population FROM city
WHERE countrycode=‘CHN‘ OR countrycode=‘USA‘;
或者:
SELECT NAME,population FROM city
WHERE countrycode IN (‘CHN‘ ,‘USA‘);
作用:根据 by后面的条件进行分组,方便统计,by后面跟一个列或多个列。
常用的聚合函数:
max():最大值
min():最小值
avg():平均值
sum():总和
count():个数
group_concat():该函数返回带有来自一个组的连接的非NULL值的字符串结果。(列转行)
在数据表中1对多是不允许的。如:
name age
张三 14
张三 15
在实际生活中,类似这种重名的现象是有的。但将其转为1行显示,及
name age
张三 14,15
这一种现象是不被允许的,在数据表中都是1对1的关系存储。遇见这类情况就需要使用到聚合函数group_concat().
GROUP BY + 聚合函数公式:
1.遇到统计想函数
2.形容词前 GROUP BY
3.函数中央是名词
4.列名select后添加
GROUP BY将某列中有共同条件的数据行,分成一组,然后在进行聚合函数操作.
例子:
语句顺序:where之后是group之后是having.不能是having之后有group
例子:
1.统计所有国家的总人口数量,将总人口数大于1亿的过滤出来。
SELECT countrycode.SUM(population) FROM city GROUP BY countrycode
HAVING SUM(population)>100000000;
例子:
DESC :从大到小
ASC : 从小到大
例子:
SELECT countrycode,SUM(population) FROM city
GROUP BY countrycode
HAVING SUM(population)>50000000
ORDER BY SUM(population) DESC
LIMIT 3;
SELECT countrycode,SUM(population) FROM city
GROUP BY countrycode
HAVING SUM(population)>50000000
ORDER BY SUM(population) DESC
LIMIT 3,3; #跳过前三行(从第四行开始),一共显示三行。
SELECT countrycode,SUM(population) FROM city
GROUP BY countrycode
HAVING SUM(population)>50000000
ORDER BY SUM(population) DESC
LIMIT 3 OFFSET 3;
LIMIT M,N : 跳过M行,显示一共N行
LIMIT Y OFFSET X: 跳过X行,显示一共Y行
统计中国每个省的城市个数,只要大于10个的,从大到小排序前三名。
select disctrict , count(name) from city
where countrycode=‘CHN‘
group by district
having count(name) >10
order by count(name) desc
limit 3;
mysql> SELECT countrycode FROM city ;
mysql> SELECT DISTINCT(countrycode) FROM city ;
mysql> select count(distinct countrycode) from city;
作用: 多个结果集合并查询的功能
需求: 查询中国或者美国的城市信息
SELECT * FROM city WHERE countrycode=‘CHN‘ OR countrycode=‘USA‘;
改写为:
SELECT * FROM city WHERE countrycode=‘CHN‘
UNION ALL
SELECT * FROM city WHERE countrycode=‘USA‘;
说明:union 和 union all 的区别 ?
union 去重复
union all 不去重复
说明:一般情况下,我们会将IN或者OR语句改写成UNION ALL,来提高性能。
1、mysql> select concat(user,"@",host) from mysql.user;
show databases; ???? 查看数据库名
show tables; ???????? ???? 查看表名
show create database xx; ???? 查看建库语句
show create table xx;???? 查看建表语句
show processlist;???????? 查看所有用户连接情况
show charset;???????? 查看支持的字符集
show collation;???????? 查看所有支持的校对规则
show grants for xx;???? 查看用户的权限信息
show variables like ‘%xx%‘ 查看参数信息
show engines;???????? 查看所有支持的存储引擎类型
show index from xxx???? 查看表的索引信息
show engine innodb status\G 查看innoDB引擎详细状态信息
show binary logs ???? 查看二进制日志的列表信息
show binlog events in ‘‘???? 查看二进制日志的事件信息
show master status ;???? 查看mysql当前使用二进制日志信息
show slave status\G 查看从库状态信息
show relaylog events in ‘‘ ???? 查看中继日志的事件信息
show status like ‘‘???????? 查看数据库整体状态信息
单表数据不能满足查询需求时.
