标签:不可 总数 pidfile nosql hostname 范围 断线 ESS 特性
Redis是一种基于键值对的NoSQL数据库,与很多键值对数据库不同,redis中的值可以有string,hash,list,set,zset,geo等多种数据结构和算法组成.
因为Redis会将所有的数据都放在内存中,所以他的读写性能非常惊人.
不仅如此,Redis还可以将内存中的数据利用快照和日志的形式保存到硬盘上
Redis还提供了键过期,发布订阅,事务,流水线等附加功能.
1.速度快
Redis所有的数据都存放在内存中
Redis使用C语言实现
Redis使用单线程架构
2.基于键值对的数据结构服务器
5中数据结构:字符串,哈希,列表,集合,有序集合
3.丰富的功能
提供了键过期功能,可以实现缓存
提供了发布订阅功能,可以实现消息系统
提供了pipeline功能,客户端可以将一批命令一次性传到Redis,减少了网络开销
4.简单稳定
源码很少,3.0版本以后5万行左右.
使用单线程模型法,是的Redis服务端处理模型变得简单.
不依赖操作系统的中的类库
1.缓存-键过期时间
缓存session会话
缓存用户信息,找不到再去mysql查,查到然后回写到redis
2.排行榜-列表&有序集合
热度排名排行榜
发布时间排行榜
3.计数器应用-天然支持计数器
帖子浏览数
视频播放次数
商品浏览数
4.社交网络-集合
踩/赞,粉丝,共同好友/喜好,推送,打标签
5.消息队列系统-发布订阅
配合elk实现日志收集
#安装命令
[root@redis01 ~]# mkdir -p /server/tools
[root@redis01 ~]# mkdir -p /opt/redis_cluster/redis_6379/{conf,logs,pid}
[root@redis01 ~]#
[root@redis01 tools]# tar xf redis-3.2.9.tar.gz -C /opt/
[root@redis01 tools]#
[root@redis01 tools]# tar xf redis-3.2.9.tar.gz -C /opt/
[root@redis01 tools]# cd /opt/
[root@redis01 opt]# ln -s redis-3.2.9 redis
[root@redis01 opt]# cd /opt/redis
[root@redis01 redis]# make && make install
[root@redis01 redis]# cd utils/
[root@redis01 utils]# ./install_server.sh
Welcome to the redis service installer
This script will help you easily set up a running redis server
Please select the redis port for this instance: [6379]
Selecting default: 6379
Please select the redis config file name [/etc/redis/6379.conf] /opt/redis_cluster/redis_6379/conf/6379.conf
Please select the redis log file name [/var/log/redis_6379.log] /opt/redis_cluster/redis_6379/logs/redis_6379.log
Please select the data directory for this instance [/var/lib/redis/6379] /opt/redis_cluster/redis_6379/data
Please select the redis executable path [/usr/local/bin/redis-server]
Selected config:
Port : 6379
Config file : /opt/redis_cluster/redis_6379/conf/6379.conf
Log file : /opt/redis_cluster/redis_6379/logs/redis_6379.log
Data dir : /opt/redis_cluster/redis_6379/data
Executable : /usr/local/bin/redis-server
Cli Executable : /usr/local/bin/redis-cli
Is this ok? Then press ENTER to go on or Ctrl-C to abort.
Copied /tmp/6379.conf => /etc/init.d/redis_6379
Installing service...
Successfully added to chkconfig!
Successfully added to runlevels 345!
Starting Redis server...
Installation successful!
[root@redis01 utils]#
[root@redis01 utils]# cd /opt/redis_cluster/redis_6379/conf/
[root@redis01 conf]# vim 6379.conf
## 以守护进程模式启动
daemonize yes
### 绑定的主机地址
bind 10.0.1.131
### 监听端口
port 6379
### pid文件和log文件的保存地址
pidfile /opt/redis_cluster/redis_6379/pid/redis_6379.pid
logfile /opt/redis_cluster/redis_6379/logs/redis_6379.log
### 设置数据库的数量,默认数据库为0
databases 16
### 指定本地持久化文件的文件名,默认是dump.rdb
dbfilename redis_6379.rdb
### 本地数据库的目录
dir /opt/redis_cluster/redis_6379/data
#启动
[root@redis01 conf]# redis-server 6379.conf
#关闭
[root@redis01 conf]# redis-cli shutdown
[root@redis01 redis_6379]# redis-cli -h 10.0.1.131
#查看所有命键
10.0.1.131:6379> KEYS * #十分危险的命令,线上禁止使用
#查看键的总数
10.0.1.131:6379> DBSIZE
#检查键是否存在
10.0.1.131:6379> EXISTS key
#删除键
10.0.1.131:6379> DEL key #通用命令,无论值是什么数据结构类型,del命令都可以将其删除.
#键过期
10.0.1.131:6379> EXPIRE k1 10
# Redis支持对键添加过期时间,当超过过期时间后,会自动删除键.
# 通过ttl命令观察键的剩余时间
大于等于0的证书: 键剩余过期时间
-1: 键没设置过期时间
-2: 键不存在
#键的数据类型
10.0.1.131:6379> TYPE key
#保存到磁盘
10.0.1.131:6379> BGSAVE
#Redis并不是简单地key-value存储,实际上他是一个数据结构服务器,支持不同类型的值.
#Redis Strings
#这是最简单的Redis类型,如果你只用这种类型,Redis就像一个持久化的memcache服务器(注:memcache的数据仅保存在内存中,服务器重启后,数据将丢失.)
