标签:制作 导入 补充 目标 RKE monitor 重要 创建 医学图像
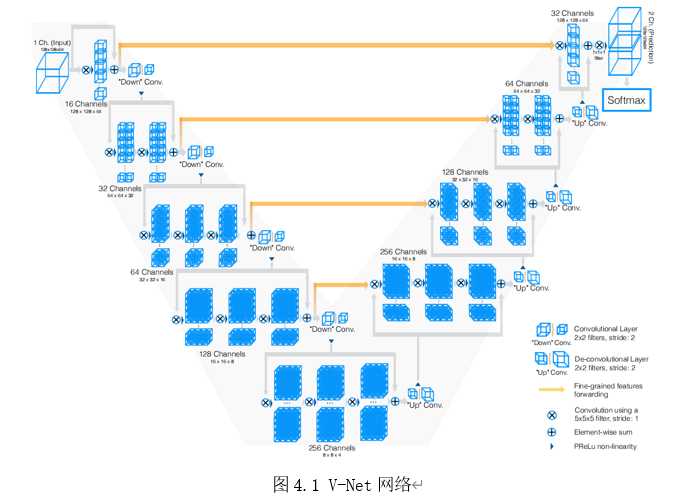
V-Net网络在编码层引入残差结构。残差结构中,除了正常的卷积操作,还将卷积前的输入直接短路连接到输出端,这样网络可以学习到一个残差函数。学习残差可以加速收敛。编码网络用5×5×5卷积来提取图像特征,用步长为2,尺寸为2×2×2的卷积来代替最大池化。由于将模型公式化为残差网络,所以当我们降低它们的分辨率时,用卷积来加倍特征图数量。整个网络的激活函数为PReLu。右侧解码部分利用解码网络提取的特征并恢复图像空间分辨率,最后输出3D分割。最后的卷积层使用1×1×1卷积,得到与输入相同尺寸的输出结果。然后通过softmax层激活,生成目标和背景的概率图。在每一级解码层之后,用反卷积恢复空间分辨率,后接5×5×5卷积,并减半特征图数量。与编码网络一样,解码端也学习残差函数,不断地反卷积,来恢复位置信息,并且通过skip-connection将左侧编码部分各个阶段提取的特征传递到解码部分,以获取更多的图像细节信息,提高预测的准确性。skip-connection在图4-1中由水平连接示意性地表示。通过这种方式,补充了下采样丢失的信息,提高分割精度,同时skip-connection结构的引入还可以减少网络收敛时间。V-Net同样是是一种全卷积网络结构,因此对于输入3D图像没有二维尺寸要求。
1 """ 2 本程序制作vnet数据集,同一dir中的11张切片作为一组输入 3 服务器存储空间有限,一个dir一个dir进行制作,然后训练 4 """ 5 import os 6 import cv2 as cv 7 import numpy as np 8 9 10 # 制作哪一个dir的数据 11 dir_num = 3 12 image_size = 400 13 depth = 11 14 15 16 train_png_path = "./data_dir_png/train" 17 label_png_path = "./data_dir_png/label" 18 train_64_input_path = "./vnet_" + str(depth) + "_1_input/train" 19 label_64_input_path = "./vnet_" + str(depth) + "_1_input/label" 20 if not os.path.isdir(train_64_input_path): 21 os.makedirs(train_64_input_path) 22 if not os.path.isdir(label_64_input_path): 23 os.makedirs(label_64_input_path) 24 25 26 train_dirs = os.listdir(train_png_path) 27 label_dirs = os.listdir(label_png_path) 28 train_dirs.sort(key=lambda x: int(x)) 29 label_dirs.sort(key=lambda x: int(x)) 30 # 选择需要制作数据的dir 31 dir_name = train_dirs[dir_num] 32 # train和label的dir地址 33 train_dir_path = os.path.join(train_png_path, dir_name) 34 label_dir_path = os.path.join(label_png_path, dir_name) 35 36 train_pngs = os.listdir(train_dir_path) 37 train_pngs.sort(key=lambda x: int(x.split(".")[0])) 38 label_pngs = os.listdir(label_dir_path) 39 label_pngs.sort(key=lambda x: int(x.split(".")[0])) 40 41 for i in range(len(train_pngs)): 42 train_npy = np.ndarray((depth, image_size, image_size, 1), dtype=np.uint8) 43 label_npy = np.ndarray((image_size, image_size, 1), dtype=np.uint8) 44 if (i + depth-1) < len(train_pngs): 45 label_img_path = os.path.join(label_dir_path, label_pngs[i+5]) 46 label_img = cv.imread(label_img_path, 0) 47 48 # cv.imshow("label", label_img) 49 50 label_img = np.reshape(label_img, (image_size, image_size, 1)) 51 label_npy = label_img 52 for j in range(depth): 53 index = i + j 54 train_img_path = os.path.join(train_dir_path, train_pngs[index]) 55 train_img = cv.imread(train_img_path, 0) 56 57 # cv.imshow("train", train_img) 58 59 train_img = np.reshape(train_img, (image_size, image_size, 1)) 60 train_npy[j] = train_img 61 62 # cv.waitKey(0) 63 # cv.destroyAllWindows() 64 65 train_input_path = os.path.join(train_64_input_path, str(dir_num)) 66 label_input_path = os.path.join(label_64_input_path, str(dir_num)) 67 if not os.path.isdir(train_input_path): 68 os.makedirs(train_input_path) 69 if not os.path.isdir(label_input_path): 70 os.makedirs(label_input_path) 71 print(train_npy.shape) 72 print(label_npy.shape) 73 np.save(train_input_path + "/" + str(i) + ".npy", train_npy) 74 np.save(label_input_path + "/" + str(i) + ".npy", label_npy)
