标签:循环 堆内存 算法 开始 eset shm 容器 完全 set
一、集合
- Java 中的集合类存放于 java.util 包中,是一个存放对象的容器。
- 集合存放的是对对象的引用,对象本身还是存在于 JVM 堆内存中。
- 存放的是对象,即引用数据类型,对于基本数据类型采用自动装箱存储。
- 集合可以存放不同类型(一般情况下声明一个集合时会通过泛型进行约束),不限数量的数据类型。
- Java 中的集合主要分为两种,单列集合:Collection,双列集合 Map。
二、Collection
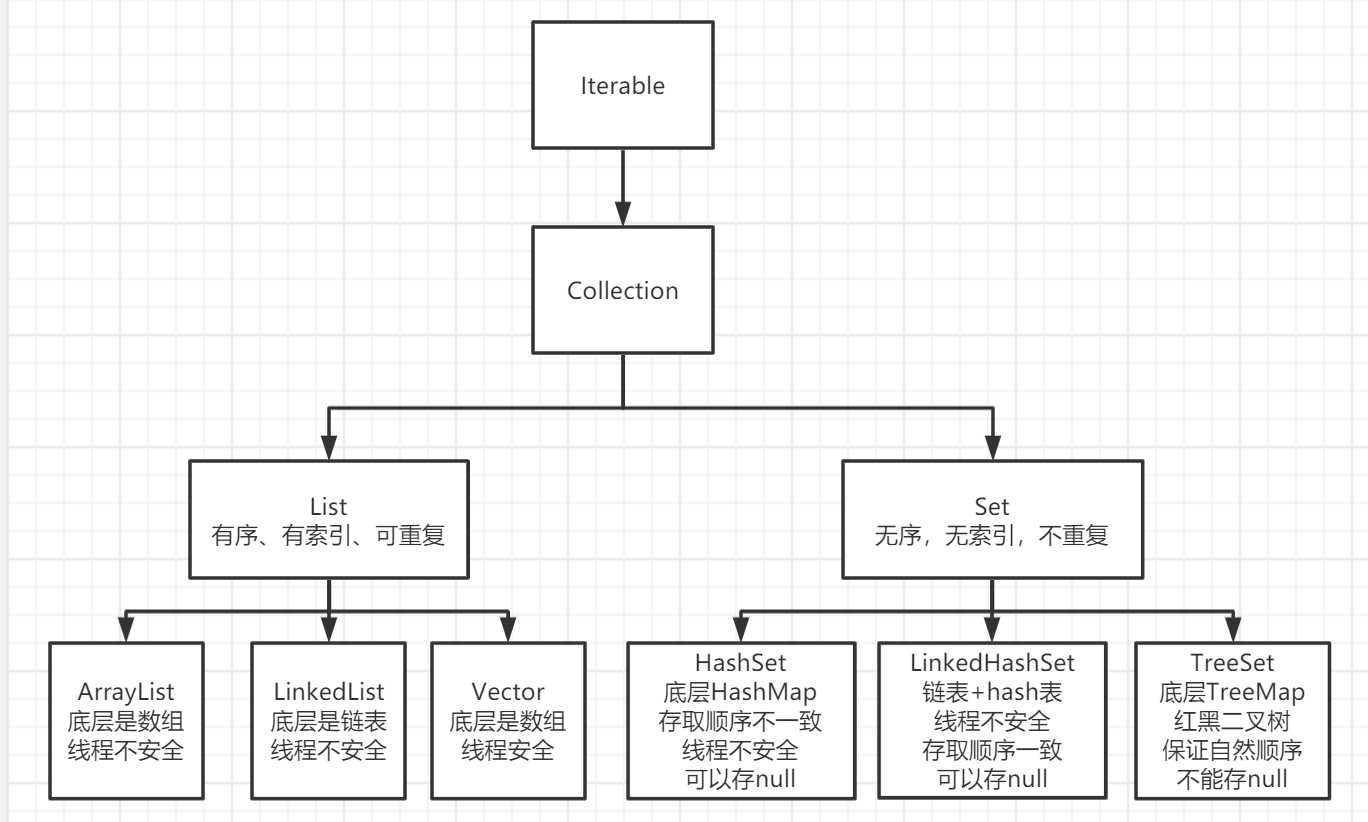
2.1、Iterable && Collection
1. Iterable
Iterable 接口是 JDK1.5 后引入的,支持 foreach 循环遍历,和返回一个迭代器。
Iterator<T> iterator();
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
default Spliterator<T> spliterator() {
return Spliterators.spliteratorUnknownSize(iterator(), 0);
}
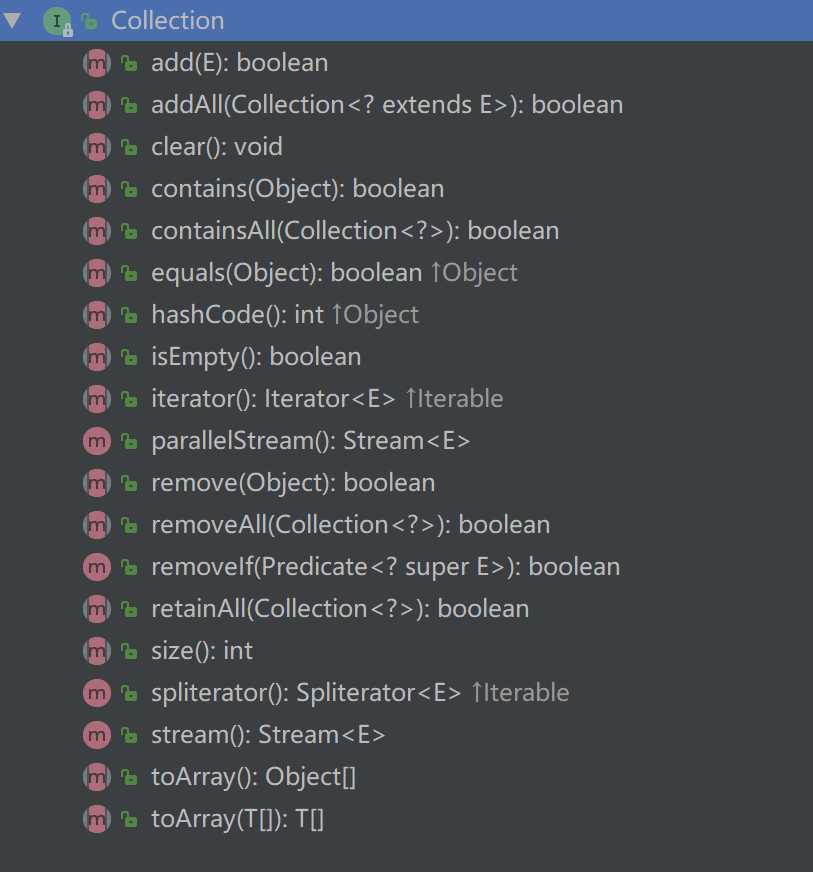
2. Collection
- Collection 接口是集合类的根接口,继承 Iterable 接口,Java 中没有提供这个接口的直接的实现类;
- 但是却让其被继承产生了两个接口,就是 List 和 Set;
- List:是一个有序的集合,可以包含重复的元素,提供了按索引访问的方式;
- Set:不能包含重复的元素;
- 提供了常用操作集合类的 API。
-
2.2、List 接口及实现类
1. List 接口
特性:
List 常用方法
// 增加元素的方法:
// 在列表的指定位置插入指定元素(可选操作)
void add(int index, E element) ;
// 将指定 collection 中的所有元素都插入到列表中的指定位置(可选操作)
boolean addAll (int index, Collection c);
// 获取元素的方法:
// 返回列表中指定位置的元素
Object get(int index);
// 返回列表中指定的 fromIndex(包括) 和 toIndex(不包括)之间的部分视图
// 从 fromIndex 开始,到 toIndex 结束,但不包括 toIndex 处的元素;注意索引,不要超出了size;
List<E> subList(int fromIndex, int toIndex);
// 查询元素的方法:
// 返回此列表中第一次出现的指定元素的索引;如果此列表不包含该元素,则返回 -1
