标签:image src 访问 https 信息 瓶颈 旋转 相等 自己
在昨天的面试中问到了MySQL索引怎么优化(查询很慢怎么办),回答的很不理想,所以今天来总结几篇关于MySQL索引的知识。
首先我们一定要明确什么是索引?我自己的总结就是索引是一种数据结构,可以帮助我们快速访问数据库的指定信息,就像一本书的目录一样,可以加快查询速度
MySQL中最常见的存储引擎有InnoDB和MyISAM,它们的主要区别如下:
总结:
最主要的区别就是MyISAM表不支持事务、不支持行级锁、不支持外键。 InnoDB表支持事务、支持行级锁、支持外键。
在MySQL5.5.5版本之后,InnoDB已经成为了其默认的存储引擎,也是大部分公司的不二选择,毕竟谁家公司会不要求数据库支持事务呢?谁家公司又可以忍受表级锁导致的读写冲突呢?
除了InnoDB以及MyISAM存储引擎外,常见的考察存储引擎还有Memory,使用Memory作为存储引擎的表也可以叫做内存表,将数据存储在了内存中,所以适合做临时表来使用,在索引结构上支持B+树索引和Hash索引。
这里推荐一个外国的学习数据结构的一个网站:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html(非常的nice)
首先列举几个可以做索引的数据结构:
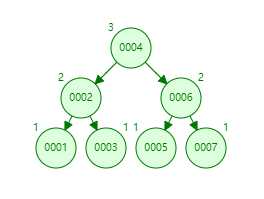
看一下最基本的结构,这里我也是插入了7个数据
说一下特征:
它的快体现在哪里呢?
比如说我们查询3:3是小于根节点4的,从它的左子树找,3是大于2的,所以在2的右子树,这样就查询到3的位置了,查询速度为O(LogN)
缺点:维护平衡二叉树的代价太大每次都需要左旋或者右旋来维持平衡
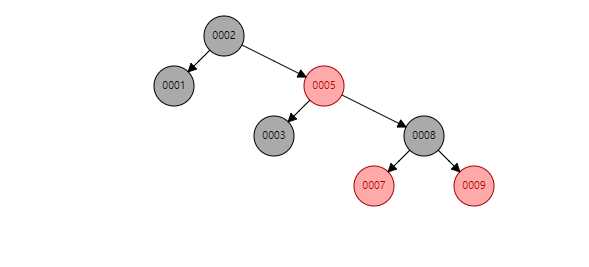
插入10后
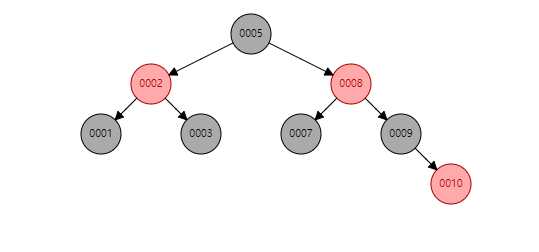
特征:
到这里我们要说到一些东西
计算机硬件性能在过去十年间的发展普遍遵循摩尔定律,通用计算机的CPU主频早已超过3GHz,内存也进入了普及DDR4的时代。然而传统硬盘虽然在存储容量上增长迅速,但是在读写性能上并无明显提
升,同时SSD硬盘价格高昂,不能在短时间内完全替代传统硬盘。传统磁盘的I/O读写速度成为了计算机系统性能提高的瓶颈,制约了计算机整体性能的发展。
其实简单来说就是我们要减少磁盘IO的次数,树的深度越大,磁盘IO的次数就越多,所以无论是从它的平衡代价或者磁盘IO次数来讲红黑树和AVL树都太适合。
由于存储介质的特性,磁盘本身存取就比主存慢很多,再加上机械运动耗费,磁盘的存取速度往往是主存的几百分分之一,因此为了提高效率,要尽量减少磁盘I/O。为了达到这个目的,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。这样做的理论依据是计算机科学中著名的局部性原理:
当一个数据被用到时,其附近的数据也通常会马上被使用。
程序运行期间所需要的数据通常比较集中。
由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率。
红黑树这种结构,h明显要深的多。由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,所以红黑树的I/O渐进复杂度也为O(h),效率明显不太尽人意。
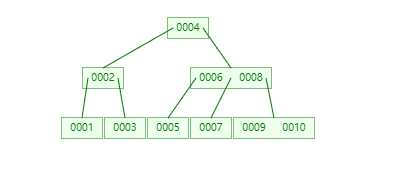
一个M阶的b树具有如下几个特征:
特性
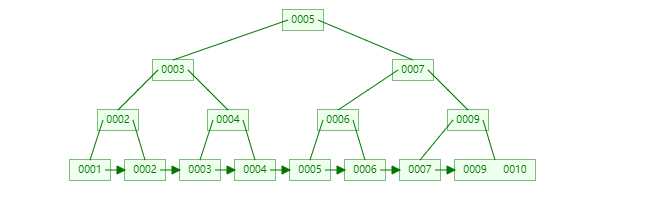
M阶的b+树的特征:
B+树相对于B树的优势
数据库引擎:InnoDB和MyISAM
主要区分:事务,外键,行级锁(以上InnoDB都支持,MyISAM只支持表级锁)
为什么选择B+树:
附加问题:
B+树中一个节点到底多大合适?
B+树中一个节点为一页(16KB)或页的倍数最为合适。
因为如果一个节点的大小小于1页,那么读取这个节点的时候其实也会读出1页,造成资源的浪费。
如果一个节点的大小大于1页,比如1.2页,那么读取这个节点的时候会读出2页,也会造成资源的浪费。
所以为了不造成浪费,所以最后把一个节点的大小控制在1页、2页、3页、4页等倍数页大小最为合适。
标签:image src 访问 https 信息 瓶颈 旋转 相等 自己
原文地址:https://www.cnblogs.com/dmzna/p/12930067.html