1 import keras 2 from keras.models import * 3 from keras.layers import Input, Conv3D, Deconvolution3D, Dropout, Concatenate, UpSampling3D 4 from keras.optimizers import * 5 from keras import layers 6 from keras import backend as K 7 8 from keras.callbacks import ModelCheckpoint 9 from V_Net.vnet_3_3.fit_generator import get_path_list, get_train_batch 10 import matplotlib.pyplot as plt 11 12 train_batch_size = 1 13 epoch = 1 14 image_size = 512 15 depth = 3 16 17 data_train_path = "./data/train" 18 data_label_path = "./data/label" 19 train_path_list, label_path_list, count = get_path_list(data_train_path, data_label_path) 20 21 22 # 写一个LossHistory类,保存loss和acc 23 class LossHistory(keras.callbacks.Callback): 24 def on_train_begin(self, logs={}): 25 self.losses = {‘batch‘: [], ‘epoch‘: []} 26 self.accuracy = {‘batch‘: [], ‘epoch‘: []} 27 self.val_loss = {‘batch‘: [], ‘epoch‘: []} 28 self.val_acc = {‘batch‘: [], ‘epoch‘: []} 29 30 def on_batch_end(self, batch, logs={}): 31 self.losses[‘batch‘].append(logs.get(‘loss‘)) 32 self.accuracy[‘batch‘].append(logs.get(‘dice_coef‘)) 33 self.val_loss[‘batch‘].append(logs.get(‘val_loss‘)) 34 self.val_acc[‘batch‘].append(logs.get(‘val_acc‘)) 35 36 def on_epoch_end(self, batch, logs={}): 37 self.losses[‘epoch‘].append(logs.get(‘loss‘)) 38 self.accuracy[‘epoch‘].append(logs.get(‘dice_coef‘)) 39 self.val_loss[‘epoch‘].append(logs.get(‘val_loss‘)) 40 self.val_acc[‘epoch‘].append(logs.get(‘val_acc‘)) 41 42 def loss_plot(self, loss_type): 43 iters = range(len(self.losses[loss_type])) 44 plt.figure() 45 # acc 46 plt.plot(iters, self.accuracy[loss_type], ‘r‘, label=‘train dice‘) 47 # loss 48 plt.plot(iters, self.losses[loss_type], ‘g‘, label=‘train loss‘) 49 if loss_type == ‘epoch‘: 50 # val_acc 51 plt.plot(iters, self.val_acc[loss_type], ‘b‘, label=‘val acc‘) 52 # val_loss 53 plt.plot(iters, self.val_loss[loss_type], ‘k‘, label=‘val loss‘) 54 plt.grid(True) 55 plt.xlabel(loss_type) 56 plt.ylabel(‘dice-loss‘) 57 plt.legend(loc="best") 58 plt.show() 59 60 61 def dice_coef(y_true, y_pred): 62 smooth = 1. 