#操作命令:
#通常用SET command 和 GET command来设置和获取字符串值
10.0.1.131:6379> set k1 v1
OK
10.0.1.131:6379> get k1
"v1"
10.0.1.131:6379> keys *
1) "k1"
10.0.1.131:6379>
#INCR命令将字符串值解析成整型.将其加1,最后结果保存为新的字符串,类似命令: INCRBY,DECR,DECRBY
10.0.1.131:6379> set k1 1
OK
10.0.1.131:6379> get k1
"1"
10.0.1.131:6379> incr k1
(integer) 2
10.0.1.131:6379> incr k1
(integer) 3
10.0.1.131:6379> get k1
"3"
10.0.1.131:6379> incrby k1 100
(integer) 103
10.0.1.131:6379> get k1
"103"
10.0.1.131:6379> DECR k1
(integer) 102
10.0.1.131:6379> DECR k1
(integer) 101
10.0.1.131:6379> DECR k1
(integer) 100
10.0.1.131:6379> DECRBY k1 50
(integer) 50
10.0.1.131:6379> get k1
"50"
10.0.1.131:6379>
#MSET和MGET可以一次存储或获取多个key对应的值.
10.0.1.131:6379> mset k1 v1 k2 v2 k3 v3
OK
10.0.1.131:6379> mget k1 k2 k3
1) "v1"
2) "v2"
3) "v3"
10.0.1.131:6379>
#EXISTS命令返回1或0标识给定key的值是否存在.
#使用DEL命令可以删除key对应的值,
#DEL命令返回1或0标识是被删除(值存在)或者没被删除(key对应的值不存在).
10.0.1.131:6379> EXISTS k1
(integer) 1
10.0.1.131:6379> EXISTS k4
(integer) 0
10.0.1.131:6379> del k1
(integer) 1
10.0.1.131:6379> del k5
(integer) 0
10.0.1.131:6379>
#Type命令可以返回key对应的存储类型
10.0.1.131:6379> set k3 v3
OK
10.0.1.131:6379> TYPE k3
string
10.0.1.131:6379>
#可以对key设置一个超时时间,当这个时间到达后被删除
10.0.1.131:6379> set k3 v3
OK
10.0.1.131:6379> get k3
"v3"
10.0.1.131:6379> EXPIRE k3 10
(integer) 1
10.0.1.131:6379> ttl k3
(integer) 6
10.0.1.131:6379> ttl k3
(integer) 5
10.0.1.131:6379> ttl k3
(integer) -2
10.0.1.131:6379> get k3
(nil)
10.0.1.131:6379>
#PERSIST命令去除超时时间
10.0.1.131:6379> set k1 v1 ex 10
OK
10.0.1.131:6379> TTL k1
(integer) 9
10.0.1.131:6379> TTL k1
(integer) 8
10.0.1.131:6379> TTL k1
(integer) 6
10.0.1.131:6379> PERSIST k1
(integer) 1
10.0.1.131:6379> TTL k1
(integer) -1
10.0.1.131:6379>
#LPUSH命令可向list的左边(头部)添加一个新元素
#RPUSH命令可向list的右边(尾部)添加一个新元素.
#最后LRANGE可以从list中取出一定范围的元素
10.0.1.131:6379> RPUSH list a
(integer) 1
10.0.1.131:6379> RPUSH list b
(integer) 2
10.0.1.131:6379> LPUSH list 1
(integer) 3
10.0.1.131:6379> LPUSH list 2
(integer) 4
10.0.1.131:6379> LRANGE list 0 -1
1) "2"
2) "1"
3) "a"
4) "b"
10.0.1.131:6379> LRANGE list 1 -1
1) "1"
2) "a"
3) "b"
10.0.1.131:6379> LRANGE list 2 -1
1) "a"
2) "b"
10.0.1.131:6379>
#Pop,从list中删除元素并同时返回删除的值,可以在左边或右边操作.
10.0.1.131:6379> RPOP list
"b"
10.0.1.131:6379> LRANGE list 0 -1
1) "2"
2) "1"
3) "a"
10.0.1.131:6379> LPOP list
"2"
10.0.1.131:6379> LRANGE list 0 -1
1) "1"
2) "a"
10.0.1.131:6379>
#Hash看起来就像一个’hash’的样子.由键值对组成
#HSET设置单个域
#HMSET指令设置hash中的多个域
#HGET取回单个域.
#HMGET取回一系列的值
#HGETALL一次取所有值
10.0.1.131:6379> HSET user:1001 name li
(integer) 1
10.0.1.131:6379> HMSET user:1000 name opesn age 18 job it
OK
10.0.1.131:6379> hget user:1000 name
"opesn"
10.0.1.131:6379> hget user:1000 name age
(error) ERR wrong number of arguments for ‘hget‘ command
10.0.1.131:6379> hmget user:1000 name age
1) "opesn"
2) "18"
10.0.1.131:6379> HGETALL user:1000
1) "name"
2) "opesn"
3) "age"
4) "18"
5) "job"
6) "it"
10.0.1.131:6379> HMSET user:1000 qq 123456789
OK
10.0.1.131:6379> HGETALL user:1000
1) "name"
2) "opesn"
3) "age"
4) "18"
5) "job"
6) "it"
7) "qq"
8) "123456789"
10.0.1.131:6379>
#集合是字符串的无序排列,
#SADD指令把新的元素添加到set中
#smembers查看集合的值
10.0.1.131:6379> SADD set1 1 2 3
(integer) 3
10.0.1.131:6379> smembers set1
1) "1"
2) "2"
3) "3"
#和list类型不同,set集合不允许出现重复的元素
10.0.1.131:6379> SADD set1 1 4
(integer) 1
10.0.1.131:6379> smembers set1
1) "1"
2) "2"
3) "3"
4) "4"
10.0.1.131:6379>
#Srem用来删除指定的值
10.0.1.131:6379> SREM set1 2 4
(integer) 2
10.0.1.131:6379> SMEMBERS set1
1) "1"
2) "3"
10.0.1.131:6379>
#Sdiff计算集合的差异成员
10.0.1.131:6379> SADD set1 1 2 3 4
(integer) 2
10.0.1.131:6379> SADD set2 1 4 5
(integer) 3
10.0.1.131:6379> SDIFF set1 set2
1) "2"
2) "3"
10.0.1.131:6379>
#Sinter计算集合的交集
10.0.1.131:6379> SINTER set1 set2
1) "1"
2) "4"
10.0.1.131:6379>
#Sunion计算集合并集
10.0.1.131:6379> SUNION set1 set2
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
10.0.1.131:6379>
#RDB 持久化优缺点
可以在指定的时间间隔内生成数据集的 时间点快照(point-in-time snapshot)。
优点:速度快,适合于用做备份,主从复制也是基于RDB持久化功能实现的。
缺点:会有数据丢失
rdb持久化核心配置参数:
[root@redis01 redis_6379]# vim conf/6379.conf
save 900 1 #900秒(15分钟)内有1个更改
save 300 10 #300秒(5分钟)内有10个更改
save 60 10000 #60秒内有10000个更改
[root@redis01 redis_6379]# redis-cli -h 10.0.1.131 shutdown
[root@redis01 redis_6379]# redis-server conf/6379.conf
[root@redis01 redis_6379]#
#AOF 持久化(append-only log file)优缺点
记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集。
AOF 文件中的命令全部以 Redis 协议的格式来保存,新命令会被追加到文件的末尾。
优点:可以最大程度保证数据不丢
缺点:日志记录量级比较大
[root@redis01 redis_6379]# vim conf/6379.conf
appendonly yes #是否打开aof日志功能
appendfsync always #每1个命令,都立即同步到aof
appendfsync everysec #每秒写1次
appendfsync no #写入工作交给操作系统,由操作系统判断缓冲区大小,统一写入到aof.
