标签:数据引擎 pes match 重要 常用 image 用处 customer 列表
并非所有的数据库引擎都支持全文本搜索
MySQL 支持几种基本的数据库引擎,最常用的两种是MyISAM 和 InnoDB,MyISAM 支持全文本搜索,而InnoDB 不支持
所以要使用全文本搜索的时候要注意,你的表引用的是不是MyISAM
之前了解过两个like 和 regxp

like关键字利用通配符匹配文本(或部分文本),可以查找包含特殊值或部分值的行(不管这些值位于列内的什么位置)
regxp 可以编写查找所需行的非常复杂的匹配模式。
那他们有哪些限制来
1、通配符和正则表达式匹配,通常要求MySQL 尝试匹配表中所有行,而这些搜索极少使用到表索引。因此,由于被搜索行数不断增加,这些搜索可能非常耗时。
2、使用通配符和正则表达式匹配很难明确的控制匹配什么和不匹配什么,
3、基于通配符和正则虽然可以提供非常灵活的搜索,但他们都不能提供一种智能化的选择结果的方法。
因此,推出了本文重点全文本搜索,可以解决以上以及更多的限制
使用全文本搜索,MySQL不需要分别查看每个行,不需要分别分析和处理每个词,MySQL创建指定列中各词的一个索引,可以针对这些词搜索,快速有效的决定哪些词匹配(哪些行包括他们),哪些词不匹配,以及他们的匹配频率等等。
简单使用
注意:
1、为了进行全文本搜索,必须索引被搜索的列,而且要随着数据的改变不断的重新索引。但是在对表列进行适当设计后,MySQL自动进行所有的索引和重新索引。
2、在索引后 select可以与 match() 和Against() 一起使用以实际执行搜索。
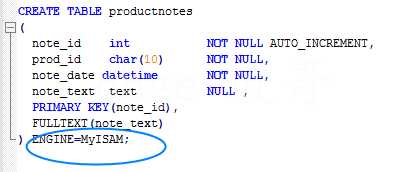
3、一般在创建表的时候启用全文本搜索,在创建表的时候增加 FULLTEXT(列名),并指定使用的引擎 ENGINE=MyISAM;
如下:
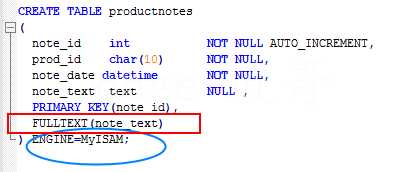
