@misc{dai2018tan,
title={TAN: Temporal Aggregation Network for Dense Multi-label Action Recognition},
author={Xiyang Dai and Bharat Singh and Joe Yue-Hei Ng and Larry S. Davis},
year={2018},
eprint={1812.06203},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Abstract
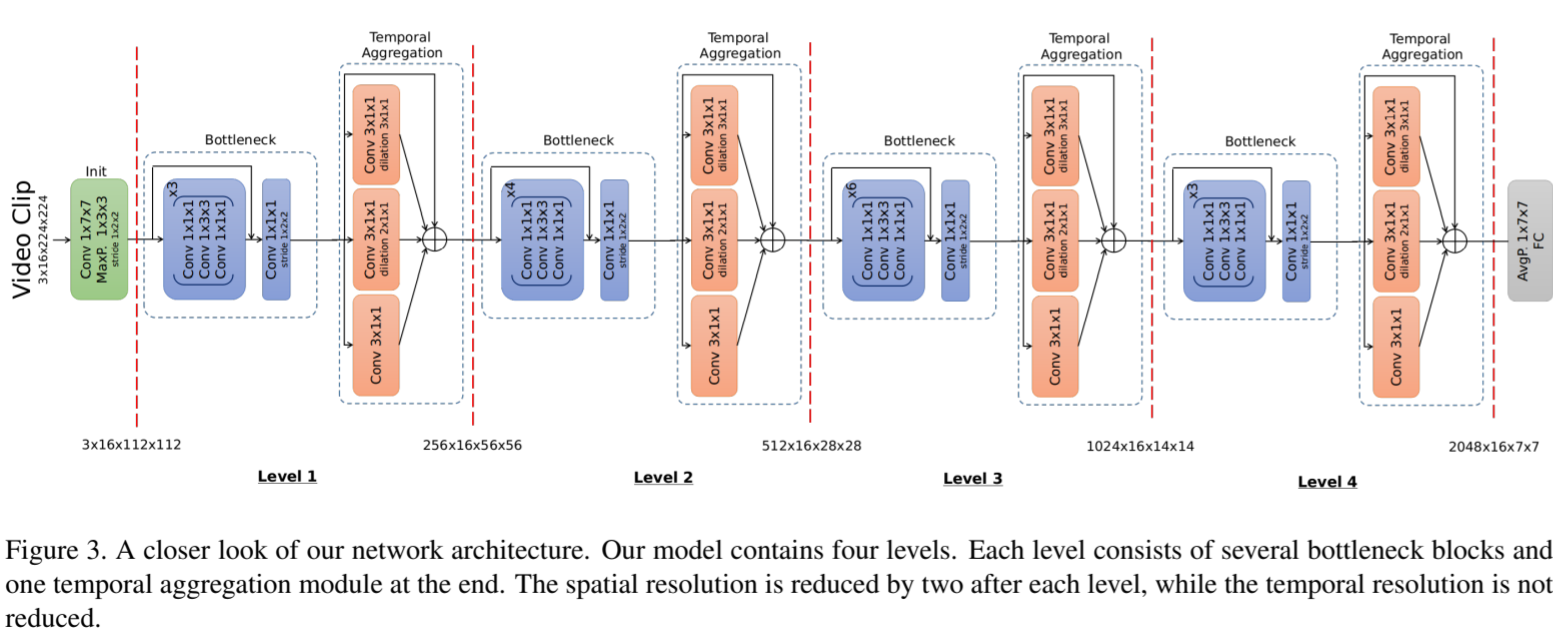
Temporal Aggregation Network TAN decompose 3D convolutions into spatial and temporal aggregation blocks.
Reduce complexity : Only apply temporal aggregation blocks once after each spatial down-sampling layer in the network.
Dilated convolutions at different resolutions of the network helps in aggregating multi-scale spatial-temporal information.
TAN model is well suited for dense multi-label action recognition.
Difficulties:
In a video, multiple frames aggregated together represent a semantic label which caused more computation compared to image recognition.
Actions can span multiple temporal and spatial scales in videos.
Related Work
Action recognition
Two-stream network comprising two parallel CNNs, one trained on RGB images and another trained on stacked optical flow fields.
C3D operate on a sequence of image and perform 3D convolution (\(3 \times 3 \times 3\)).
Multi-label prediction
Temporal action localization
Making dense predictions
Predict temporal boundaries
Model
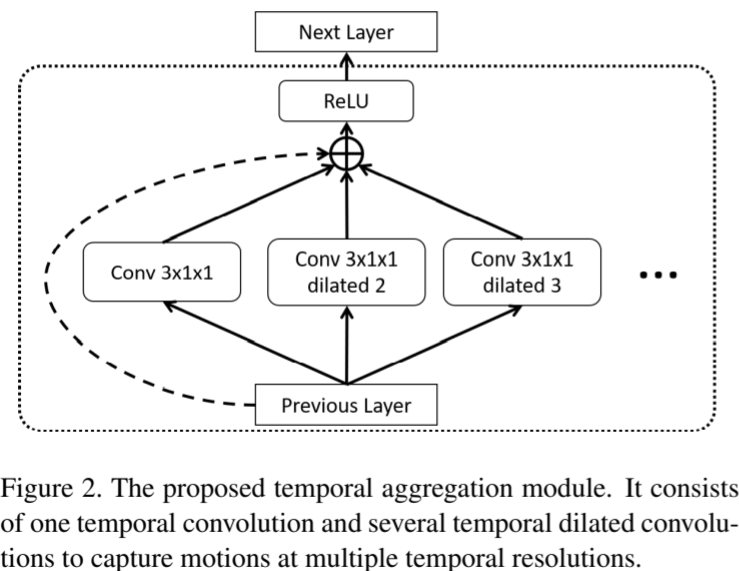
Proposed Temporal Aggregation Module
A temporal aggregation module combines multiple convolutions with different dilation factors (in the temporal domain) and stacks them across the entire network.
Temporal convolution is a simple 1D dilated convolution
Add a residual identity connection from previous layers