appendfilename "appendonly.aof"
[root@redis01 redis_6379]# redis-cli -h 10.0.1.131 shutdown
[root@redis01 redis_6379]# redis-server conf/6379.conf
[root@redis01 redis_6379]#
redis默认开启了保护模式,只允许本地回环地址登录并访问数据库。
(1)Bind :指定IP进行监听
[root@redis01 opt]# vim redis_cluster/redis_6379/conf/6379.conf
bind 10.0.0.51 127.0.0.1
(2)增加requirepass {password}
[root@redis01 opt]# vim redis_cluster/redis_6379/conf/6379.conf
requirepass 123456
验证方法一:
[root@redis01 opt]# redis-cli -h 10.0.1.131 -a 123456
10.0.1.131:6379> set k1 v1
OK
10.0.1.131:6379>
验证方法二:
[root@redis01 opt]# redis-cli
127.0.0.1:6379> auth 123456
OK
127.0.0.1:6379> set k2 v2
OK
127.0.0.1:6379>
在分布式系统中为了解决单点问题,通常会把数据复制多个副本到其他机器,满足故障恢复和负载均衡等求.
Redis也是如此,提供了复制功能.
复制功能是高可用Redis的基础,后面的哨兵和集群都是在复制的基础上实现高可用的.
每个从节点只能有一个主节点,主节点可以有多个从节点.
配置复制的方式:
#在配置文件中加入slaveof {masterHost} {masterPort} 随redis启动生效.
[root@redis02 redis]# vim /opt/redis_cluster/redis_6379/conf/6379.conf
slaveof 10.0.1.131 6379
#直接使用命令:slaveof {masterHost} {masterPort}生效.
[root@redis02 redis]# redis-cli -h 10.0.1.132
10.0.1.132:6379> SLAVEOF 10.0.1.131 6379
#查看复制状态信息命令
10.0.1.132:6379> info replication
# Replication
role:slave
master_host:10.0.1.131
master_port:6379
master_link_status:up
master_last_io_seconds_ago:5
master_sync_in_progress:0
slave_repl_offset:15
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
#断开复制
Slaveof命令不但可以建立复制,还可以在从节点执行slaveof no one来断开与主节点复制关系.
断开复制主要流程:
1.断开与主节点复制关系
10.0.1.132:6379> SLAVEOF no one
OK
10.0.1.132:6379>
2.从节点晋升为主节点
从节点断开复制后不会抛弃原有数据,只是无法再获取主节点上的数据变化.
通过slaveof命令还可以实现切主操作,所谓切主是指把当前从节点对主节点的复制切换到另一个主节点.
执行slaveof {newMasterIp} {newMasterPort}命令即可.
切主操作流程如下:
1.断开与旧主节点的复制关系
2.与新主节点建立复制关系
3.删除从节点当前所有数据
4.对新主节点进行复制操作
提示: 线上操作一定要小心,因为切主后会清空之前所有的数据.
