标签:first 国家 gen 数据采集 资讯 als pre 获取网页 ansi
1.使用GET方式抓取数据,GET方法用于获取或者查询资源信息
#导入requests包 import requests #网址 url = ‘http://www.cntour.cn/‘ #GET方式,获取网页数据 strhtml = requests.get(url) #strhtml是一个url对象,代表整个网页,但是只需要网页中源码 print(strhtml.text)
结果(部分):
<!DOCTYPE html PUBLIC "-//W3C//XHD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/XHD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html;charset=utf-8"/>
<meta http-equiv="X-UA-Compatible" content="IE=Edge,chrome=1" />
<title>中国旅游网 ——中国文旅门户网站</title>
<meta name="keywords" content="中国旅游网,旅游网站,中国旅游,中国文旅网,中旅网,文化旅游网,旅游新闻,中国旅游新闻,旅游攻略,国家旅游,旅游媒体,中国景点网,旅游网站,旅游网,旅游媒体,旅游新闻网,旅游资讯,旅游网,"/>
<meta name="description" content="中国旅游网(www.cntour.cn)是中国最大的旅游门户网站,也是国内最专业的旅游媒体平台和旅游综合社区。服务电话:400-181-5261,中国旅游网,中国旅游,旅游攻略,中国文旅网,旅游媒体,旅游新闻,文化旅游网,旅游资讯,旅游网站,中国旅游网,旅游攻略,中国旅游网,旅游资讯,中国景点网,中国旅游,中旅网,旅游网,中国旅游网,景点介绍,城市旅游,中国旅游网,旅游门户,中国旅游网站,旅游网站,旅游网,旅游攻略,中国旅游网,旅游新闻,旅游资讯,最大的旅游网"/>
<link rel="stylesheet" type="text/css" href="/style/blue/css/common.css"/>
2.使用POST方式抓取数据
#导入requests包
import requests
#导入JSON包
import json
#用于翻译的函数
def get_translate_date(word=None):
url = ‘http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule‘
#请求参数
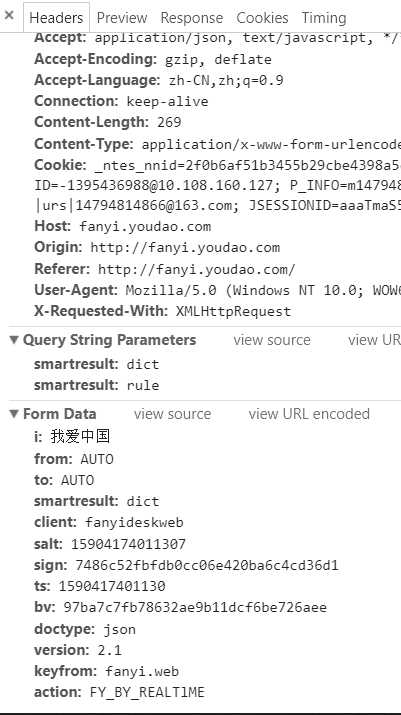
Form_data = {‘i‘: word, ‘from‘: ‘AUTO‘, ‘to‘: ‘AUTO‘, ‘smartresult‘: ‘dict‘, ‘client‘: ‘fanyideskweb‘, ‘salt‘: ‘15904174011307‘,
‘sign‘: ‘7486c52fbfdb0cc06e420ba6c4cd36d1‘, ‘ts‘: ‘1590417401130‘, ‘bv‘: ‘97ba7c7fb78632ae9b11dcf6be726aee‘, ‘doctype‘: ‘json‘,
‘version‘: ‘2.1‘, ‘keyfrom‘: ‘fanyi.web‘, ‘action‘: ‘FY_BY_REALTlME‘, ‘typoResult‘: ‘false‘}
#请求表单数据
response = requests.post(url, data=Form_data)
#将JSON格式字符串转字典
content = json.loads(response.text)
#打印翻译后的数据
print(content[‘translateResult‘][0][0][‘tgt‘])
if __name__ == ‘__main__‘:
get_translate_date(‘我爱蔡依林‘)

结果:
I love jolin tsai
3.使用Beautif Soup解析网页
Beautiful Soup是Python的一个库,其最主要的功能是从网页抓取数据。Beautiful Soup目前已经被移植到bs4库中。
#导入requests import requests #导入Beautiful Soup from bs4 import BeautifulSoup #网址 url = ‘http://www.cntour.cn/‘ #GET方式,获取网页数据 strhtml = requests.get(url) #使用lxml解析器进行解析,将解析后的文档存储到新建的soup中 soup=BeautifulSoup(strhtml.text, ‘lxml‘) #使用soup.select引用路径 data=soup.select(‘#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a‘) print(data)
