标签:好的 二层 像素 聚类 尺度 关联 假设 src 正则
googleNet是2014年的ILSVRC的冠军模型,GoogleNet做了更大胆的网络上的尝试,而不是像vgg继承了lenet以及alexnet的一切框架。GoogleNet虽然有22层,但是参数量只有AlexNet的1/12
GoogleNet论文指出获得高质量模型最保险的做法就是增加模型的深度,或者是它的宽度,但是一般情况下,更深和更宽的网络会出现以下问题:
总之更大的网络容易产生过拟合,并且增加了计算量
GoogleNet给出的解决方案:
GoogleNet为了保持神经网络结构的稀疏性,又能充分利用密集矩阵的高计算性能,提出了名为Inception的模块化结构来实现此目的。依据就是大量文献都表明,将稀疏矩阵聚类为比较密集的子矩阵可以提高计算性能。(这一块我没有很明白,是百度到的知识,但是关键在于GoogleNet提出了Inception这个模块化结构,在2020年的今日,这个模块依然有巨大作用)
这是一种王中王结构,哦不,是网中网结构(Network in Network)。就是原来的节点也是一个网络,使用了Inception,这个网络结构的宽度和深度都可以扩大。从而带来性能的提升。
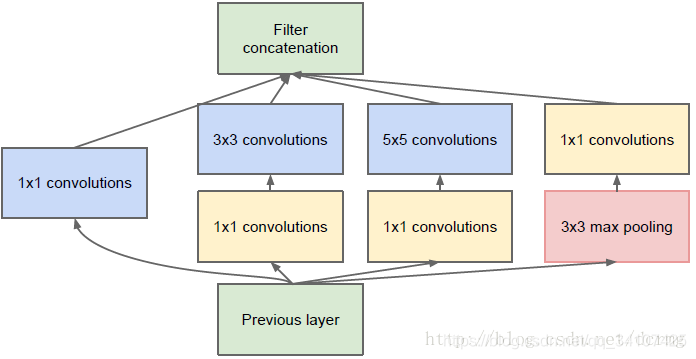
解释说明:
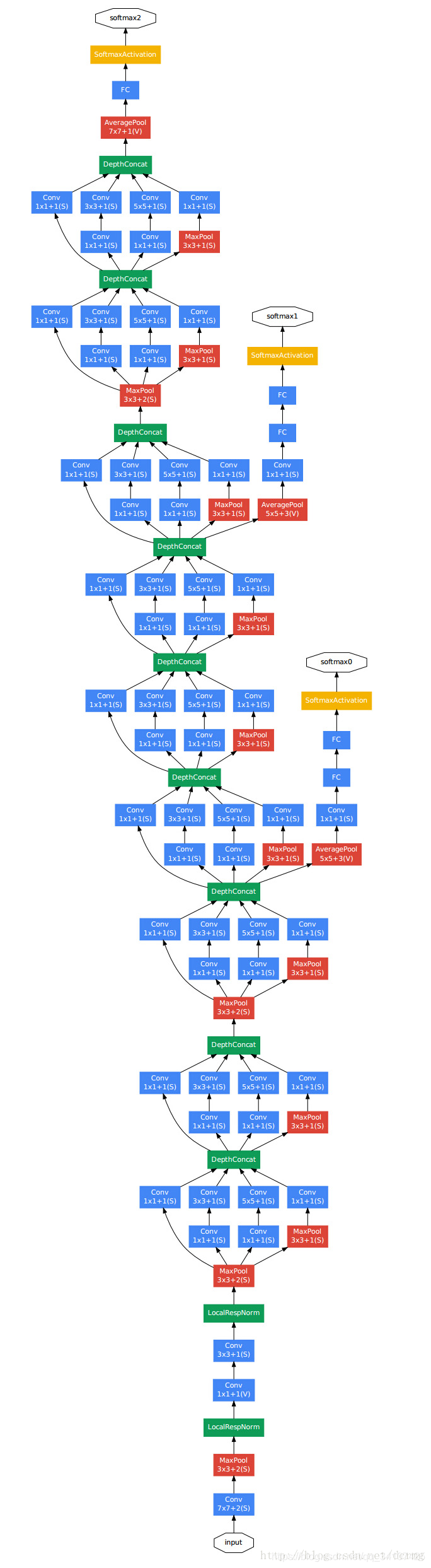
从网上找了一张GoogleNet的美图:
还有一个:
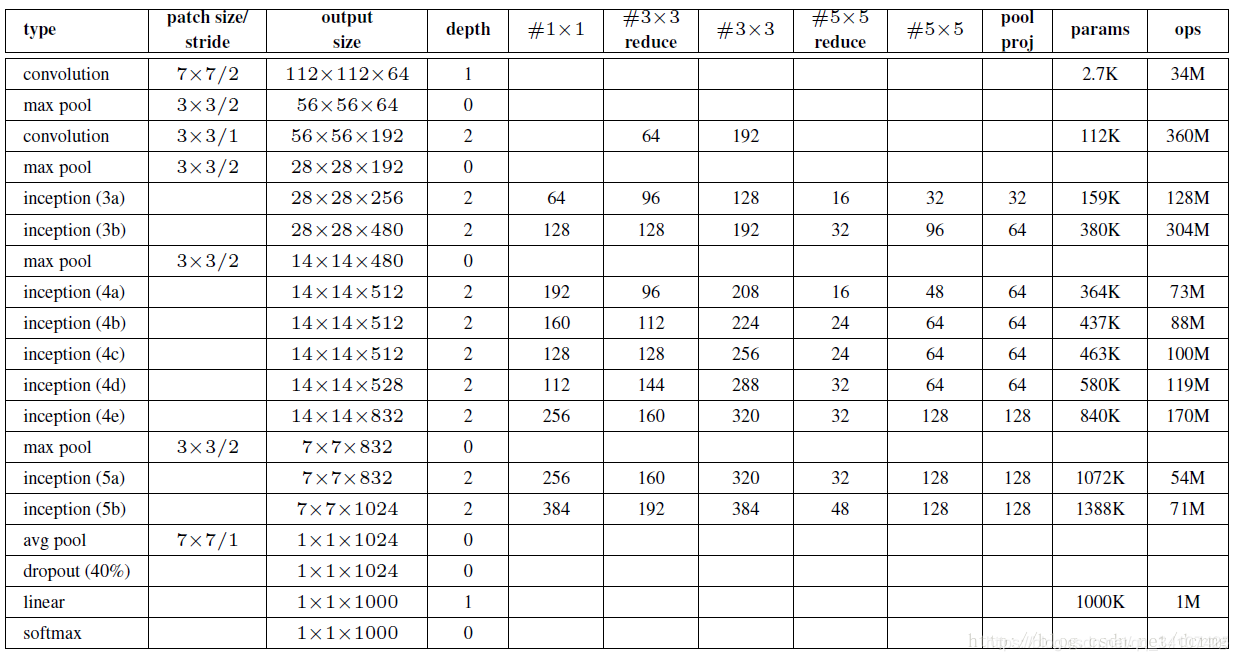
GoogLeNet网络结构明细表解析如下:
0、输入
原始输入图像为224x224x3,且都进行了零均值化的预处理操作(图像每个像素减去均值)。
1、第一层(卷积层)
使用7x7的卷积核(滑动步长2,padding为3),64通道,输出为112x112x64,卷积后进行ReLU操作
经过3x3的max pooling(步长为2),输出为((112 - 3+1)/2)+1=56,即56x56x64,再进行ReLU操作
2、第二层(卷积层)
使用3x3的卷积核(滑动步长为1,padding为1),192通道,输出为56x56x192,卷积后进行ReLU操作
经过3x3的max pooling(步长为2),输出为((56 - 3+1)/2)+1=28,即28x28x192,再进行ReLU操作
3a、第三层(Inception 3a层)
分为四个分支,采用不同尺度的卷积核来进行处理
(1)64个1x1的卷积核,然后RuLU,输出28x28x64
(2)96个1x1的卷积核,作为3x3卷积核之前的降维,变成28x28x96,然后进行ReLU计算,再进行128个3x3的卷积(padding为1),输出28x28x128
(3)16个1x1的卷积核,作为5x5卷积核之前的降维,变成28x28x16,进行ReLU计算后,再进行32个5x5的卷积(padding为2),输出28x28x32