例子: 查询世界上小于100人的城市,所在的国家名,国土面积,城市名,人口数
引入:
第一张表city:
SELECT countrycode,NAME,population FROM city WHERE population<100;
#查city表得到,如下:
PCN
Adamstown
42
第二张表country:
DESC country; #查看country表结构,得到下面有效的列与第一张表有关联。
CODE
NAME
SurfaceArea
SELECT NAME,SurfaceArea FROM country WHERE CODE=‘PCN‘;
#查country表得到,如下:
Pitcairn
49.00
语法规则:
1.首先找涉及到的所有表
2.找到表和表之间的关联列
3.关联条件写在on后面
A join B on 关联列
4.所有需要查询的信息放在select后
5.其他的过滤条件where group by having order by limit 往最后放
6.注意:对多表连接中,驱动表选择数据行少的表。后续所有表的关联列尽量是主键或唯一键(表设计),至少建立一个索引。
要求:
1、最核心的是,找到多张表之前的关联条件列
2、列书写时,必须是:表名.列
3、所有涉及到的查询列,都放在select后
4、将所有的过滤,分组,排序等条件按顺序写在on的后面
SELECT ???????????????????? ????????#查询 SELECT
country.name, ????????????????#国家名
表名.列
country.SurfaceArea, ????????????????#国土面积
表名.列
city.name, ????????????????#城市名
表名.列
city.Population ????????????????#人口数
表名.列
FROM city ????????????????#FROM 表A
JOIN country ????????????????#JOIN 表B
ON city.CountryCode = country.code ???? #ON 表A.列X = 表B.列Y
WHERE city.population<100;
?
5、多张表
SELECT
XXX.XXX
XXX.XXX
FROM A #表A
JOIN B #表B
ON A.X = B.Y
JOIN C #表C
ON B.M = C.N
?
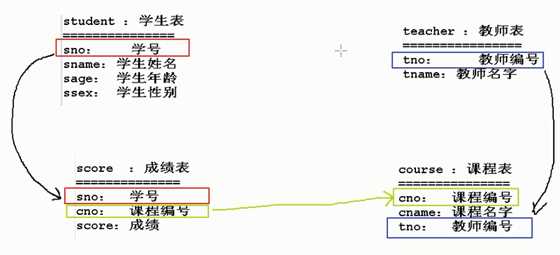
案例准备:学生管理系统
use school
student :学生表
===============
sno :学号
sname :学生姓名????
sage :学生年龄
ssex :学生性别
teacher :教师表
===============
tno :教师编号
tname :教师名字
course :课程表
===============
cno :课程编号
cname :课程名字
tno :教师编号
score :成绩表
===============
sno :学号
cno :课程编号
score :成绩
-- 项目构建
drop database school;
CREATE DATABASE school CHARSET utf8;
USE school
CREATE TABLE student(
sno INT NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT ‘学号‘,
sname VARCHAR(20) NOT NULL COMMENT ‘姓名‘,
sage TINYINT UNSIGNED NOT NULL COMMENT ‘年龄‘,
ssex ENUM(‘f‘,‘m‘) NOT NULL DEFAULT ‘m‘ COMMENT ‘性别‘
)ENGINE=INNODB CHARSET=utf8;
CREATE TABLE course(
cno INT NOT NULL PRIMARY KEY COMMENT ‘课程编号‘,
cname VARCHAR(20) NOT NULL COMMENT ‘课程名字‘,
tno INT NOT NULL COMMENT ‘教师编号‘
)ENGINE=INNODB CHARSET utf8;
CREATE TABLE sc (
sno INT NOT NULL COMMENT ‘学号‘,
cno INT NOT NULL COMMENT ‘课程编号‘,
score INT NOT NULL DEFAULT 0 COMMENT ‘成绩‘
)ENGINE=INNODB CHARSET=utf8;
CREATE TABLE teacher(
tno INT NOT NULL PRIMARY KEY COMMENT ‘教师编号‘,
tname VARCHAR(20) NOT NULL COMMENT ‘教师名字‘
)ENGINE=INNODB CHARSET utf8;
INSERT INTO student(sno,sname,sage,ssex)
VALUES (1,‘zhang3‘,18,‘m‘);
INSERT INTO student(sno,sname,sage,ssex)
VALUES
(2,‘zhang4‘,18,‘m‘),
(3,‘li4‘,18,‘m‘),
(4,‘wang5‘,19,‘f‘);
INSERT INTO student
VALUES
(5,‘zh4‘,18,‘m‘),
(6,‘zhao4‘,18,‘m‘),
(7,‘ma6‘,19,‘f‘);
INSERT INTO student(sname,sage,ssex)
VALUES
(‘oldboy‘,20,‘m‘),
(‘oldgirl‘,20,‘f‘),
(‘oldp‘,25,‘m‘);
INSERT INTO teacher(tno,tname) VALUES
(101,‘oldboy‘),
(102,‘hesw‘),
(103,‘oldguo‘);
DESC course;
INSERT INTO course(cno,cname,tno)
VALUES
(1001,‘linux‘,101),
(1002,‘python‘,102),
(1003,‘mysql‘,103);
DESC sc;
INSERT INTO sc(sno,cno,score)
VALUES
(1,1001,80),
(1,1002,59),
(2,1002,90),
(2,1003,100),
(3,1001,99),
(3,1003,40),
(4,1001,79),
(4,1002,61),
(4,1003,99),
(5,1003,40),
(6,1001,89),
(6,1003,77),
(7,1001,67),
(7,1003,82),
(8,1001,70),
(9,1003,80),
(10,1003,96);
SELECT * FROM student;
SELECT * FROM teacher;
SELECT * FROM course;
SELECT * FROM sc;
关联关系:
1.统计zhang3,学习了几门课
看题意:就两张表
即:student表
和 course课程表,但这两张表之间没有关联。需要通过score成绩表来进行关联。
所以:共需要三张表,即: student表 score成绩表 course课程表。
但‘几门课‘这个可以通过有‘几门成绩‘来判断有几门课。
最终确认:需要的是student表
和 score成绩表
SELECT student.sname,COUNT(sc.cno)
FROM student JOIN sc
ON student.sno=sc.sno
WHERE student.sname=‘zhang3‘
GROUP BY student.sno;
2.查询zhang3,学习的课程名称有哪些?