63 y_true_f = K.flatten(y_true) 64 y_pred_f = K.flatten(y_pred) 65 intersection = K.sum(y_true_f * y_pred_f) 66 return (2. * intersection + smooth) / (K.sum(y_true_f * y_true_f) + K.sum(y_pred_f * y_pred_f) + smooth) 67 68 69 def dice_coef_loss(y_true, y_pred): 70 return 1. - dice_coef(y_true, y_pred) 71 72 73 def mycrossentropy(y_true, y_pred, e=0.1): 74 nb_classes = 10 75 loss1 = K.categorical_crossentropy(y_true, y_pred) 76 loss2 = K.categorical_crossentropy(K.ones_like(y_pred) / nb_classes, y_pred) 77 return (1 - e) * loss1 + e * loss2 78 79 80 class myVnet(object): 81 def __init__(self, img_depth=depth, img_rows=image_size, img_cols=image_size, img_channel=1, drop=0.5): 82 self.img_depth = img_depth 83 self.img_rows = img_rows 84 self.img_cols = img_cols 85 self.img_channel = img_channel 86 self.drop = drop 87 88 def BN_operation(self, input): 89 output = keras.layers.normalization.BatchNormalization(axis=-1, momentum=0.99, epsilon=0.001, center=True, 90 scale=True, 91 beta_initializer=‘zeros‘, gamma_initializer=‘ones‘, 92 moving_mean_initializer=‘zeros‘, 93 moving_variance_initializer=‘ones‘, 94 beta_regularizer=None, 95 gamma_regularizer=None, beta_constraint=None, 96 gamma_constraint=None)(input) 97 return output 98 99 def encode_layer(self, kernel_num, kernel_size, input): 100 # 第一次卷积 101 conv1 = Conv3D(kernel_num, kernel_size, activation=‘relu‘, padding=‘same‘, 102 kernel_initializer=‘he_normal‘)(input) 103 conv1 = self.BN_operation(conv1) 104 conv1 = Dropout(self.drop)(conv1) 105 # 第二次卷积 106 conv2 = Conv3D(kernel_num, kernel_size, activation=‘relu‘, padding=‘same‘, 107 kernel_initializer=‘he_normal‘)(conv1) 108 conv2 = self.BN_operation(conv2) 109 conv2 = Dropout(self.drop)(conv2) 110 # 残差 111 res = layers.add([conv1, conv2]) 112 return res 113 114 def down_operation(self, kernel_num, kernel_size, input): 115 down = Conv3D(kernel_num, kernel_size, strides=[1, 2, 2], activation=‘relu‘, padding=‘same‘, 116 kernel_initializer=‘he_normal‘)(input) 117 down = self.BN_operation(down) 118 down = Dropout(self.drop)(down) 119 return down 120 121 def decode_layer(self, kernel_num, kernel_size, input, code_layer): 122 # deconv = Deconvolution3D(kernel_num, kernel_size, strides=(1, 2, 2), activation=‘relu‘, padding=‘same‘, 123 # kernel_initializer=‘he_normal‘)(input) 124 deconv = Conv3D(kernel_num, kernel_size, activation=‘relu‘, padding=‘same‘, kernel_initializer=‘he_normal‘)( 125 UpSampling3D(size=(1, 2, 2))(input)) 126 127 merge = Concatenate(axis=4)([deconv, code_layer]) 128 conv = Conv3D(kernel_num, kernel_size, activation=‘relu‘, padding=‘same‘, 129 kernel_initializer=‘he_normal‘)(merge) 130 conv = self.BN_operation(conv) 131 conv = Dropout(self.drop)(conv) 132 133 res = layers.add([deconv, conv]) 134 return res 135 136 # V-Net网络 137 def get_vnet(self): 138 inputs = Input((self.img_depth, self.img_rows, self.img_cols, self.img_channel)) 139 140 # 卷积层1 141 conv1 = self.encode_layer(16, [depth, 3, 