上述:mysql 根据 子句 fulltesxt(note_text) 的指示对列名note_text 进行索引,
注意
1、fulltesxt 既可以指定单列也可以指定多列,
2、定义后MySQL会自动维护该索引,在增加、更新或删除行时,索引随之更新。
3、可以在创建表时指定fulltest, 也可以稍后指定,不过,所有已有数据必须立即索引
4、不要在导入数据时使用索引,建议先导数据在修改表启动索引,这样有助于更快的导入数据(这样使索引数据的总时间小于在导入每行时分别进行索引所需要的总时间)。
进行全文本搜索的两个函数
match() : 指定被搜索的列,
against() : 指定要使用的搜索表达式
-- 检索单个列 note_text ,将字段note_text中含有rabbit的行检索出来
select note_text from productnotes where match(note_text) against(‘rabbit‘);

select 语句检索单个列onte_text 由于where 子句,一个全文本搜索被执行,match(note_text) 指示mysql 针对列名为note_text 的进行搜索,against(‘rabbit‘) 指定在该列中搜索文本中含有 rabbit 的行,包含的行就返回
注意:
1、传递给match() 的值必须与fulltext() 定义中的相同,如果指定多个列,则必须列出他们,而且次序也要相同
2、全文本搜索不区分大小写,除非使用 binary 方式
使用 like 和 regexp 的方式实现
select note_text from productnotes where note_text like ‘%rabbit%‘; select note_text from productnotes where note_text regexp ‘rabbit‘;
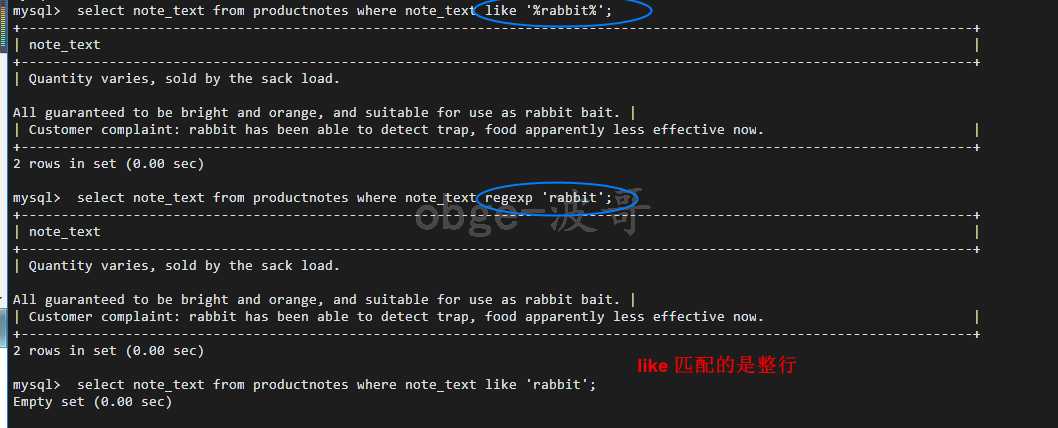