SELECT student.sname,course,cname
FROM student
JOIN sc
ON student.sno=sc.sno
JOIN course
ON sc.cno=course.cno
WHERE student.sname=‘zhang3‘; #列显示结果
SELECT student.sname,GROUP_CONCAT(course,cname)
FROM student
JOIN sc
ON student.sno=sc.sno
JOIN course
ON sc.cno=course.cno
WHERE student.sname=‘zhang3‘
GROUP BY student.sname; #GROUP_CONCAT 列转行
行显示结果
3.查询oldguo老师教的学生名和个数.
SELECT teacher.tname,GROUP_CONCAT(student.sname),COUNT(student.sname)
FROM teacher
JOIN course
ON teacher.tno=course.tno
JOIN sc
ON course.cno=sc.cno
JOIN student
ON sc.sno=student.sno
WHERE teacher.tname = ‘oldguo‘
GROUP BY teacher.tname;
4.查询oldguo所教课程的平均分数
SELECT teacher.tname,AVG(sc.score)
FROM teacher
JOIN course
on teacher.tno = course.tno
JOIN sc
ON course.cno = sc.cno
WHERE teacher.tname = ‘oldguo‘
GROUP by sc.cno;
5.每位老师所教课程的平均分,并按平均分排序
SELECT teacher.tname,course,cname,AVG(sc.score)
FROM teacher
JOIN course
ON teacher.tno = course.tno
JOIN sc
ON course.cno=sc.cno
GROUP BY teacher.tname,course,cname
ORDER BY AVG(sc.score);
6.查询oldguo所教的不及格的学生姓名
SELECT teacher.tname,student.sname,sc.score
FROM teacher
JOIN course
on teacher.tno = course.tno
JOIN sc
ON course.cno = sc.cno
JOIN student
ON sc.sno=student.sno
WHERE teacher.tname = ‘oldguo‘ AND sc.score<60;
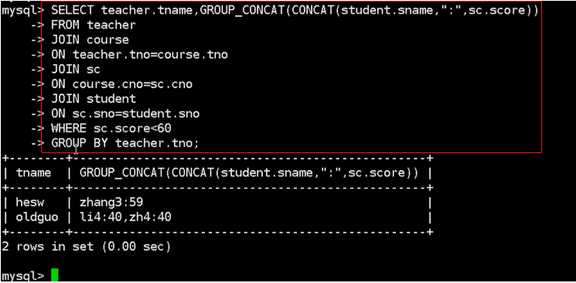
7.查询所有老师所教学生不及格的信息
SELECT teacher.tname,group_CONCAT(student.sname,sc.score)
FROM teacher
JOIN course
on teacher.tno = course.tno
JOIN sc
ON course.cno = sc.cno
JOIN student
ON sc.sno=student.sno
GROUP BY teacher.tno
HAVING sc.score<60;
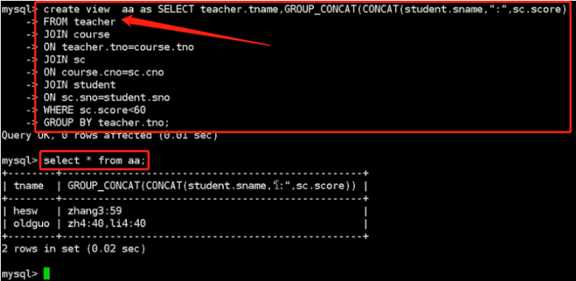
SELECT teacher.tname,group_CONCAT(CONCAT(student.sname,":",sc.score)) AS 不及格的
FROM teacher
JOIN course
on teacher.tno = course.tno
JOIN sc
ON course.cno = sc.cno
JOIN student
ON sc.sno=student.sno
WHERE sc.score<60
GROUP BY teacher.tno;
?
