标签:ali too 拿来主义 cal 包名 back 无法 ase stat
模块就是一系列功能的集合体,分为三大类:
1.内置的模块 2.第三方的模块 3.自定义的模块
一个Python文件本身就是一个模块。例如:文件名为m.py,其模块名则为m
Ps:模块分为四种类型: 1.使用Python编写的.py文件 2.已被编译为共享库或DLL的C或C++扩展 3.把一系列模块组织到一起的文件夹(注:文件夹下有个__init__.py文件) 4.使用C语言编写并链接到Python解释器的内置模块
1.内置与第三方模块可以拿来就用,无需定义,这种拿来主义可以极大的提升自己的开发效率。
2.自定义的模块可以将程序各部分常用的功能提取出来放到一个模块中为大家共享使用,好处是减少了代码冗余,程序组织结构更加清晰。
如果是自定义模块需要先创建一个.py文件。

#!/usr/bin/env python3 # -*- coding: utf-8 -*- # 这是一个模块 print("模块foo --->") x = 1 def get(): print(x) def change(): global x x = 0
然后再到执行程序中去导入使用
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # 对于内置模块来说 import datetime print(datetime.datetime.now()) # 对于自定义模块来说 import foo # 文件名为foo.py,模块名为foo print(foo.x) # ==== 执行结果 ==== """ 2020-05-21 22:29:28.448299 模块foo ---> 1 """
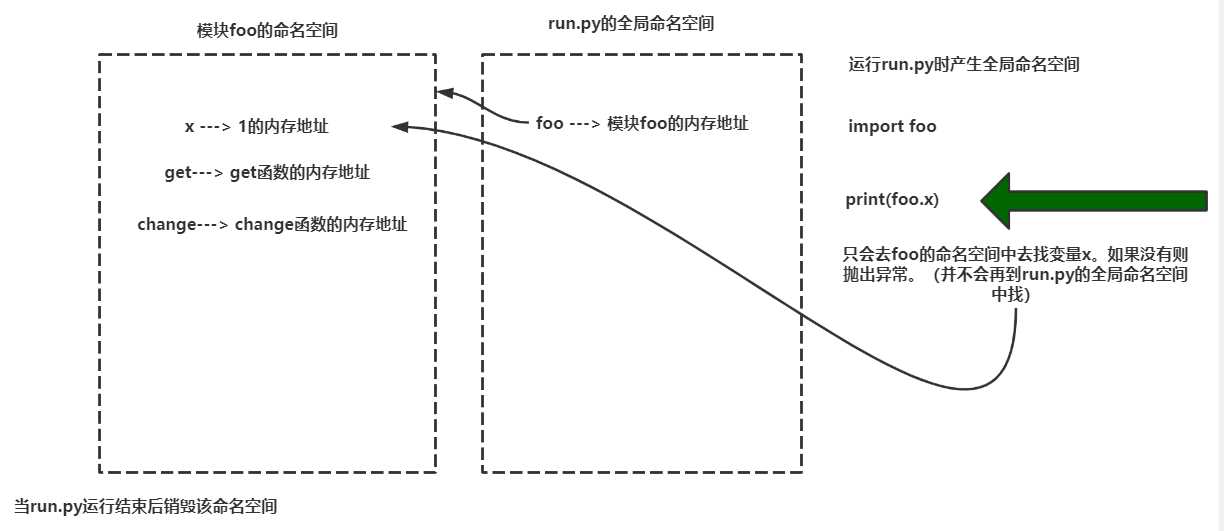
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import foo # 文件名为foo.py,模块名为foo print(foo.x) """ 使用import首次导入模块会发生3件事: 1.执行foo.py 2.产生foo.py的命名空间,将foo.py运行过程中产生的名字都丢到foo的命名空间中 3.在当前run.py也就是程序文件中产生一个名字为foo.该名字指向foo名称空间
如有重复导入,不必再次经历首次导入的三步骤。(命名空间以存在,常驻内存中..) """ # ==== 执行结果 ====
""" 模块foo ---> 1 """
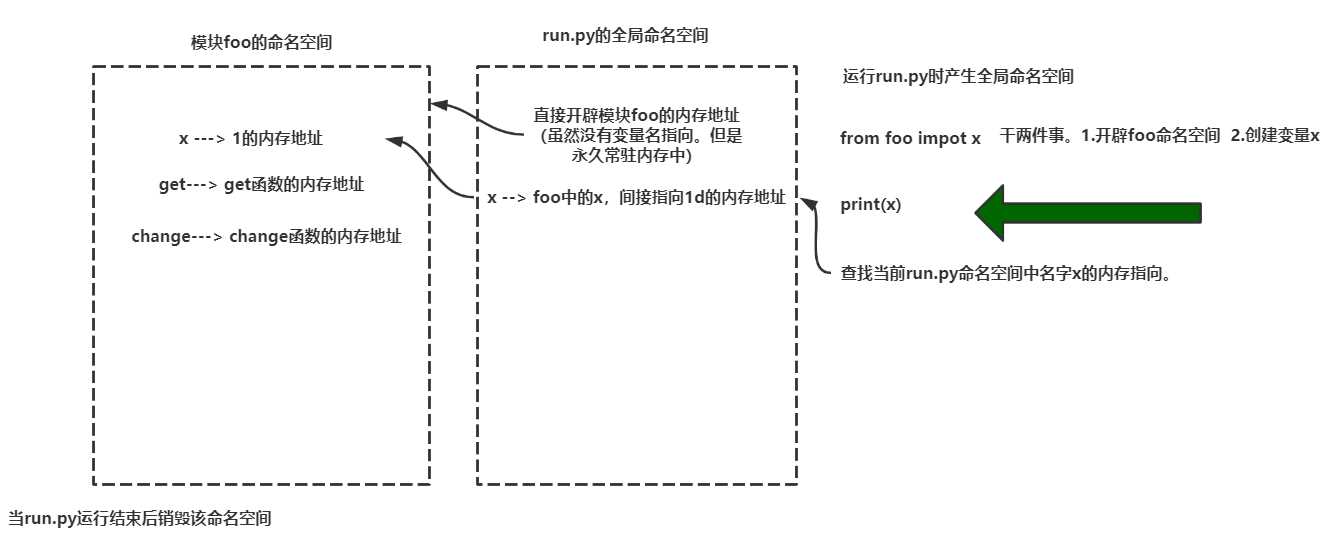
#!/usr/bin/env python3 # -*- coding: utf-8 -*- from foo import x # 文件名为foo.py,模块名为foo print(x) """ 使用from ... import ... 首次导入模块会发生3件事: 1.执行foo.py 2.产生foo.py的命名空间,将foo.py运行过程中产生的名字都丢到foo的命名空间中 3.在当前run.py也就是程序文件中产生一个名字为x.该名字指向foo名称空间中的同名变量所指向的内存空间 如有重复导入,不必再次经历首次导入的三步骤。(命名空间以存在,常驻内存中..) """ # ==== 执行结果 ==== """ 模块foo ---> 1 """
一个Python文件有两种用途,一种被当主程序/脚本执行,另一种被当模块导入,为了区别同一个文件的不同用途,每个py文件都内置了__name__变量,该变量在py文件被当做脚本执行时赋值为“__main__”,在py文件被当做模块导入时赋值为模块名。
作为模块foo.py的开发者,可以在文件末尾基于__name__在不同应用场景下值的不同来控制文件执行不同的逻辑
#foo.py ... if __name__ == ‘__main__‘: foo.py被当做脚本执行时运行的代码 else: foo.py被当做模块导入时运行的代码
通常我们会在if的子代码块中编写针对模块功能的测试代码,这样foo.py在被当做脚本运行时,就会执行测试代码,而被当做模块导入时则不用执行测试代码。