int indexOf(Object o);
// 返回此列表中最后出现的指定元素的索引;如果列表不包含次元素,则返回 -1
int lastIndexOf(Object o);
// 删除元素的方法:
移除列表中指定位置的元素(可选操作);注意索引,不要超出size
E remove(int index);
// 改变元素的方法:
// 用指定元素替换列表中指定位置的元素(可选操作)
E set(int index, E element);
2. ArrayList && Vector
- 底层具体实现为数组,所以具有数组的一些特性:是一块连续的内存空间,支持按照下标随机访问,查找的时间复杂度低,增加和删除的时间复杂度较大。
- ArrayList 是线程不安全的,效率高。
- Vector 大部分方法被 synchronized 修饰,线程不安全,效率低。
3. LinkedList
- 底层实现为双向链表,所以具有链表的一些特性:不是一块连续的内存空间,查询效率低要一个一个去遍历,增加和删除效率高。
- 线程不安全。
2.3、 Set 接口及实现类
1. Set
特性:
- 无序:对应的实现类中有的不能保证读取和存入顺序一致,有的可以保证,有的按照自然顺序排序。
- 无索引,没有 get 方法。
- 不能存取重复值
- 底层为 Map,就是 Map 的 key。
2. HashSet
特性:
- 底层对应 HashMap,即哈希表。
- 完全的无序。
- 可以存 null。
- 整体效率快。
- 线程不安全。
3.LinkedHashSet
特性:
- 继承自 HashSet,底层结构是 LinkedHashMap,即 Hash表 + 链表。
- 底层更复杂,所以效率比 HashSet 低。
- 可以保证顺序。
- 可以存 null。
- 线程不安全。
4. TreeSet
特性:
- 底层对应 TreeMap,即红黑二叉树。
- 不能存 null。
- 元素保证自然顺序,没有遵守 hashCode 和 equals 协定,根据 CompareTo 方法来判断。
三、Map
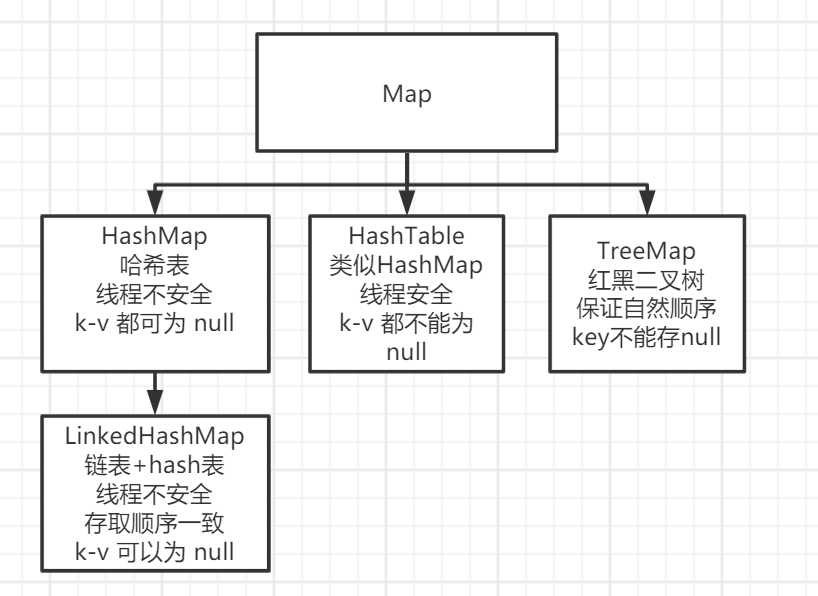
特性:
- 存储的数据是成对存在的。
- key 唯一,key 只能映射到一个 value 上,Set 包含的元素 就是 Map 里的 key。
- 有的实现类的 key 可以为 null,但是只能有一个 null,有的实现类不允许 key 为 null。
- 协定:hashcode && equals。
底层结构:
- 初试大小为 16 个,0.75 时扩容,扩容要重新计算哈希值。
- JDK1.8 之前:
- hash算法为 数组 + 链表;
