标签:write index stat 文件的操作 行修改 rect sql group process
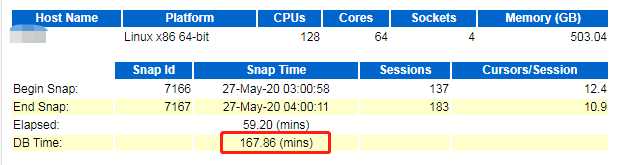
通过db time/Elapsed显示数据库的压力并不是很大。
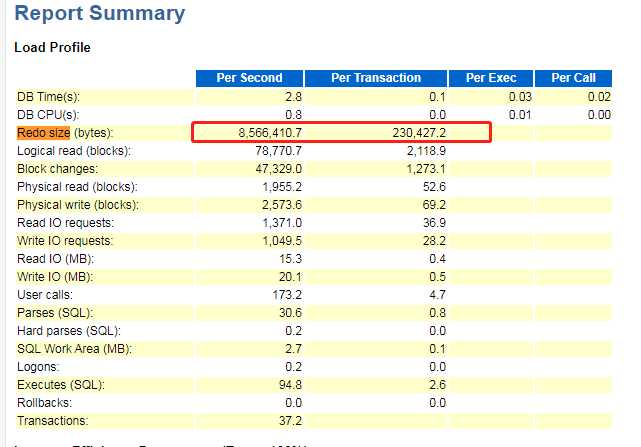
每秒钟产生的redo log 8M,数据库的IO写压力很大。
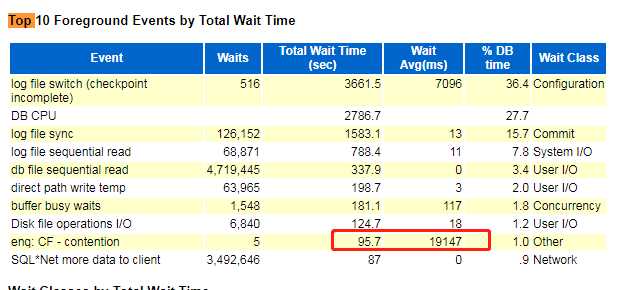
redo 切换频率
只要是需要读控制文件的操作期间,都调用并持有 CF enqueue, CF 块用于控制文件相关事务的序列化 操作和在控制文件共享部分的读写操作。
一般来说,控制文件的CF enqueue 锁的申请和持有时间是非常短暂的。
数据库的下列操作会调用该锁:
任何需要读取控制文件的动作期间都会产生CF队列,CF锁用于controlfile序列操作和共享部分controlfile读和写。通常CF锁是分配给一个非常简短的时间和时使用:
查找持有锁的会话:
select l.sid, p.program, p.pid, p.spid, s.username, s.terminal, s.module, s.action, s.event, s.wait_time, s.seconds_in_wait, s.state from v$lock l, v$session s, v$process p where l.sid = s.sid and s.paddr = p.addr and l.type=‘CF‘ and l.lmode >= 5;
查找申请锁的会话:
select l.sid, p.program, p.pid, p.spid, s.username, s.terminal, s.module, s.action, s.event, s.wait_time, s.seconds_in_wait, s.state from v$lock l, v$session s, v$process p where l.sid = s.sid and s.paddr = p.addr and l.type=‘CF‘ and l.request >= 5;
METALINK理解如下:
解决方法:redolog的大小和切换频率,建议每次日志切换的时间间隔着30分钟左右。
解决方法:该等待是正常的数据库等待;
后台进程
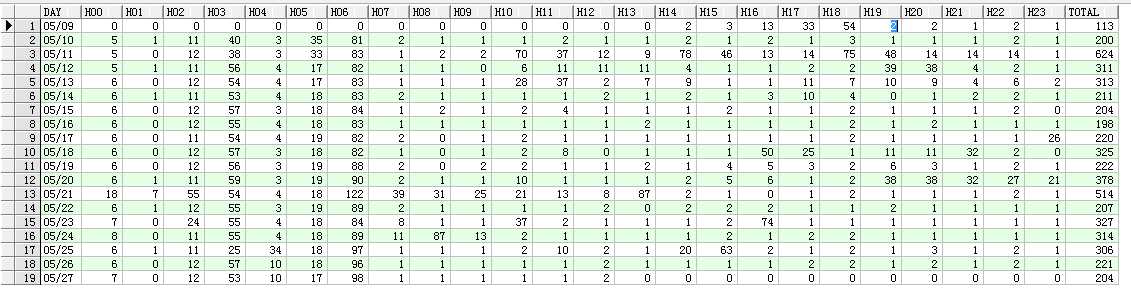
如果通过上面的SQL,发现持有锁的进程是后台进程,比如CKPT,LGWR,ARCn,等,并且已经持有相当 长一段时间,正常来说持有锁的时间是忽略不计的。 针对这种情况,检查redo 日志的切换频率,是不是过快,Oracle 推荐在30分钟左右切换一次。 查看方法如下:
SELECT TO_CHAR(FIRST_TIME,‘YYYY-MM-DD‘) DAY, TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘00‘,1,0)),‘99‘) "00", TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘01‘,1,0)),‘99‘) "01", TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘02‘,1,0)),‘99‘) "02", TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘03‘,1,0)),‘99‘) "03", TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘04‘,1,0)),‘99‘) "04", TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘05‘,1,0)),‘99‘) "05", TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘06‘,1,0)),‘99‘) "06", TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘07‘,1,0)),‘99‘) "07", TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘08‘,1,0)),‘99‘) "08", TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘09‘,1,0)),‘99‘) "09", TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘10‘,1,0)),‘99‘) "10", TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘11‘,1,0)),‘99‘) "11", TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘12‘,1,0)),‘99‘) "12", TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘13‘,1,0)),‘99‘) "13", TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘14‘,1,0)),‘99‘) "14", TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘15‘,1,0)),‘99‘) "15", TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘16‘,1,0)),‘99‘) "16", TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘17‘,1,0)),‘99‘) "17", TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘18‘,1,0)),‘99‘) "18", TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘19‘,1,0)),‘99‘) "19", TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘20‘,1,0)),‘99‘) "20", TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘21‘,1,0)),‘99‘) "21", TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘22‘,1,0)),‘99‘) "22", TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,‘HH24‘),‘23‘,1,0)),‘99‘) "23" FROM V$LOG_HISTORY GROUP BY TO_CHAR(FIRST_TIME,‘YYYY-MM-DD‘) ORDER BY 1 DESC;
2. 用户进程
假如是用户进程,并且持有锁的会话在不停的变动, 持有锁的会话的等待事件是“control file parallel write”.
那么,很有可能产生问题的根源是在nologging 对象上的DML操作。
Nologging 或者 unrecoverable 操作时,Oracle 会将执行这个unrecoverable操作时的SCN 记录进控制文件。
下列操作都会引起Nologging模式:
那么当进行以上操作时,持有锁的会话等待事件一般是"control file parallel wirte", 其 他会话此时再申请 CF enqueue, 就会出现"Ene: CF - contention".
这是一种正常的现象.
如果以上都没有问题,可以再检查归档.保证归档路径可以正常访问。
如果被堵塞,看实际情况是否可以kill 持有CF enqueue的会话。
前台进程持有CF enqueue:
如果严重影响数据库运行,考虑Kill掉持有锁的会话
Oracle 等待事件 Enq: CF - contention
标签:write index stat 文件的操作 行修改 rect sql group process
原文地址:https://www.cnblogs.com/ss-33/p/12972744.html