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # 这是一个模块 print("模块foo --->") x = 1 def get(): print(x) def change(): global x x = 0 if __name__ == ‘__main__‘: # Ps:由于导入模块时会先执行一遍模块文件。故可以采用此种方式做功能测试 get() else: print("不运行get..") """ 执行结果如下: 1.当将foo.py当做主程序运行时,会 print("模块foo --->") 后 执行get()方法。 2.当将foo.py当做模块进行导入时,会 print("模块foo --->") 后 print("不运行get..") 。 """
强调1:模块名.名字,是指名道姓的问某一个模块要名字对应的值,不会与当前命名空间发生冲突。(即使模块中没有该名字,也不会来执行文件中找)
强调2:无论是查看还是修改操作的都是模块本身,与调用位置(执行文件)无关。
使用import导入模块的优缺点:
优点:肯定不会与当前名称空间中的名字冲突
缺点:使用模块中功能或变量时需加前缀
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import foo # 文件名为foo.py,模块名为foo def get(): # run.py全局命名空间下定义了get() print("run.py ... get()") foo.get() # 运行依旧是foo中的get() x = 33333 print(foo.x) # 拿foo中的x,就算foo中没有定义x也不会来run.py中找x foo.change() # 修改的是foo中的x内存指向,与run.py中的x无关。即使foo中没有x也不会修改run.py中的x print(foo.x) print(x) """ 强调1:模块名.名字,是指名道姓的问某一个模块要名字对应的值,不会与当前命名空间发生冲突。(即使模块中没有该名字,也不会来执行文件中找) 强调2:无论是查看还是修改操作的都是模块本身,与调用位置(执行文件)无关。 """ # ==== 执行结果 ==== """ 模块foo ---> 1 1 0 33333 """
强调1:使用from .. import .. 的方式可能会导致命名空间冲突的问题。
使用from .. import ..导入模块的优缺点:
优点:在使用模块中功能时,代码更加精简
缺点:容易与当前命名空间发生混淆。
#!/usr/bin/env python3 # -*- coding: utf-8 -*- from foo import x # 文件名为foo.py,模块名为foo print(x) # 此刻的x指向的内存地址是foo.x指向的内存地址 x = 33333 print(x) # 此刻的x已经改变指向 """ 强调1:使用from .. import .. 的方式可能会导致命名空间冲突的问题。 """ # ==== 执行结果 ==== """ 模块foo ---> 1 33333 """
""" 导入模块的规范: 1.Python内置模块 2.第三方模块 3.程序员自定义模块 模块是第一类对象(允许被当做参数传入等等...) 自定义的模块命名应该采用纯小写+下划线的风格 Ps: 尽管Python2中有些模块是以驼峰体进行命名,但是在Python3中他们都全部变为纯小写了。 如:Python2中的PyMySql已经命名为pymysql """ import datetime,time,os # 使用 , 逗号 可以一行导入多个模块.但是不建议这么做。 import collections as coll # 使用 as 可以为模块取一个别名。 from foo import x,get,change # 使用 , 逗号 可以一行导入同个模块下的多个功能.但是不建议这么做。 from foo import * # 导入模块中的所有功能。(大多数情况下不推荐使用,视情况而定)
无论是import还是from .. import .. 在导入模块时都涉及到查找的问题。 优先级: 1.内存(内置模块) 2.硬盘(sys.path) 当一个模块被导入过一次后,就会加载至内存中,重复导入便可直接从内存中拿到该模块。
1.sys.modules是导入模块后最先查找的路径顺序,当模块名不存在于该字典时将去硬盘中进行查找。
2.当首次导入一个模块之后,该模块会在此次执行文件运行的过程中将首次导入的模块路径存放至内存中,del该模块后解除变量名与其绑定关系。(只要程序再运行,二次导入都从内存中导入) 3.当二次导入该模块时依照查找顺序直接从内存就可导入该模块。
