标签:通过 性能 博客 www 自动 views 优先 framework 注意

一旦我们使用了视图集,并实现了 HTTP 请求对应的 action 方法(对应规则的说明见 使用视图集简化代码),将其在路由器中注册后,django-restframework 自动会自动为我们生成对应的 API 接口。
目前为止,我们只实现了 GET 请求对应的 action——list 方法,因此路由器只为我们生成了一个 API,这个 API 返回文章资源列表。GET 请求还可以用于获取单个资源,对应的 action 为 retrieve,因此,只要我们在视图集中实现 retrieve 方法的逻辑,就可以直接生成获取单篇文章资源的 API 接口。
贴心的是,django-rest-framework 已经帮我们把 retrieve 的逻辑在 mixins.RetrieveModelMixin 里写好了,直接混入视图集即可:
class PostViewSet(
mixins.ListModelMixin, mixins.RetrieveModelMixin, viewsets.GenericViewSet
):
serializer_class = PostListSerializer
queryset = Post.objects.all()
permission_classes = [AllowAny]
现在,路由会自动增加一个 /posts/:pk/ 的 URL 模式,其中 pk 为文章的 id。访问此 API 接口可以获得指定文章 id 的资源。
实际上,实现各个 action 逻辑的混入类都非常简单,以 RetrieveModelMixin 为例,我们来看看它的源码:
class RetrieveModelMixin:
"""
Retrieve a model instance.
"""
def retrieve(self, request, *args, **kwargs):
instance = self.get_object()
serializer = self.get_serializer(instance)
return Response(serializer.data)
retrieve 方法首先调用 get_object 方法获取需序列化的对象。get_object 方法通常情况下依据以下两点来筛选出单个资源对象:
get_queryset 方法(或者 queryset 属性,get_queryset 方法返回的值优先)返回的资源列表对象。lookup_field 属性指定的资源筛选字段(默认为 pk)。django-rest-framework 以该字段的值从 get_queryset 返回的资源列表中筛选出单个资源对象。lookup_field 字段的值将从请求的 URL 中捕获,所以你看到文章接口的 url 模式为 /posts/:pk/,假设将 lookup_field 指定为 title,则 url 模式为 /posts/:title/,此时将根据文章标题获取单篇文章资源。现在,假设我们要获取 id 为 1 的文章资源,访问获取单篇文章资源的 API 接口 http://127.0.0.1:10000/api/posts/1/,得到如下的返回结果:
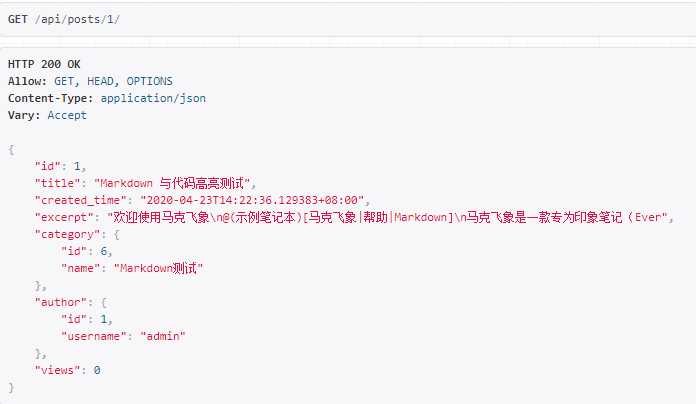
可以看到很多我们需要在详情页中展示的字段值并没有返回,比如文章正文(body)。原因是视图集中指定的文章序列化器为 PostListSerializer,这个序列化器被用于序列化文章列表。因为展示文章列表数据时,有些字段用不上,所以出于性能考虑,只序列化了部分字段。
显然,我们需要给文章详情写一个新的序列化器了:
from .models import Category, Post, Tag
class TagSerializer(serializers.ModelSerializer):
class Meta:
model = Tag
fields = [
"id",
"name",
]
class PostRetrieveSerializer(serializers.ModelSerializer):
category = CategorySerializer()
author = UserSerializer()
tags = TagSerializer(many=True)
class Meta:
model = Post
fields = [
"id",
"title",
"body",
"created_time",
"modified_time",
"excerpt",
"views",
"category",
"author",
"tags",
]
详情序列化器和列表序列化器几乎一样,只是在 fields 中指定了更多需要序列化的字段。
同时注意,为了序列化文章的标签 tags,我们新增了一个 TagSerializer,由于文章可能有多个标签,因为 tags 是一个列表,要序列化一个列表资源,需要将序列化器参数 many 的值指定为 True。
现在新的序列化器写好了,可是在哪里指定呢?视图集中 serializer_class 属性已经被指定为了 PostListSerializer,那 PostRetrieveSerializer 应该指定在哪呢?
类似于视图集类的 queryset 属性和 get_queryset 方法的关系, serializer_class 属性的值也可以通过 get_serializer_class 方法返回的值覆盖,因此我们可以根据不同的 action 动作来动态指定对应的序列化器。
那么如何在视图集中区分不同的 action 动作呢?视图集有一个 action 属性,专门用来记录当前请求对应的动作。对应关系如下:
| HTTP 请求 | 对应 action 属性的值 |
|---|---|
| GET | list(资源列表)/ retrieve(单个资源) |
| PUT | update |
| PATCH | partial_update |
| DELETE | destory |
因此,我们在视图集中重写 get_serializer_class 方法,写入我们自己的逻辑,就可以根据不同请求,分别获取相应的序列化器了:
class PostViewSet(
mixins.ListModelMixin, mixins.RetrieveModelMixin, viewsets.GenericViewSet
):
# ... 省略其他属性和方法
def get_serializer_class():
if self.action == ‘list‘:
return PostListSerializer
elif self.action == ‘retrieve‘:
return PostRetrieveSerializer
else:
return super().get_serializer_class()
后续对于其他动作,可以再加 elif 判断,不过如果动作变多了,就会有很多的 if 判断。更好的做好是,给视图集加一个属性,用于配置 action 和 serializer_class 的对应关系,通过查表法查找 action 应该使用的序列化器。
class PostDetailViewSet(viewsets.GenericViewSet):
# ... 省略其他属性和方法
serializer_class_table = {
‘list‘: PostListSerializer,
‘retrieve‘: PostRetrieveSerializer,
}
def get_serializer_class():
return self.serializer_class_table.get(
self.action, super().get_serializer_class()
)
现在,再次访问单篇文章 API 接口,可以看到返回了更加详细的博客文章数据了:


关注公众号加入交流群
标签:通过 性能 博客 www 自动 views 优先 framework 注意
原文地址:https://www.cnblogs.com/xueweihan/p/12984280.html