Redis Sentinel 是一个分布式系统, Redis Sentinel为Redis提供高可用性。可以在没有人为干预的情况下阻止某种类型的故障。
Redis 的 Sentinel 系统用于管理多个 Redis 服务器(instance)该系统执行以下三个任务:
1.监控(Monitoring):
Sentinel 会不断地定期检查你的主服务器和从服务器是否运作正常。
2.提醒(Notification):
当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
3.自动故障迁移(Automatic failover):
当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器
| 主机名 | ip地址 |
|---|---|
| redis01 | 10.0.1.131 |
| redis02 | 10.0.1.132 |
| redis03 | 10.0.1.133 |
[root@redis01 opt]# vim redis_cluster/redis_6379/conf/6379.conf
#redis01配置(redis02和redis03相同)区别于各种IP不同
[root@redis01 opt]# mkdir -p /opt/redis_cluster/redis_26379/{conf,pid,logs,data}
[root@redis01 opt]# vim /opt/redis_cluster/redis_26379/conf/26379.conf
bind 10.0.0.131 127.0.0.1
port 26379
daemonize yes
logfile /opt/redis_cluster/redis_26379/logs/redis_26379.log
dir /opt/redis_cluster/redis_26379/data/
sentinel monitor mymaster 10.0.0.131 6379 2
sentinel down-after-milliseconds mymaster 3000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 18000
#配置文件解释
#mymaster主节点别名 主节点 ip 和端口,判断主节点失败,两个 sentinel 节点同意
sentinel monitor mymaster 10.0.0.51 6379 2
#选项指定了 Sentinel 认为服务器已经断线所需的毫秒数。
sentinel down-after-milliseconds mymaster 30000
#向新的主节点发起复制操作的从节点个数,1轮询发起复制
sentinel parallel-syncs mymaster 1
#故障转移超时时间
sentinel failover-timeout mymaster 180000
#配置主从关系
#edis02和redis03
[root@redis02 redis]# redis-server /opt/redis_cluster/redis_6379/conf/6379.conf
[root@redis02 redis]# redis-cli slaveof 10.0.1.131 6379
#启动哨兵
3台都操作
[root@redis01 opt]# redis-sentinel /opt/redis_cluster/redis_26379/conf/26379.conf
#查看变化的配置文件
当所有节点启动后,配置文件的内容发生了变化,体现在三个方面:
1)Sentinel节点自动发现了从节点,其余Sentinel节点
2)去掉了默认配置,例如parallel-syncs failover-timeout参数
3)添加了配置纪元相关参数
#查看变化的配置文件
[root@redis01 opt]# cat /opt/redis_cluster/redis_26379/conf/26379.conf
bind 10.0.1.131 127.0.0.1
port 26379
daemonize yes
logfile "/opt/redis_cluster/redis_26379/logs/redis_26379.log"
dir "/opt/redis_cluster/redis_26379/data"
sentinel myid 430f510658aade5ca2434d844bfd9e78eee23e55
sentinel monitor mymaster 10.0.1.131 6379 2
sentinel down-after-milliseconds mymaster 3000
sentinel failover-timeout mymaster 18000
# Generated by CONFIG REWRITE
sentinel config-epoch mymaster 0
sentinel leader-epoch mymaster 0
sentinel known-slave mymaster 10.0.1.132 6379
sentinel known-slave mymaster 10.0.1.133 6379
sentinel known-sentinel mymaster 10.0.1.133 26379 91185fc5f8ed669b09492928aee5353ae6019426
sentinel known-sentinel mymaster 10.0.1.132 26379 4247fe6730351c9b7c462c897aebd34b00dc0daa
sentinel current-epoch 0
[root@redis01 opt]#
#哨兵常用操作API
[root@redis01 opt]# redis-cli -h 10.0.1.131 -p 26379
Sentinel节点是一个特殊的Redis节点,他们有自己专属的API
Info Sentinel
Sentinel masters
Sentinel master <master name>
Sentinel slaves <master name>
Sentinel sentinels <master name>
Sentinel get-master-addr-by-name <master name>
Sentinel failover <master name>
Sentinel flushconfig
#edis Sentinel存在多个从节点时,如果想将指定的从节点晋升为主节点,可以将其他从节点的slavepriority配置为0,但是需要注意failover后,将slave-priority调回原值.
1.查询命令:CONFIG GET slave-priority
2.设置命令:CONFIG SET slave-priority 0
3.主动切换:sentinel failover mymaster
#操作过程
#redis01和redis02操作
[root@redis01 opt]# redis-cli -h 10.0.1.131 -p 6379 CONFIG SET slave-priority 0
[root@redis02 redis]# redis-cli -h 10.0.1.132 -p 6379 CONFIG SET slave-priority 0
#redis03操作
[root@redis03 opt]# redis-cli -h 10.0.1.133 -p 26379 Sentinel failover mymaster
Redis Cluster 是 redis的分布式解决方案,在3.0版本正式推出
当遇到单机、内存、并发、流量等瓶颈时,可以采用Cluster架构方案达到负载均衡目的。
分布式数据库首先要解决把整个数据库集按照分区规则映射到多个节点的问题,即把数据集划分到多个节点上,每个节点负责整体数据的一个子集,需要关注的是数据分片规则,Redis Cluster采用哈希分片规则。
集群拓扑
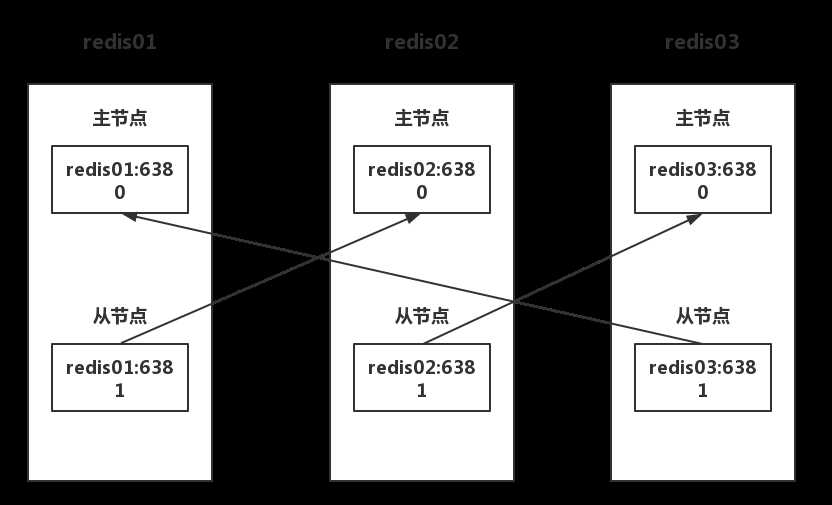
#目录规划
# redis安装目录
/opt/redis_cluster/redis_{PORT}/{conf,logs,pid}
# redis数据目录
/data/redis_cluster/redis_{PORT}/redis_{PORT}.rdb
# redis运维脚本
/root/scripts/redis_shell.sh
[root@redis01 scripts]# cat redis_shell.sh
#!/bin/bash
USAG(){