结果:
[<a href="http://www.cntour.cn/news/13826/" target="_blank" title="疫情倒逼旅游业加快创新发展步伐">疫情倒逼旅游业加快创新发展步伐</a>, <a href="http://www.cntour.cn/news/13824/" target="_blank" title="世界旅游组织:今年国际游客或减80%">世界旅游组织:今年国际游客或减80%</a>, <a href="http://www.cntour.cn/news/13823/" target="_blank" title="线上旅游热情高涨 释放新兴消费潜力">线上旅游热情高涨 释放新兴消费潜力</a>, <a href="http://www.cntour.cn/news/13819/" target="_blank" title="恢复和扩大旅游消费要有“三心”">恢复和扩大旅游消费要有“三心”</a>, <a href="http://www.cntour.cn/news/13802/" target="_blank" title="文创行业线上发力">[文创行业线上发力]</a>, <a href="http://www.cntour.cn/news/13792/" target="_blank" title="“无接触商业”加速到来">[“无接触商业”加速到来]</a>, <a href="http://www.cntour.cn/news/13790/" target="_blank" title="主动迎接旅游转型">[主动迎接旅游转型]</a>, <a href="http://www.cntour.cn/news/13779/" target="_blank" title="文旅魅力 “云”端绽放">[文旅魅力 “云”端绽放]</a>, <a href="http://www.cntour.cn/news/13768/" target="_blank" title="景点开放要安全有序">[景点开放要安全有序]</a>, <a href="http://www.cntour.cn/news/13747/" target="_blank" title="图解:10年旅游让生活更美好">[图解:10年旅游让生活更]</a>, <a href="http://www.cntour.cn/news/12718/" target="_blank" title="发展旅游产业要有大格局">[发展旅游产业要有大格局]</a>, <a href="http://www.cntour.cn/news/12716/" target="_blank" title="科技改变旅游">[科技改变旅游]</a>]
4.清洗和组织数据
#导入requests
import requests
#导入Beautiful Soup
from bs4 import BeautifulSoup
#导入re
import re
#网址
url = ‘http://www.cntour.cn/‘
#GET方式,获取网页数据
strhtml = requests.get(url)
#使用lxml解析器进行解析,将解析后的文档存储到新建的soup中
soup=BeautifulSoup(strhtml.text, ‘lxml‘)
#使用soup.select引用路径
data=soup.select(‘#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a‘)
for item in data:
result={
#提取标签正文用get_text()
‘title‘:item.get_text(),
#在括号中指定要提取的属性数据
‘link‘:item.get(‘href‘),
#使用正则符号
#\d匹配数字
#+匹配前一个字符1次或多次
‘ID‘:re.findall(‘\d+‘,item.get(‘href‘))
}
print(result)
结果:
无正则化
{‘title‘: ‘疫情倒逼旅游业加快创新发展步伐‘, ‘link‘: ‘http://www.cntour.cn/news/13826/‘}
{‘title‘: ‘世界旅游组织:今年国际游客或减80%‘, ‘link‘: ‘http://www.cntour.cn/news/13824/‘}
{‘title‘: ‘线上旅游热情高涨 释放新兴消费潜力‘, ‘link‘: ‘http://www.cntour.cn/news/13823/‘}
{‘title‘: ‘恢复和扩大旅游消费要有“三心”‘, ‘link‘: ‘http://www.cntour.cn/news/13819/‘}
{‘title‘: ‘[文创行业线上发力]‘, ‘link‘: ‘http://www.cntour.cn/news/13802/‘}