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import sys import foo # 执行foo,开始首次导入三步骤 del foo # <=== 此时已经将foo模块加载至内存中,即使删除绑定关系也无妨 print("foo" in sys.modules) import foo # <--- 第二次导入不会执行首次导入三步骤。 print(sys.modules) # 查看已经加载至内存中的模块 # ==== 执行结果 ==== Ps: <--- 可以看到foo即使被del也依旧存在于内存中 """ 模块foo ---> True {‘sys‘: <module ‘sys‘ (built-in)>, ‘builtins‘: <module ‘builtins‘ (built-in)>, ‘_frozen_importlib‘: <module ‘_frozen_importlib‘ (frozen)>, ‘_imp‘: <module ‘_imp‘ (built-in)>, ‘_warnings‘: <module ‘_warnings‘ (built-in)>, ‘_frozen_importlib_external‘: <module ‘_frozen_importlib_external‘ (frozen)>, ‘_io‘: <module ‘io‘ (built-in)>, ‘marshal‘: <module ‘marshal‘ (built-in)>, ‘nt‘: <module ‘nt‘ (built-in)>, ‘_thread‘: <module ‘_thread‘ (built-in)>, ‘_weakref‘: <module ‘_weakref‘ (built-in)>, ‘winreg‘: <module ‘winreg‘ (built-in)>, ‘time‘: <module ‘time‘ (built-in)>, ‘zipimport‘: <module ‘zipimport‘ (frozen)>, ‘_codecs‘: <module ‘_codecs‘ (built-in)>, ‘codecs‘: <module ‘codecs‘ from ‘C:\\Python38\\lib\\codecs.py‘>, ‘encodings.aliases‘: <module ‘encodings.aliases‘ from ‘C:\\Python38\\lib\\encodings\\aliases.py‘>, ‘encodings‘: <module ‘encodings‘ from ‘C:\\Python38\\lib\\encodings\\__init__.py‘>, ‘encodings.utf_8‘: <module ‘encodings.utf_8‘ from ‘C:\\Python38\\lib\\encodings\\utf_8.py‘>, ‘_signal‘: <module ‘_signal‘ (built-in)>, ‘__main__‘: <module ‘__main__‘ from ‘C:/Users/Administrator/PycharmProjects/learn/ModelsLearn/run.py‘>, ‘encodings.latin_1‘: <module ‘encodings.latin_1‘ from ‘C:\\Python38\\lib\\encodings\\latin_1.py‘>, ‘_abc‘: <module ‘_abc‘ (built-in)>, ‘abc‘: <module ‘abc‘ from ‘C:\\Python38\\lib\\abc.py‘>, ‘io‘: <module ‘io‘ from ‘C:\\Python38\\lib\\io.py‘>, ‘_stat‘: <module ‘_stat‘ (built-in)>, ‘stat‘: <module ‘stat‘ from ‘C:\\Python38\\lib\\stat.py‘>, ‘_collections_abc‘: <module ‘_collections_abc‘ from ‘C:\\Python38\\lib\\_collections_abc.py‘>, ‘genericpath‘: <module ‘genericpath‘ from ‘C:\\Python38\\lib\\genericpath.py‘>, ‘ntpath‘: <module ‘ntpath‘ from ‘C:\\Python38\\lib\\ntpath.py‘>, ‘os.path‘: <module ‘ntpath‘ from ‘C:\\Python38\\lib\\ntpath.py‘>, ‘os‘: <module ‘os‘ from ‘C:\\Python38\\lib\\os.py‘>, ‘_sitebuiltins‘: <module ‘_sitebuiltins‘ from ‘C:\\Python38\\lib\\_sitebuiltins.py‘>, ‘sitecustomize‘: <module ‘sitecustomize‘ from ‘D:\\Application\\PyCharm 2020.1\\plugins\\python\\helpers\\pycharm_matplotlib_backend\\sitecustomize.py‘>, ‘site‘: <module ‘site‘ from ‘C:\\Python38\\lib\\site.py‘>, ‘foo‘: <module ‘foo‘ from ‘C:\\Users\\Administrator\\PycharmProjects\\learn\\ModelsLearn\\foo.py‘>} """
1.当内存中没有模块路径时,将按照sys.path的路径顺序依次在硬盘中查找。
2.Pycharm中的sys.path比Python原生解释器中的sys.path多了三个选项。分别是(第二项,第三项,倒数第一项)
3.可使用sys.path.append("模块绝对路径")添加搜索路径。
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import sys import foo # 执行foo,开始首次导入三步骤 print(sys.path) # 当内存中没有模块路径时,将按照sys.path的路径顺序依次在硬盘中查找。 # ==== 执行结果 ==== """ Ps:Pycharm执行该脚本时产生的结果 模块foo ---> [ ‘C:\\Users\\Administrator\\PycharmProjects\\learn\\ModelsLearn‘, ‘C:\\Users\\Administrator\\PycharmProjects\\learn‘, # 不存在 ‘D:\\Application\\PyCharm 2020.1\\plugins\\python\\helpers\\pycharm_display‘, # 不存在 ‘C:\\Python38\\python38.zip‘, ‘C:\\Python38\\DLLs‘, ‘C:\\Python38\\lib‘, ‘C:\\Python38‘, ‘C:\\Python38\\lib\\site-packages‘, ‘D:\\Application\\PyCharm 2020.1\\plugins\\python\\helpers\\pycharm_matplotlib_backend‘ # 不存在 ] """ """ Ps:Python解释器执行该脚本时产生的结果 模块foo ---> [ ‘C:\\Users\\Administrator\\PycharmProjects\\learn\\ModelsLearn‘, ‘C:\\Python38\\python38.zip‘, ‘C:\\Python38\\DLLs‘, ‘C:\\Python38\\lib‘, ‘C:\\Python38‘, ‘C:\\Python38\\lib\\site-packages‘] """
1.包就是一个包含有__init__.py文件的文件夹。(在Python2中包必须有__init__.py文件,Python3中不强制有此要求。) 2.包的本质是模块的一种形式。 导入包的三步骤:
1.产生一个命名空间 2.执行__init__.py文件将产生的名字丢到该包的命名空间中 3.在当前run.py中拿到一个变量,该变量指向包的命名空间。