echo "sh $0 {start|stop|restart|login|ps|tail} PORT"
}
if [ "$#" = 1 ]
then
REDIS_PORT=‘6379‘
elif
[ "$#" = 2 -a -z "$(echo "$2"|sed ‘s#[0-9]##g‘)" ]
then
REDIS_PORT="$2"
else
USAG
exit 0
fi
REDIS_IP=$(hostname -I|awk ‘{print $1}‘)
PATH_DIR=/opt/redis_cluster/redis_${REDIS_PORT}/
PATH_CONF=/opt/redis_cluster/redis_${REDIS_PORT}/conf/redis_${REDIS_PORT}.conf
PATH_LOG=/opt/redis_cluster/redis_${REDIS_PORT}/logs/redis_${REDIS_PORT}.log
CMD_START(){
redis-server ${PATH_CONF}
}
CMD_SHUTDOWN(){
redis-cli -c -h ${REDIS_IP} -p ${REDIS_PORT} shutdown
}
CMD_LOGIN(){
redis-cli -c -h ${REDIS_IP} -p ${REDIS_PORT}
}
CMD_PS(){
ps -ef|grep redis
}
CMD_TAIL(){
tail -f ${PATH_LOG}
}
case $1 in
start)
CMD_START
CMD_PS
;;
stop)
CMD_SHUTDOWN
CMD_PS
;;
restart)
CMD_START
CMD_SHUTDOWN
CMD_PS
;;
login)
CMD_LOGIN
;;
ps)
CMD_PS
;;
tail)
CMD_TAIL
;;
*)
USAG
esac
[root@redis01 scripts]#
#redis01操作:
[root@redis01 ~]# mkdir -p /opt/redis_cluster/redis_{6380,6381}/{conf,logs,pid}
[root@redis01 ~]# mkdir -p /data/redis_cluster/redis_{6380,6381}
[root@redis01 ~]# cat /opt/redis_cluster/redis_6380/conf/redis_6380.conf
bind 10.0.1.131
port 6380
daemonize yes
pidfile "/opt/redis_cluster/redis_6380/pid/redis_6380.pid"
logfile "/opt/redis_cluster/redis_6380/logs/redis_6380.log"
dbfilename "redis_6380.rdb"
dir "/data/redis_cluster/redis_6380/"
cluster-enabled yes
cluster-config-file nodes_6380.conf
cluster-node-timeout 15000
[root@redis01 ~]# cd /opt/redis_cluster/
[root@redis01 redis_cluster]# cp redis_6380/conf/redis_6380.conf redis_6381/conf/redis_6381.conf
[root@redis01 redis_cluster]# sed -i ‘s#6380#6381#g‘ redis_6381/conf/redis_6381.conf
[root@redis01 redis_cluster]# rsync -avz /opt/redis_cluster/redis_638* redis02:/opt/redis_cluster/
[root@redis01 redis_cluster]# rsync -avz /opt/redis_cluster/redis_638* redis03:/opt/redis_cluster/
[root@redis01 redis_cluster]# redis-server /opt/redis_cluster/redis_6380/conf/redis_6380.conf
[root@redis01 redis_cluster]# redis-server /opt/redis_cluster/redis_6381/conf/redis_6381.conf
#redis02操作:
[root@redis02 ~]# find /opt/redis_cluster/redis_638* -type f -name "*.conf"|xargs sed -i "/bind/s#131#132#g"
[root@redis02 ~]# mkdir -p /data/redis_cluster/redis_{6380,6381}
[root@redis02 ~]# redis-server /opt/redis_cluster/redis_6380/conf/redis_6380.conf
[root@redis02 ~]# redis-server /opt/redis_cluster/redis_6381/conf/redis_6381.conf
#db03操作:
[root@redis03 ~]# find /opt/redis_cluster/redis_638* -type f -name "*.conf"|xargs sed -i "/bind/s#131#133#g"
[root@redis03 ~]# mkdir -p /data/redis_cluster/redis_{6380,6381}
[root@redis03 ~]# redis-server /opt/redis_cluster/redis_6380/conf/redis_6380.conf
[root@redis03 ~]# redis-server /opt/redis_cluster/redis_6381/conf/redis_6381.conf
#检查
[root@redis01 ~]# ps -ef |grep redis
root 2445 1 0 22:14 ? 00:00:00 redis-server 10.0.1.131:6380 [cluster]
root 2449 1 0 22:14 ? 00:00:00 redis-server 10.0.1.131:6381 [cluster]
#文件解释
[root@redis01 ~]# cat /opt/redis_cluster/redis_6380/conf/redis_6380.conf
bind 10.0.1.131
port 6380
daemonize yes
pidfile "/opt/redis_cluster/redis_6380/pid/redis_6380.pid"
logfile "/opt/redis_cluster/redis_6380/logs/redis_6380.log"
dbfilename "redis_6380.rdb"
dir "/data/redis_cluster/redis_6380/"
cluster-enabled yes #激活集群模式
cluster-config-file nodes_6380.conf #集群配置文件
cluster-node-timeout 15000 #集群的超时时间
[root@redis03 ~]# cat /data/redis_cluster/redis_6380/nodes_6380.conf
75fd5640e452981994295e6a2e190dc137f11b34 :0 myself,master - 0 0 0 connected
vars currentEpoch 0 lastVoteEpoch 0
[root@redis03 ~]#
当把所有节点都启动后查看进程会有cluster的字样
但是登录后执行CLUSTER NODES命令会发现只有每个节点自己的ID,目前集群内的节点
还没有互相发现,所以搭建redis集群我们第一步要做的就是让集群内的节点互相发现.
在执行节点发现命令之前我们先查看一下集群的数据目录会发现有生成集群的配置文件
查看后发现只有自己的节点内容,等节点全部发现后会把所发现的节点ID写入这个文件
集群模式的Redis除了原有的配置文件之外又加了一份集群配置文件.当集群内节点
信息发生变化,如添加节点,节点下线,故障转移等.节点会自动保存集群状态到配置文件.
需要注意的是,Redis自动维护集群配置文件,不需要手动修改,防止节点重启时产生错乱.