3], inputs) 142 # 下采样1 143 down1 = self.down_operation(32, [depth, 3, 3], conv1) 144 145 # 卷积层2 146 conv2 = self.encode_layer(32, [depth, 3, 3], down1) 147 # 下采样2 148 down2 = self.down_operation(64, [depth, 3, 3], conv2) 149 150 # 卷积层3 151 conv3 = self.encode_layer(64, [depth, 3, 3], down2) 152 # 下采样3 153 down3 = self.down_operation(128, [depth, 3, 3], conv3) 154 155 # 卷积层4 156 conv4 = self.encode_layer(128, [depth, 3, 3], down3) 157 # 下采样4 158 down4 = self.down_operation(256, [depth, 3, 3], conv4) 159 160 # 卷积层5 161 conv5 = self.encode_layer(256, [depth, 3, 3], down4) 162 163 # 反卷积6 164 deconv6 = self.decode_layer(128, [depth, 3, 3], conv5, conv4) 165 166 # 反卷积7 167 deconv7 = self.decode_layer(64, [depth, 3, 3], deconv6, conv3) 168 169 # 反卷积8 170 deconv8 = self.decode_layer(32, [depth, 3, 3], deconv7, conv2) 171 172 # 反卷积9 173 deconv9 = self.decode_layer(16, [depth, 3, 3], deconv8, conv1) 174 conv9 = Conv3D(8, [depth, 3, 3], activation=‘relu‘, padding=‘same‘, 175 kernel_initializer=‘he_normal‘)(deconv9) 176 conv9 = Conv3D(4, [depth, 3, 3], activation=‘relu‘, padding=‘same‘, 177 kernel_initializer=‘he_normal‘)(conv9) 178 conv9 = Conv3D(2, [depth, 3, 3], activation=‘relu‘, padding=‘same‘, 179 kernel_initializer=‘he_normal‘)(conv9) 180 181 conv10 = Conv3D(1, [1, 1, 1], activation=‘sigmoid‘)(conv9) 182 183 model = Model(inputs=inputs, outputs=conv10) 184 185 # 在这里可以自定义损失函数loss和准确率函数accuracy 186 # model.compile(optimizer=Adam(lr=1e-4), loss=‘binary_crossentropy‘, metrics=[‘accuracy‘]) 187 model.compile(optimizer=Adam(lr=1e-4), loss=‘binary_crossentropy‘, metrics=[‘accuracy‘, 188 dice_coef]) 189 print(‘model compile‘) 190 return model 191 192 def train(self): 193 print("loading data") 194 print("loading data done") 195 196 model = self.get_vnet() 197 print("got vnet") 198 199 # 保存的是模型和权重 200 model_checkpoint = ModelCheckpoint(‘../model/vnet_liver.hdf5‘, monitor=‘loss‘, 201 verbose=1, save_best_only=True) 202 print(‘Fitting model...‘) 203 204 # 创建一个实例history 205 history = LossHistory() 206 # 在callbacks中加入history最后才能绘制收敛曲线 207 model.fit_generator( 208 generator=get_train_batch(train_path_list, label_path_list, train_batch_size, depth, image_size, image_size), 209 epochs=epoch, verbose=1, 210 steps_per_epoch=count//train_batch_size, 211 callbacks=[model_checkpoint, history], 212 workers=1) 213 # 绘制acc-loss曲线 214 history.loss_plot(‘batch‘) 215 plt.savefig(‘vnet_liver_dice_loss_curve.png‘) 216 217 218 if __name__ == ‘__main__‘: 219 myvnet = myVnet() 220 myvnet.train()