# 包可以当做一系列模块的集合体(包本身也是一个模块) # 自定义包:
""" my_plugin/ #顶级包 ├── __init__.py ├── tools #子包 │ ├── __init__.py │ ├── f1.py │ └── f2.py └── m1.py #子模块 """ # === my_plugin/__init__.py === from . import m1 from . import tools # === my_plugin/ m1.py === def plugin_m1(): print("plugin_m1...") # === my_plugin/tools/__init__.py === from . import f1 from . import f2 # === my_plugin/tools/f1.py === def tools_f1(): print("tools_f1...") # === my_plugin/tools/f2.py === def tools_f2(): print("tools_f2...")
# === 结构 ===
1.关于包相关的导入语句也分为import和from ... import ...两种,
但是无论哪种,无论在什么位置,在导入时都必须遵循一个原则:凡是在导入时带点的,点的左边都必须是一个包,否则非法。使用者无法使用 from . import xxx 的操作。
可以带有一连串的点,如import 顶级包.子包.子模块,但都必须遵循这个原则。但对于导入后,在使用时就没有这种限制了,点的左边可以是包,模块,函数,类(它们都可以用点的方式调用自己的属性)。 2、包A和包B下有同名模块也不会冲突,如A.a与B.a来自俩个命名空间 3、import导入文件时,产生名称空间中的名字来源于文件,import 包,产生的名称空间的名字同样来源于文件,即包下的__init__.py,导入包本质就是在导入该文件
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # 根据包名使用各个功能 from ModelsLearn import my_plugin my_plugin.m1.plugin_m1() my_plugin.tools.f1.tools_f1() my_plugin.tools.f2.tools_f2() # 引入某一个单独的文件 from ModelsLearn.my_plugin import m1 m1.plugin_m1() # 引入单独的某一个功能 from ModelsLearn.my_plugin.m1 import plugin_m1 plugin_m1() # ==== 执行结果 ==== """ plugin_m1... tools_f1... tools_f2... plugin_m1... plugin_m1... """
. 代表当前文件夹 .. 代表上层文件夹 包内的绝对导入是指: from 无论何时都跟上后面跟顶级包名(不推荐这么做,万一后期包名需要更改,很麻烦。)
# my_plugin/__init__.py
# from . import m1 # 对于开发者来说,只要该文件不是执行文件就可以使用 from . import xxx # from . import tools # === Ps === : 为了使用者的使用方便。我们可以更加详细的导入(此处导入为绝对导入) from my_plugin.m1 import plugin_m1 from my_plugin.tools.f1 import tools_f1 from my_plugin.tools.f2 import tools_f2
# run.py 执行文件 # 使用者可以更简单的使用了 from ModelsLearn import my_plugin my_plugin.plugin_m1() my_plugin.tools_f1() my_plugin.tools_f2()
使用 from . import xxx 其中 . 代表当层文件夹。(注意:包的使用者不能使用from . import xxx的操作,因为对于使用者来说 . 的左边必须是一个包名)
# my_plugin/__init__.py # from . import m1 # 对于开发者来说,只要该文件不是执行文件就可以使用 from . import xxx # from . import tools # === Ps === : 使用 from . import xxx 的文件不可被当做执行文件执行。只能被当做模块 from .m1 import plugin_m1 from .tools.f1 import tools_f1 from .tools.f2 import tools_f2
循环导入是指: 模块a中导入模块b,模块b中又导入模块a...