发现这两种方式检索出来的两行,与使用全文本搜索检索出来的 顺序(次序)不同,而且都没有使用order by
为啥来
因为使用全文本搜索返回的数据,以文本匹配的良好程度排序匹配,虽然两行都有rabbit 这个词,但是一个位置在第3个词,另一个位置在第20个词,所以全文本搜索根据具有高等级的行先返回(这也可能是真正想要的)。而like 没有指定也不会以特别有用的顺序返回数据。
如何计算他们的程度的来
select note_text,match(note_text) against(‘rabbit‘) as rank from productnotes;
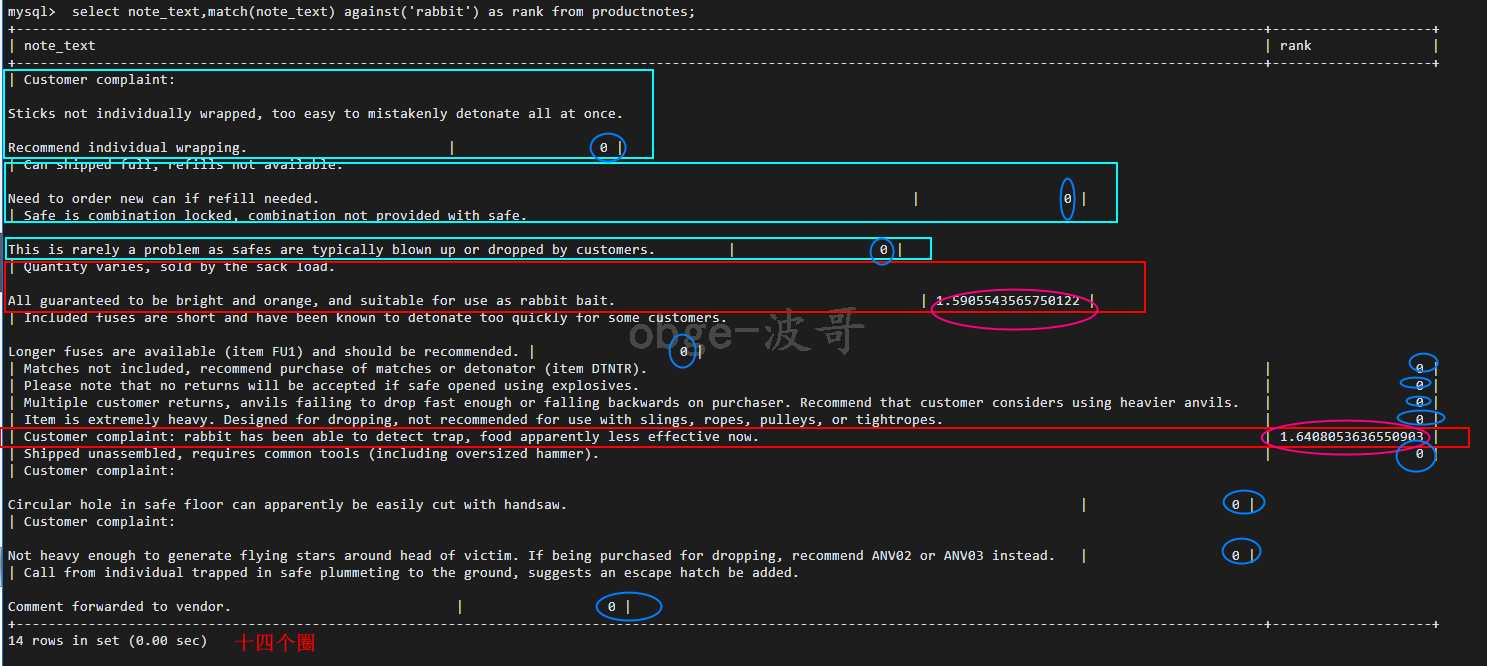
match () 和 against() 用来建立一个计算列(别名rank),将此列包含全文本搜索计算出等级值
等级计算方式:mysql 根据行中词的数目、唯一词的数目、整个索引中词的总数以及包含该词的行的数目计算出来。其中不含有的为 0 ,包含的都有一个等级值,等级值越高检索出来后的排列越靠前。如果指定多个搜索项,则包含多数匹配词的那些行将比包含较少词(或仅有一个匹配)的那些行等级高。
全文本搜索提供了like 不具有的功能,而且由于数据是索引的,全文本搜索还较快
2、查询扩展(WITH QUERY EXPANSION):用来设法放宽所返回的全文本搜索结果的范围。
就是首先将根据关键词全文本搜索找出来行,然后再根据返回出来的行,从中选择有用的词,在和关键词一块作为查询条件进行搜索。
查询扩展只适用于mysql 4.1.1 或更高级的版本
使用查询扩展时,mysql 对数据和索引进行两遍扫描来完成搜索,找出可能相关的结果,即使他们并不精确的包含所查找的词。
1、首先,进行一个基本的全文本搜索,找出与搜索条件匹配的所有行
2、然后,mysql 检查这些匹配行并选择所有有用的词(根据关键词检索出来的那个行从中选择有用的词)
3、最后,MySQL再次进行全文本搜索,这次不仅使用原来的条件,还要使用所有有用的词