1 import numpy as np 2 import cv2 as cv 3 import os 4 5 data_train_path = "../../Vnet_tf/V_Net_data/train" 6 data_label_path = "../../Vnet_tf/V_Net_data/label" 7 8 9 def get_path_list(data_train_path, data_label_path): 10 dirs = os.listdir(data_train_path) 11 dirs.sort(key=lambda x: int(x)) 12 count = 0 13 for dir in dirs: 14 dir_path = os.path.join(data_train_path, dir) 15 count += len(os.listdir(dir_path)) 16 print("共有{}组训练数据".format(count)) 17 18 train_path_list = [] 19 label_path_list = [] 20 for dir in dirs: 21 train_dir_path = os.path.join(data_train_path, dir) 22 label_dir_path = os.path.join(data_label_path, dir) 23 trains = os.listdir(train_dir_path) 24 labels = os.listdir(label_dir_path) 25 trains.sort(key=lambda x: int(x.split(".")[0])) 26 labels.sort(key=lambda x: int(x.split(".")[0])) 27 for name in trains: 28 train_path = os.path.join(train_dir_path, name) 29 label_path = os.path.join(label_dir_path, name) 30 31 train_path_list.append(train_path) 32 label_path_list.append(label_path) 33 34 return train_path_list, label_path_list, count 35 36 37 def get_train_img(paths, img_d, img_rows, img_cols): 38 """ 39 参数: 40 paths:要读取的图片路径列表 41 img_rows:图片行 42 img_cols:图片列 43 color_type:图片颜色通道 44 返回: 45 imgs: 图片数组 46 """ 47 # Load as grayscale 48 datas = [] 49 for path in paths: 50 data = np.load(path) 51 # Reduce size 52 resized = np.reshape(data, (img_d, img_rows, img_cols, 1)) 53 resized = resized.astype(‘float32‘) 54 resized /= 255 55 mean = resized.mean(axis=0) 56 resized -= mean 57 datas.append(resized) 58 datas = np.array(datas) 59 return datas 60 61 62 def get_label_img(paths, img_d, img_rows, img_cols): 63 """ 64 参数: 65 paths:要读取的图片路径列表 66 img_rows:图片行 67 img_cols:图片列 68 color_type:图片颜色通道 69 返回: 70 imgs: 图片数组 71 """ 72 # Load as grayscale 73 datas = [] 74 for path in paths: 75 data = np.load(path) 76 # Reduce size 77 resized = np.reshape(data, (img_d, img_cols, img_rows, 1)) 78 resized = resized.astype(‘float32‘) 79 resized /= 255 80 datas.append(resized) 81 datas = np.array(datas) 82 return datas 83 84 85 def get_train_batch(train, label, batch_size, img_d, img_w, img_h): 86 """ 87 参数: 88 X_train:所有图片路径列表 89 y_train: 所有图片对应的标签列表 90 batch_size:批次 91 img_w:图片宽 92 img_h:图片高 93 color_type:图片类型 94 is_argumentation:是否需要数据增强 95 返回: 96 一个generator,x: 获取的批次图片 y: 获取的图片对应的标签 97 """ 98 while 1: 99 for i in range(0, len(train), batch_size): 100 x = get_train_img(train[i:i+batch_size], img_d, img_w, img_h) 101 y = get_label_img(label[i:i+batch_size], img_d, img_w, img_h) 102 # 最重要的就是这个yield,它代表返回,返回以后循环还是会继续,然后再返回。就比如有一个机器一直在作累加运算,但是会把每次累加中间结果告诉你一样,直到把所有数加完 103 yield(np.array(x), np.array(y)) 104 105 106 if __name__ == "__main__": 107 train_path_list, label_path_list, count = get_path_list(data_train_path, data_label_path) 108 print(train_path_list)
标签:制作 导入 补充 目标 RKE monitor 重要 创建 医学图像
原文地址:https://www.cnblogs.com/jinyiyexingzc/p/12996396.html