- 先调用 hashCode 方法运算出数组的索引值,如果索引位无值则存储,有值就会发生哈希碰撞,此时用 equals 方法比较,如果 equals 方法相等就覆盖原有值,不相等以链表的形式存储并且后加的值放在链表头部(头插法)。
- 弊端:哈希碰撞后,如果链表过长,则调用 equals 方法次数就会很多,效率低,所以要尽量减少哈希碰撞;并且链表过长查找也会低下,链表的查找时间复杂度是 Q(n)。
- JDK1.8 之后
- hash算法为 数组 + 链表 + 红黑树;当链表的长度超过一定范围(8),总大小超过64时链表变为红黑树。
Map 的常用的方法:
// 删除:
// 从此 map 对象中 移除所有映射关系
void clear();
// 如果存在一个键的映射关系(key -- value),则将其从此映射中移除
// 如果没有该 key,并不会移除映射关系,返回一个null
// 如果有该 key, 移除这个 key, 并把 value 返回
// 返回值是 null 的话,那么该 key 之前并不一定不存在,可能 key 之前对应的 value 是 null
V remove(Object key);
// 查找:
boolean containsKey(Object key);
boolean containsValue(Object value);
// 获取:
V get(Object key);
// 判断:
boolean isEmpty();
// 添加:
V put(K key, V value);
Map 的遍历方式:
- Set keySet(); 把本 map 里的所有 key 全部拿出来装入 Set 集合中,作为返回值返回;
- Set<Map.Entry<K,V>> entrySet(); 返回此映射中包含的映射关系的 Set 视图;
3.1、HashMap && HashTable
特性:
- 底层: 哈希表实现。
- key 完全无序。
- HashMap 中 key 和 value 可以为 null,线程不安全,效率高。
- HashTable 中 key 和 value 不可以为 null,线程安全,效率低。
- 协定: hashcode && equals。
3.2、LinkedHashMap
- 底层: 哈希表 + 链表;
- 底层更加复杂,速度比父类慢。
- key 保证了 插入时顺序。
- key 和 value 可以为 null。
- 协定: hashcode equals 方法查重。
3.3、TreeMap
- 底层: 红黑二叉树。
- key 不可以为 null。
- value 可以为 null。
- 保证了 按照 key 的 自然顺序进行存储。
五、Java - 集合
标签:循环 堆内存 算法 开始 eset shm 容器 完全 set
原文地址:https://www.cnblogs.com/xiexiandong/p/12994930.html