{‘title‘: ‘[“无接触商业”加速到来]‘, ‘link‘: ‘http://www.cntour.cn/news/13792/‘}
{‘title‘: ‘[主动迎接旅游转型]‘, ‘link‘: ‘http://www.cntour.cn/news/13790/‘}
{‘title‘: ‘[文旅魅力 “云”端绽放]‘, ‘link‘: ‘http://www.cntour.cn/news/13779/‘}
{‘title‘: ‘[景点开放要安全有序]‘, ‘link‘: ‘http://www.cntour.cn/news/13768/‘}
{‘title‘: ‘[图解:10年旅游让生活更]‘, ‘link‘: ‘http://www.cntour.cn/news/13747/‘}
{‘title‘: ‘[发展旅游产业要有大格局]‘, ‘link‘: ‘http://www.cntour.cn/news/12718/‘}
{‘title‘: ‘[科技改变旅游]‘, ‘link‘: ‘http://www.cntour.cn/news/12716/‘}
正则化
{‘title‘: ‘疫情倒逼旅游业加快创新发展步伐‘, ‘link‘: ‘http://www.cntour.cn/news/13826/‘, ‘ID‘: [‘13826‘]}
{‘title‘: ‘世界旅游组织:今年国际游客或减80%‘, ‘link‘: ‘http://www.cntour.cn/news/13824/‘, ‘ID‘: [‘13824‘]}
{‘title‘: ‘线上旅游热情高涨 释放新兴消费潜力‘, ‘link‘: ‘http://www.cntour.cn/news/13823/‘, ‘ID‘: [‘13823‘]}
{‘title‘: ‘恢复和扩大旅游消费要有“三心”‘, ‘link‘: ‘http://www.cntour.cn/news/13819/‘, ‘ID‘: [‘13819‘]}
{‘title‘: ‘[文创行业线上发力]‘, ‘link‘: ‘http://www.cntour.cn/news/13802/‘, ‘ID‘: [‘13802‘]}
{‘title‘: ‘[“无接触商业”加速到来]‘, ‘link‘: ‘http://www.cntour.cn/news/13792/‘, ‘ID‘: [‘13792‘]}
{‘title‘: ‘[主动迎接旅游转型]‘, ‘link‘: ‘http://www.cntour.cn/news/13790/‘, ‘ID‘: [‘13790‘]}
{‘title‘: ‘[文旅魅力 “云”端绽放]‘, ‘link‘: ‘http://www.cntour.cn/news/13779/‘, ‘ID‘: [‘13779‘]}
{‘title‘: ‘[景点开放要安全有序]‘, ‘link‘: ‘http://www.cntour.cn/news/13768/‘, ‘ID‘: [‘13768‘]}
{‘title‘: ‘[图解:10年旅游让生活更]‘, ‘link‘: ‘http://www.cntour.cn/news/13747/‘, ‘ID‘: [‘13747‘]}
{‘title‘: ‘[发展旅游产业要有大格局]‘, ‘link‘: ‘http://www.cntour.cn/news/12718/‘, ‘ID‘: [‘12718‘]}
{‘title‘: ‘[科技改变旅游]‘, ‘link‘: ‘http://www.cntour.cn/news/12716/‘, ‘ID‘: [‘12716‘]}
5.爬虫攻防战
服务器第一种识别爬虫的方式就是通过检查连接的useragent来识别到底是浏览器访问,还是代码访问。如果是代码访问的话,访问量增大时,服务器会直接封掉来访IP。
破解方法1:
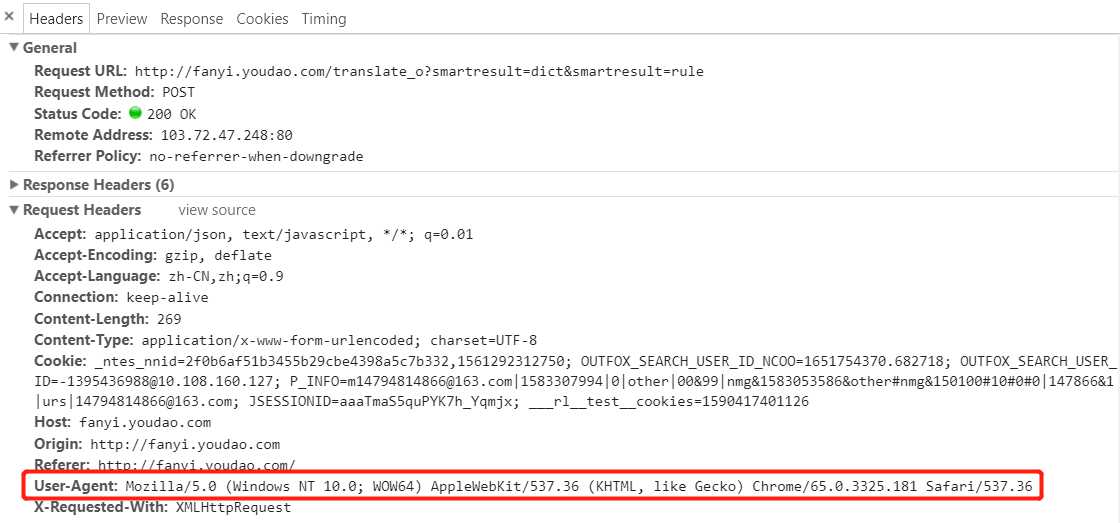
在Request headers中构造浏览器请求头。代码如下:
headers={‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36‘}
response=requests.get(url, headers=headers)
破解方法2:
增设延时,避免访问太频繁。
import time time.sleep(3)
破解方法3:
服务器的目的就是查出哪些为代码访问,然后封锁IP。为避免被封IP,在数据采集是经常会使用代理。requests也有相应的proxies属性。
首先,构建自己的代理IP池,将其以字典的形式赋值给proxies,然后传输给requests。
proxies={
"http":"http://10.10.1.10:3128",
"https":"http://10.10.1.10:1080",
}
response=requests.get(url,proxies=proxies)
标签:first 国家 gen 数据采集 资讯 als pre 获取网页 ansi
原文地址:https://www.cnblogs.com/zhuozige/p/12961906.html