节点发现使用命令: CLUSTER MEET {IP} {PORT}
提示:在集群内任意一台机器执行此命令就可以
[root@redis01 ~]# /root/scripts/redis_shell.sh login 6380
10.0.1.131:6380> CLUSTER MEET 10.0.1.132 6380
OK
10.0.1.131:6380> CLUSTER MEET 10.0.1.133 6380
OK
10.0.1.131:6380> CLUSTER MEET 10.0.1.131 6381
OK
10.0.1.131:6380> CLUSTER MEET 10.0.1.132 6381
OK
10.0.1.131:6380> CLUSTER MEET 10.0.1.133 6381
OK
10.0.1.131:6380> CLUSTER NODES
910c89613120af8559c581ca338d3e0700f75672 10.0.1.133:6381 master - 0 1572446501946 5 connected
75fd5640e452981994295e6a2e190dc137f11b34 10.0.1.133:6380 master - 0 1572446503963 2 connected
bc92ae6e773fa7c5af1e49e77def3d115e1179cb 10.0.1.131:6381 master - 0 1572446504970 3 connected
ec4a934eaf0525bf312f7c2159d13ac9b3c2786a 10.0.1.131:6380 myself,master - 0 0 0 connected
e49eb348d23c56ea9501e3939efffb05ba379dda 10.0.1.132:6380 master - 0 1572446499932 1 connected
b4e46cd903320d7920b463c061a696349304a3de 10.0.1.132:6381 master - 0 1572446502955 4 connected
10.0.1.131:6380>
节点都发现完毕后我们再次查看集群配置文件
可以看到,发现到的节点的ID也被写入到了集群的配置文件里
在分布式存储中需要提供维护节点元数据信息的机制,所谓元数据是指:节点负责哪些数据,是否出现故障灯状态信息,redis 集群采用 Gossip(流言)协议,Gossip 协议工作原理就是节点彼此不断交换信息,一段时间后所有的节点都会知道集群完整信息,这种方式类似流言传播。
通信过程:
1)集群中的每一个节点都会单独开辟一个 Tcp 通道,用于节点之间彼此通信,通信端口在基础端口上加10000.
2)每个节点在固定周期内通过特定规则选择结构节点发送 ping 消息
3)接收到 ping 消息的节点用 pong 消息作为响应。集群中每个节点通过一定规则挑选要通信的节点,每个节点可能知道全部节点,也可能仅知道部分节点,只要这些节点彼此可以正常通信,最终他们会打成一致的状态,当节点出现故障,新节点加入,主从角色变化等,它能够给不断的ping/pong消息,从而达到同步目的。
通讯消息类型:
Gossip
Gossip 协议职责就是信息交换,信息交换的载体就是节点间彼此发送Gossip 消息。
常见 Gossip 消息分为:ping、 pong、 meet、 fail 等
meet
meet 消息:用于通知新节点加入,消息发送者通知接受者加入到当前集群,meet 消息通信正常完成后,接收节点会加入到集群中并进行ping、 pong 消息交换
ping
ping 消息:集群内交换最频繁的消息,集群内每个节点每秒想多个其他节点发送 ping 消息,用于检测节点是否在线和交换彼此信息。
pong
Pong 消息:当接收到 ping,meet 消息时,作为相应消息回复给发送方确认消息正常通信,节点也可以向集群内广播自身的 pong 消息来通知整个集群对自身状态进行更新。
fail
fail 消息:当节点判定集群内另一个节点下线时,回向集群内广播一个fail 消息,其他节点收到 fail 消息之后把对应节点更新为下线状态。
虽然节点之间已经互相发现了,但是此时集群还是不可用的状态,因为并没有给节点分配槽位,而且必须是所有的槽位都分配完毕后整个集群才是可用的状态.
反之,也就是说只要有一个槽位没有分配,那么整个集群就是不可用的.
#测试命令:
10.0.1.131:6380> CLUSTER INFO
cluster_state:fail
cluster_slots_assigned:0
cluster_slots_ok:0
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:0
cluster_current_epoch:5
cluster_my_epoch:0
cluster_stats_messages_sent:2703
cluster_stats_messages_received:2703
10.0.1.131:6380>
前面说了,我们虽然有6个节点,但是真正负责数据写入的只有3个节点,其他3个节点只是作为主节点的从节点,也就是说,只需要分配期中三个节点的槽位就可以了
分配槽位的方法:
分配槽位需要在每个主节点上来配置,此时有2种方法执行:
1.分别登录到每个主节点的客户端来执行命令
2.在其中一台机器上用redis客户端远程登录到其他机器的主节点上执行命令
每个节点执行命令:
[root@redis01 ~]# redis-cli -h redis01 -p 6380 cluster addslots {0..5461}
OK
[root@redis01 ~]# redis-cli -h redis02 -p 6380 cluster addslots {5462..10922}
OK
[root@redis01 ~]# redis-cli -h redis03 -p 6380 cluster addslots {10923..16383}
OK
[root@redis01 ~]#
分配完所有槽位之后我们再查看一下集群的节点状态和集群状态
可以看到三个节点都分配了槽位,而且集群的状态是OK的
[root@redis01 ~]# /root/scripts/redis_shell.sh login 6380
10.0.1.131:6380> CLUSTER INFO
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:5
cluster_my_epoch:0
cluster_stats_messages_sent:2946
cluster_stats_messages_received:2946
10.0.1.131:6380>
再集群模式下,redis接受任何键相关命令时首先会计算键对应的槽,再根据槽找出所对应的节点如果节点是自身,则处理键命令;否则回复MOVED重定向错误,通知客户端请求正确的节点,这个过程称为Mover重定向.