(4)pool层,使用3x3的核(padding为1),输出28x28x192,然后进行32个1x1的卷积,输出28x28x32。
将四个结果进行连接,对这四部分输出结果的第三维并联,即64+128+32+32=256,最终输出28x28x256
3b、第三层(Inception 3b层)
(1)128个1x1的卷积核,然后RuLU,输出28x28x128
(2)128个1x1的卷积核,作为3x3卷积核之前的降维,变成28x28x128,进行ReLU,再进行192个3x3的卷积(padding为1),输出28x28x192
(3)32个1x1的卷积核,作为5x5卷积核之前的降维,变成28x28x32,进行ReLU计算后,再进行96个5x5的卷积(padding为2),输出28x28x96
(4)pool层,使用3x3的核(padding为1),输出28x28x256,然后进行64个1x1的卷积,输出28x28x64。
将四个结果进行连接,对这四部分输出结果的第三维并联,即128+192+96+64=480,最终输出输出为28x28x480
第四层(4a,4b,4c,4d,4e)、第五层(5a,5b)……,与3a、3b类似,在此就不再重复。
到这里!我们看美图应该能看出来一点,GoogleNet的结构就是3+3+3总共九个inception模块组成的,每个Inception有两层,加上开头的3个卷积层和输出前的FC层,总共22层!然后每3层的inception之后都会有一个输出结果,这个网络一共有三个输出结果,这是什么情况呢?
这个是辅助分类器,GoogleNet用到了辅助分类器。因为除了最后一层的输出结果,中间节点的分类效果也可能是很好的,苏哟一GoogleNet将中间的某一层作为输出,并以一个较小的权重加入到最终分类结果中。其实就是一种变相的模型融合,同时给网络增加了反向传播的梯度信号,也起到了一定的正则化的作用。
最后,我再提出两个问题:
如果使用1x1进行特征压缩,是否会影响最终结果?
回答:不会,作者的解释是,如果你想要把特征厚度从128变成256,你可以直接用3x3进行特征提取。如果你先用1x1进行压缩到64,然后再用3x3把64channel的特征扩展成256,其实对后续的精度没有影响,而且减少了运算次数。
为什么inception是多个尺度上进行卷积再聚合?
回答:直观上,多个尺度上同时卷积可以提取到不同尺度的特征。而这也意味着最后分类判断更加准确。除此之外,这是可以利用稀疏矩阵分解成密集矩阵计算的原理来加快收敛速度。(第二个好处没有太看懂)
个人浅显的理解就是:提取多个尺度的特征,再聚合的时候,就可以找到关联性强的特征,这样就能避免浪费在关联性较弱的特征上的计算力吧。。
什么是GoogleNet?什么是Inception?GoogleNet结构详解(2014年)
标签:好的 二层 像素 聚类 尺度 关联 假设 src 正则
原文地址:https://www.cnblogs.com/PythonLearner/p/12925700.html