标签:同步 访问 tar redis 回滚 导致 作用 get 就是
如题,现在很多架构都采用了Redis+MySQL来进行存储,但是由于多方面的原因,总会导致Redis和MySQL之间出现数据的不一致性。
例如如果一个事务执行失败回滚了,但是如果采取了先写Redis的方式,就会造成Redis和MySQL数据库的不一致,再比如说,一个事务写入了MySQL,但是此时还未写入Redis,如果这时候有用户访问Redis,则此时就会出现数据不一致。
为了解决这些问题,本文将着重讨论,如何保证MySQL和Redis之间存在一个合理的数据一致性方案。
1、分别处理
针对某些对数据一致性要求不是特别高的情况下,可以将这些数据放入Redis,请求来了直接查询Redis,例如近期回复、历史排名这种实时性不强的业务。而针对那些强实时性的业务,例如虚拟货币、物品购买件数等等,则直接穿透Redis至MySQL上,等到MySQL上写入成功,再同步更新到Redis上去。这样既可以起到Redis的分流大量查询请求的作用,又保证了关键数据的一致性。
2、高并发情况下
此时如果写入请求较多,则直接写入Redis中去,然后间隔一段时间,批量将所有的写入请求,刷新到MySQL中去;如果此时写入请求不多,则可以在每次写入Redis,都立刻将该命令同步至MySQL中去。这两种方法有利有弊,需要根据不同的场景来权衡。
3、基于订阅binlog的同步机制
阿里巴巴的一款开源框架canal,提供了一种发布/ 订阅模式的同步机制,通过该框架我们可以对MySQL的binlog进行订阅,这样一旦MySQL中产生了新的写入、更新、删除等操作,就可以把binlog相关的消息推送至Redis,Redis再根据binlog中的记录,对Redis进行更新。值得注意的是,binlog需要手动打开,并且不会记录关于MySQL查询的命令和操作。
其实这种机制,很类似MySQL的主从备份机制,因为MySQL的主备也是通过binlog来实现的数据一致性。而canal正是模仿了slave数据库的备份请求,使得Redis的数据更新达到了相同的效果。如下图就可以看到Slave数据库中启动了2个线程,一个是MySQL SQL线程,这个线程跟Matser数据库中起的线程是一样的,负责MySQL的业务率执行,而另外一个线程就是MySQL的I/O线程,这个线程的主要作用就是同步Master 数据库中的binlog,达到数据备份的效果。而binlog就可以理解为一堆SQL语言组成的日志。
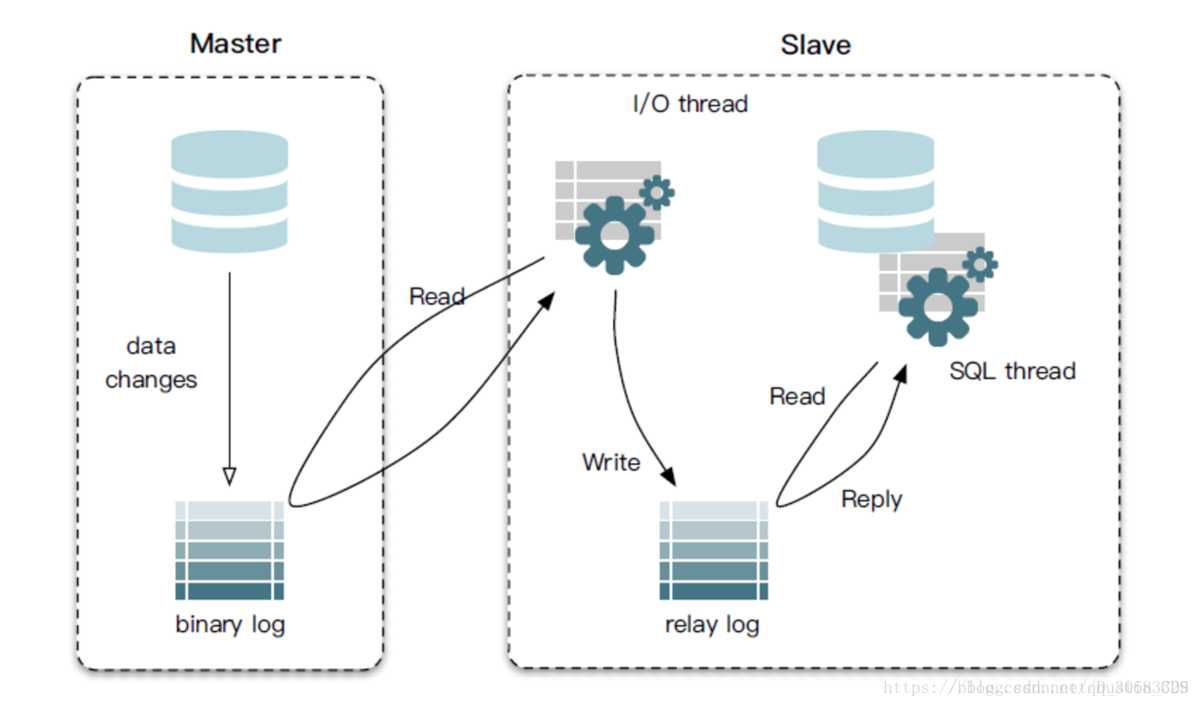
转载自CSDN博客:https://blog.csdn.net/qq_30683329/article/details/80543178
标签:同步 访问 tar redis 回滚 导致 作用 get 就是
原文地址:https://www.cnblogs.com/south-pigeon/p/12989327.html