#知道了ask路由后,使用-c选项批量插入一些数据
[root@redis01 ~]# cat input_key.sh
#!/bin/bash
for i in $(seq 1 10)
do
redis-cli -c -h redis01 -p 6380 set k_${i} v_${i} && echo "set k_${i} is ok"
done
[root@redis01 ~]#
#写入后同样使用-c选项来读取刚才插入的键值
[root@redis01 ~]# redis-cli -c -h redis01 -p 6380
redis01:6380> get k_1
"v_1"
redis01:6380> get k_2
-> Redirected to slot [8970] located at 10.0.1.132:6380
"v_2"
10.0.1.132:6380> get k_3
-> Redirected to slot [13099] located at 10.0.1.133:6380
"v_3"
10.0.1.133:6380>
手动搭建集群便于理解集群创建的流程和细节,不过手动搭建集群需要很多步骤,当集群节点众多时,必然会加大搭建集群的复杂度和运维成本,因此官方提供了 redis-trib.rb的工具方便我们快速搭建集群。
redis-trib.rb是采用 Ruby 实现的 redis 集群管理工具,内部通过 Cluster相关命令帮我们简化集群创建、检查、槽迁移和均衡等常见运维操作,使用前要安装 ruby 依赖环境
#安装命令:
[root@redis01 ~]# yum makecache fast
[root@redis01 ~]# yum -y install rubygems
[root@redis01 ~]# gem sources --remove https://rubygems.org/
[root@redis01 ~]# gem sources -a http://mirrors.aliyun.com/rubygems/
[root@redis01 ~]# gem update - system
[root@redis01 ~]# gem install redis -v 3.3.5
#停掉所有的节点,然后清空数据,恢复成一个全新的集群,所有机器执行命令
[root@redis01 ~]# pkill redis
[root@redis01 ~]# rm -rf /data/redis_cluster/redis_6380/*
[root@redis01 ~]# rm -rf /data/redis_cluster/redis_6381/*
#全部清空之后启动所有的节点,所有机器执行
[root@redis01 ~]# redis-server /opt/redis_cluster/redis_6380/conf/redis_6380.conf
[root@redis01 ~]# redis-server /opt/redis_cluster/redis_6381/conf/redis_6381.conf
#redis01执行创建集群命令
[root@redis01 ~]# cd /opt/redis/src/
[root@redis01 src]# ./redis-trib.rb create --replicas 1 10.0.1.131:6380 10.0.1.132:6380 10.0.1.133:6380 10.0.1.131:6381 10.0.1.132:6381 10.0.1.133:6381
#修改复制关系
[root@redis02 ~]# redis-cli -h redis02 -p 6381
redis02:6381> CLUSTER NODES
2e0e29100c0ad475c43e7fb583cff418e42c43d7 10.0.1.132:6380 master - 0 1572488398750 2 connected 5461-10922
9607df0524777302cb2e380bb042b831d183ccae 10.0.1.131:6381 slave 2e0e29100c0ad475c43e7fb583cff418e42c43d7 0 1572488400764 4 connected
3c82d4c7bd0404be1012be0e39a376f286646d5e 10.0.1.133:6381 slave a38fc2b288b3c7a6aa87a55ba919cbd63814ba1d 0 1572488399758 6 connected
d556202e32afc667b0cefd9311d25f62142e1cdc 10.0.1.131:6380 master - 0 1572488397746 1 connected 0-5460
a38fc2b288b3c7a6aa87a55ba919cbd63814ba1d 10.0.1.133:6380 master - 0 1572488395731 3 connected 10923-16383
5036009a8dd400a37cf17538b73132fea51d0ad1 10.0.1.132:6381 myself,slave d556202e32afc667b0cefd9311d25f62142e1cdc 0 0 5 connected
#redis02
[root@redis02 ~]# redis-cli -h redis02 -p 6381
redis02:6381> CLUSTER REPLICATE a38fc2b288b3c7a6aa87a55ba919cbd63814ba1d
#redis03
[root@redis03 ~]# redis-cli -h redis03 -p 6381
redis03:6381> CLUSTER REPLICATE d556202e32afc667b0cefd9311d25f62142e1cdc
#检查集群完整性
[root@redis01 src]# ./redis-trib.rb check 10.0.1.131:6380
#检查集群负载平均
[root@redis01 src]# ./redis-trib.rb rebalance 10.0.1.131:6380
Redis集群的扩容操作可分为以下几个步骤
1)准备新节点
2)加入集群
3)迁移槽和数据
#在redis01上创建2个新节点
[root@redis01 ~]# mkdir -p /opt/redis_cluster/redis_{6390,6391}/{conf,logs,pid}
[root@redis01 ~]# mkdir -p /data/redis_cluster/redis_{6390,6391}
[root@redis01 ~]# cd /opt/redis_cluster/
[root@redis01 redis_cluster]# cp redis_6380/conf/redis_6380.conf redis_6390/conf/redis_6390.conf
[root@redis01 redis_cluster]# cp redis_6380/conf/redis_6380.conf redis_6391/conf/redis_6391.conf
[root@redis01 redis_cluster]# sed -i ‘s#6380#6390#g‘ redis_6390/conf/redis_6390.conf
[root@redis01 redis_cluster]# sed -i ‘s#6380#6391#g‘ redis_6391/conf/redis_6391.conf
[root@redis01 redis_cluster]#
#启动节点
[root@redis01 ~]# redis-server /opt/redis_cluster/redis_6390/conf/redis_6390.conf
[root@redis01 ~]# redis-server /opt/redis_cluster/redis_6391/conf/redis_6391.conf
#发现节点
[root@redis01 ~]# redis-cli -c -h redis01 -p 6380 cluster meet 10.0.1.131 6390
[root@redis01 ~]# redis-cli -c -h redis01 -p 6380 cluster meet 10.0.1.131 6391
#或者
[root@redis01 src]# ./redis-trib.rb add-node 10.0.1.131:6390 10.0.1.131:6380
[root@redis01 src]# ./redis-trib.rb add-node 10.0.1.131:6391 10.0.1.131:6380
#使用工具扩容
[root@redis01 src]# ./redis-trib.rb reshard 10.0.1.131:6380
#打印出集群每个节点信息后,reshard命令需要确认迁移的槽数量,这里输入4096个:
How many slots do you want to move (from 1 to 16384)? 4096
#输入6390的节点ID作为目标节点,也就是要扩容的节点,目标节点只能指定一个