1.别名语法
列别名,表别名
SELECT
a.Name AS an,
b.name AS bn,
b.SurfaceArea AS bs,
a.Population AS bp
FROM city AS a JOIN country AS b
ON a.CountryCode=b.Code
WHERE a.name =‘shenzheng‘;
注意说明:可以不带as.
2.表别名
SELECT t.tname,group_CONCAT(CONCAT(st.sname,":",sc.score))
FROM teacher as t
JOIN course as c
on t.tno = c.tno
JOIN sc
ON c.cno = sc.cno
JOIN student as st
ON sc.sno=st.sno
WHERE sc.score<60
GROUP BY t.tno;
注意说明:表别名是全局调用的.
3.列别名
SELECT t.tname as 讲师名 ,group_CONCAT(CONCAT(st.sname,":",sc.score)) as 不及格的
FROM teacher as t
JOIN course as c
on t.tno = c.tno
JOIN sc
ON c.cno = sc.cno
JOIN student as st
ON sc.sno=st.sno
WHERE sc.score<60
GROUP BY t.tno;
注意说明:列别名可以被 having 和 order by 调用
4.查询一下世界上人口数量小于100人的城市名和国家名
SELECT b.name,a.name,a.population
FROM city AS a
JOIN country AS b
ON b.code=a.countrycode
WHERE a.Population<100
5.查询城市shenzhen,城市人口,所在国家名(name)及国土面积(SurfaceArea)
SELECT a.name,a.population,b.name,b.SurfaceArea
FROM city AS a
JOIN country AS b
ON a.countrycode=b.code
WHERE a.name=‘shenzhen‘;
6.场景:有可能syxk跟syxk并不是同一个人,名字重名.
Name(名字) | Course(学科) | Count |
syxk | linux | a,b,c,d |
syxk | python | x,y,z |
syxk | linux | 10 |
hsw | python | 11 |
元数据是存储在"基表"中。
通过专用的DDL语句,DCL语句进行修改 。
通过专用视图和命令进行元数据的查询 。
information_schema中保存了大量元数据查询的视图。
而show 命令是封装好功能,提供元数据查询基础功能
tables 视图的应用
mysql> use information_schema;
mysql> desc tables;
常用的列举如下:
TABLE_SCHEMA 表所在的库名
TABLE_NAME???? 表名
ENGINE???????? 存储引擎
TABLE_ROWS???? 表的行数
AVG_ROW_LENGTH 表中行的平均行(字节)
INDEX_LENGTH 索引长度(索引的占用空间大小 字节)
示例:
USE information_schema;
DESC TABLES;
1. 显示所有的库和表的信息
SELECT table_schema,table_name FROM information_schema.tables;
2. 以以下模式显示所有的库和表的信息
world city,country,countrylanguage
SELECT table_schema,GROUP_CONCAT(table_name)
FROM information_schema.tables
GROUP BY table_schema; #将列转行显示,合并到一行。
3. 查询所有innodb引擎的表
SELECT table_schema,table_name,ENGINE
FROM information_schema.tables
WHERE ENGINE=‘innodb‘;
4. 统计world下的city表占用空间大小
表的数据量=平均行长度*行数 + 索引长度
AVG_ROW_LENGTH*TABLE_ROWS+INDEX_LENGTH
SELECT table_name,(AVG_ROW_LENGTH*TABLE_ROWS+INDEX_LENGTH)/1024
FROM information_schema.TABLES
WHERE table_schema=‘world‘ AND table_name=‘city‘;
5.统计world库数据量总大小
SELECT table_schema,SUM((AVG_ROW_LENGTH*TABLE_ROWS+INDEX_LENGTH))/1024
FROM information_schema.TABLES
WHERE table_schema=‘world‘;
6.统计每个库的数据量大小,并按数据量从大到小排序
SELECT table_schema,SUM((AVG_ROW_LENGTH*TABLE_ROWS+INDEX_LENGTH))/1024 AS total_KB
FROM information_schema.TABLES
GROUP BY table_schema
ORDER BY total_KB DESC;
7.配合concat()函数拼接语句或命令
示例:
1.模仿以下语句,进行数据库的分库分表备份。
mysqldump -uroot -p123 world city >/bak/world_city.sql #world 库名 city 表名
?
SELECT
CONCAT("mysqldump -uroot -p123",table_schema," ",table_name
," >/bak/",table_schema,"_",table_name,".sql")
FROM information_schema.tables;
2.模仿以下语句,进行批量生成对world库下所有表进行操作
ALTER TABLE world.city DISCARD TABLESPACE;
?
SELECT
CONCAT("ALTER TABLE ",table_schema,".",table_name," DISCARD TABLESPACE;")
FROM information_schema.tables
WHERE table_schema=‘world‘;
标签:多表连接 方式 where alter 空值 lap 结构化 cat 需求
原文地址:https://www.cnblogs.com/SyXk/p/12920595.html