循环导入可能导致的问题: 命名空间中名字可能加载不全...
解决办法:
1.导入语句放到最后,保证在导入时,所有名字都已经加载过2.导入语句放到函数中,只有在调用函数时才会执行其内部代码
最好的解决方案:设计模块时尽量避免循环导入
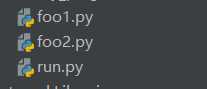
# === run.py === import foo1 # 首次导入,执行foo1.py print(foo1.x) # === foo1.py === from foo2 import y # 首次导入,执行foo2.py x = 10 # 根本来不及将x放入foo1的模块命名空间中,就又去执行foo2去了 # === foo2.py === from foo1 import x # foo1 二次导入,不会执行。尝试拿到x,抛出异常。 y = 20 # 由于第一行是导入x。 # 但是foo1中并没有把x放入foo1模块命名空间中去, # 直接抛出异常导致foo2的y也放不进foo2的模块命名空间中去
# 执行run.py :\Python38\python3.exe C:/Users/Administrator/PycharmProjects/learn/ModelsLearn/run.py Traceback (most recent call last): File "C:/Users/Administrator/PycharmProjects/learn/ModelsLearn/run.py", line 4, in <module> import foo1 File "C:\Users\Administrator\PycharmProjects\learn\ModelsLearn\foo1.py", line 1, in <module> from foo2 import y File "C:\Users\Administrator\PycharmProjects\learn\ModelsLearn\foo2.py", line 1, in <module> from foo1 import x ImportError: cannot import name ‘x‘ from partially initialized module ‘foo1‘ (most likely due to a circular import) (C:\Users\Administrator\PycharmProjects\learn\ModelsLearn\foo1.py) # 可以看到。是 x 抛出的异常,原因上面说的很清楚了,x并没有放入foo1的模块命名空间中去,但是foo2的x尝试将内存指向foo1中的x的内存指向
# 解决方案1 # === run.py === import foo1 print(foo1.x) # === foo1.py === x = 10 from foo2 import y # 先将 x 放入 foo1 的模块命名空间中,就没问题了。 # === foo2.py === y = 20 from foo1 import x # 解决方案2 # === run.py === import foo1 print(foo1.x) # === foo1.py === def init(): from foo2 import y x = 10 init() # 函数定义阶段不会执行,最后调用时x也是已经放在了 foo1 的模块命名空间中。也不会抛出异常 # === foo2.py === def init(): from foo1 import x y = 20 init()
#!/usr/bin/env python #通常只在类unix环境有效,作用是可以使用脚本名来执行,而无需直接调用解释器。 "The module is used to..." #模块的文档描述 import sys #导入模块 x=1 #定义全局变量,如果非必须,则最好使用局部变量,这样可以提高代码的易维护性,并且可以节省内存提高性能 class Foo: #定义类,并写好类的注释 ‘Class Foo is used to...‘ pass def test(): #定义函数,并写好函数的注释 ‘Function test is used to…‘ pass if __name__ == ‘__main__‘: #主程序 test() #在被当做脚本执行时,执行此处的代码
# foo.py __all__ = ["x","y"] # #该列表中所有的元素必须是字符串类型,每个元素对应foo.py中的一个名字 x = 10 y = 20 z = 30 """ 也就是说,当使用 from ModelsLearn.foo import * 的时候,* 只能拿到 __all__ 中存在的名字。 """
# run.py from ModelsLearn.foo import * print(x) # 正常访问 print(y) # 正常访问 print(z) # 抛出异常 # ==== 执行结果 ==== """ 10 20 Traceback (most recent call last): File "C:/Users/Administrator/PycharmProjects/learn/ModelsLearn/run.py", line 9, in <module> print(z) # 抛出异常 NameError: name ‘z‘ is not defined """
标签:ali too 拿来主义 cal 包名 back 无法 ase stat
原文地址:https://www.cnblogs.com/Yunya-Cnblogs/p/12934738.html