What is the receiving node ID? c2d62daf93ab3495c546990272c852fcb9b64da7
#输入源节点的ID,这里分别输入每个主节点的6380的ID最后输入done,或者直接输入all
Source node #1:all
#迁移完成后命令会自动退出,这时候查看一下集群的状态
[root@redis01 src]# ./redis-trib.rb rebalance 10.0.1.131:6380
#修改复制关系
10.0.1.131:6380> CLUSTER NODES
2b7a7b7805b753087a0eff6a312cf9c2ad694489 10.0.1.131:6391 master - 0 1572490914610 7 connected
a38fc2b288b3c7a6aa87a55ba919cbd63814ba1d 10.0.1.133:6380 master - 0 1572490919140 3 connected 12288-16383
c2d62daf93ab3495c546990272c852fcb9b64da7 10.0.1.131:6390 master - 0 1572490919645 8 connected 0-1364 5461-6826 10923-12287
9607df0524777302cb2e380bb042b831d183ccae 10.0.1.131:6381 slave 2e0e29100c0ad475c43e7fb583cff418e42c43d7 0 1572490918133 4 connected
5036009a8dd400a37cf17538b73132fea51d0ad1 10.0.1.132:6381 slave a38fc2b288b3c7a6aa87a55ba919cbd63814ba1d 0 1572490918133 5 connected
d556202e32afc667b0cefd9311d25f62142e1cdc 10.0.1.131:6380 myself,master - 0 0 1 connected 1365-5460
2e0e29100c0ad475c43e7fb583cff418e42c43d7 10.0.1.132:6380 master - 0 1572490917629 2 connected 6827-10922
3c82d4c7bd0404be1012be0e39a376f286646d5e 10.0.1.133:6381 slave d556202e32afc667b0cefd9311d25f62142e1cdc 0 1572490918637 6 connected
10.0.1.131:6380>
#redis03
[root@redis03 ~]# redis-cli -h redis03 -p 6381
redis03:6381> CLUSTER REPLICATE c2d62daf93ab3495c546990272c852fcb9b64da7
#redis01:6391
[root@redis01 ~]# /root/scripts/redis_shell.sh login 6391
10.0.1.131:6391> CLUSTER REPLICATE d556202e32afc667b0cefd9311d25f62142e1cdc
流程说明
1).首先需要确定下线节点是否有负责的槽,
如果是,需要把槽迁移到其他节点,保证节点下线后整个集群槽节点映射的完整性.
2).当下线节点不再负责槽或者本身是从节点时,
就可以通知集群内其他节点忘记下线节点,当所有的节点忘记该节点后可以正常关闭.
这里我们准备将刚才新添加的节点下线,也就是6390和6391
收缩和扩容迁移的方向相反,6390变为源节点,其他节点变为目标节点,源节点把自己负责的4096个槽均匀的迁移到其他节点上.
#由于redis-trib..rb reshard命令只能有一个目标节点,因此需要执行3次reshard命令,分别迁移1365,1365,1366个槽.
[root@redis01 ~]# cd /opt/redis/src/
[root@redis01 src]# ./redis-trib.rb reshard 10.0.1.131:6380
How many slots do you want to move (from 1 to 16384)? 1365
What is the receiving node ID? d556202e32afc667b0cefd9311d25f62142e1cdc #目标id
Source node #1:c2d62daf93ab3495c546990272c852fcb9b64da7 #源id
Source node #2:done
#忘记节点
由于我们的集群是做了高可用的,所以当主节点下线的时候从节点也会顶上,所以最好我们先下线从节点,然后在下线主节点
[root@redis01 src]# ./redis-trib.rb del-node 10.0.1.131:6391 2b7a7b7805b753087a0eff6a312cf9c2ad694489
[root@redis01 src]# ./redis-trib.rb del-node 10.0.1.131:6390 c2d62daf93ab3495c546990272c852fcb9b64da7
刚切换到redis集群的时候肯定会面临数据导入的问题,所以这里推荐使用redis-migrate-tool工具来导入单节点数据到集群里
官方地址:
http://www.oschina.net/p/redis-migrate-tool
#安装工具
[root@redis01 src]# cd /opt/redis_cluster/
[root@redis01 redis_cluster]# git clone https://github.com/vipshop/redis-migrate-tool.git
[root@redis01 redis_cluster]# cd redis-migrate-tool/
[root@redis01 redis-migrate-tool]# autoreconf -fvi
[root@redis01 redis-migrate-tool]# ./configure
[root@redis01 redis-migrate-tool]# make && make install
#创建配置文件
[root@redis01 ~]# cat redis_6379_to_6380.conf
[source]
type: single
servers:
- 10.0.1.131:6379
[target]
type: redis cluster
servers:
- 10.0.1.131:6380
[common]
listen: 0.0.0.0:8888
source_safe: true
[root@redis01 ~]#
#生成测试数据
[root@redis01 ~]# cat input_key.sh
#!/bin/bash
for i in $(seq 1 10)
do
redis-cli -c -h redis01 -p 6379 set opesn_${i} opesn_${i} && echo "set opesn_${i} is ok"
done
[root@redis01 ~]#
#执行导入命令
[root@redis01 ~]# redis-migrate-tool -c redis_6379_to_6380.conf
#数据校验
[root@redis01 ~]# redis-migrate-tool -c redis_6379_to_6380.conf -C redis_check
redis的内存使用太大键值太多,不知道哪些键值占用的容量比较大,而且在线分析会影响性能.
#安装工具
[root@redis01 ~]# yum -y install python-pip gcc python-devel
[root@redis01 ~]# cd /opt/
[root@redis01 opt]# git clone https://github.com/sripathikrishnan/redis-rdb-tools
[root@redis01 opt]# cd redis-rdb-tools/
[root@redis01 redis-rdb-tools]# python setup.py install
[root@redis01 redis_6380]# pip install python-lzf
#使用方法
[root@redis01 redis-rdb-tools]# cd /data/redis_cluster/redis_6380/
[root@redis01 redis_6380]# rdb -c memory redis_6380.rdb -f redis_6380.rdb.csv
#分析rdb并导出
[root@redis01 redis_6380]# awk -F "," ‘{print $4,$2,$3,$1}‘ redis_6380.rdb.csv |sort > 6380.txt
标签:不可 总数 pidfile nosql hostname 范围 断线 ESS 特性
原文地址:https://www.cnblogs.com/opesn/p/12994107.html