-- 启用查询扩展 WITH QUERY EXPANSION select note_text from productnotes where match(note_text) against(‘anvils‘ WITH QUERY EXPANSION);
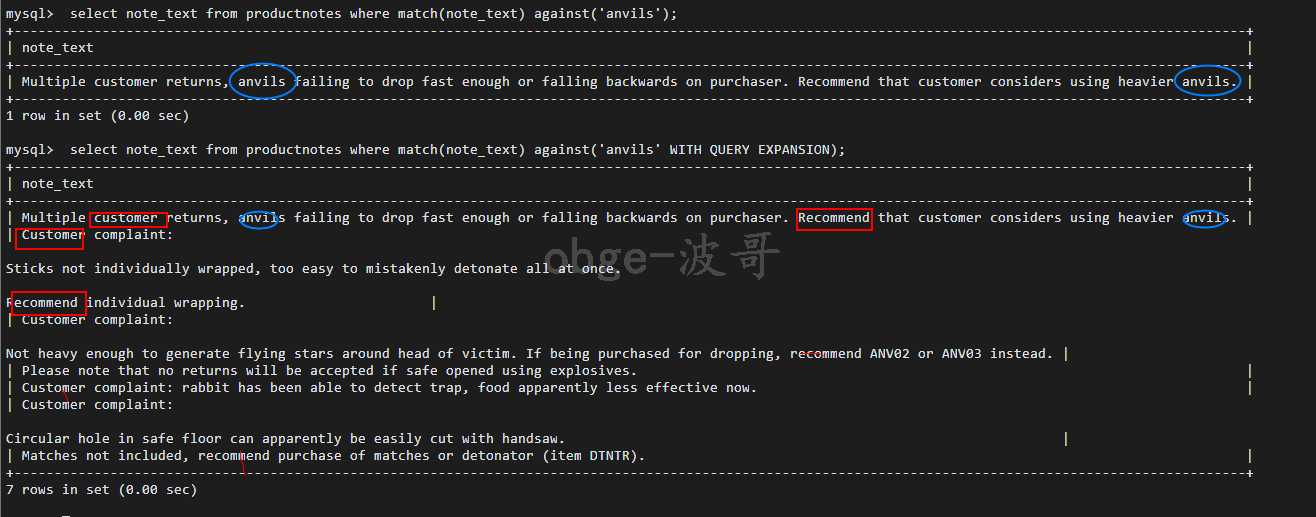

从上述可以看出,第一行有 anvils (铁砧),剩下的6行都没有,第二行根据 第一行中的两个有特点的词(customer(顾客)和 Recommend(推荐)),在进行查找,为啥选customer作为检索的词可能是在此行中出现的较多,还是个主语,了解就行
使用查询扩展检索出来的行更多,表中的行越多使用查询扩展返回的结果越好 ,因为更多的选择意味着更有机会把你快要忘记的那个找到。
3、布尔文本搜索(IN BOOLEAN MODE)
MySQL支持全文本搜索的另一种形式,布尔方式(boolean mode)
注意:
1、布尔方式即使没有定义fulltext 索引,也可以使用,但是它是一种非常缓慢的操作(其性能将随着数据i量的增加而降低)
2、要匹配的词
3、要排斥的词(如果某行包含这个词,则不返回,即使它包含其他指定的词)
4、排列提示(指定某些词比其他词更重要,更重要的词等级更高)
5、表达式分组
6、另外一些内容
-- 简单使用 select note_text from productnotes where match(note_text) against (‘heavy‘ in boolean mode);

另一种用法,指定排斥的词
-- 匹配包含 但不包含 任意以rope 开始的词的行 select note_text from productnotes where match(note_text) against (‘heavy -rope*‘ in boolean mode);
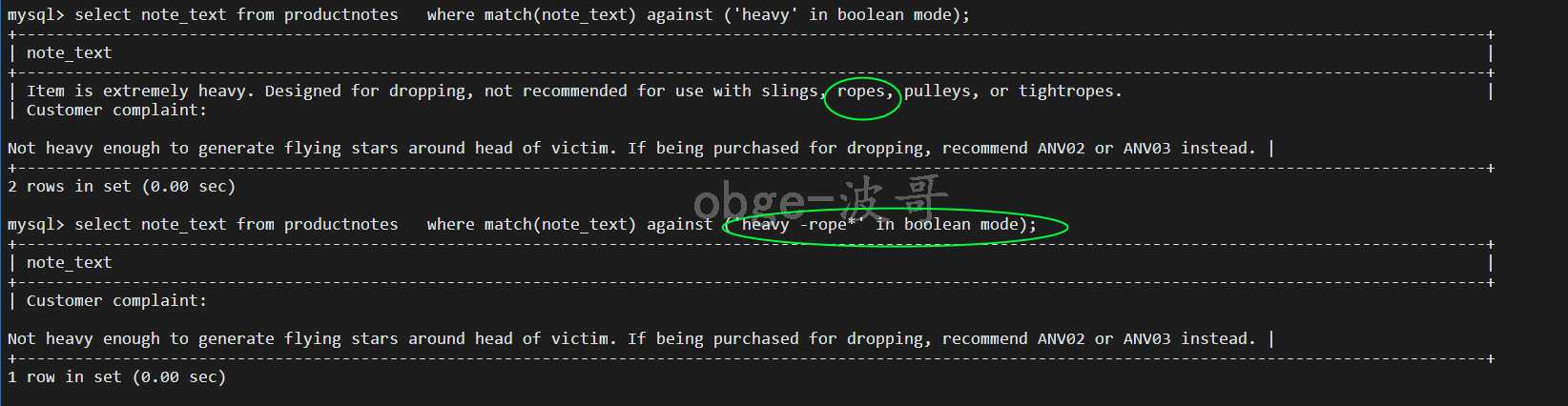
如果数据的的版本是 mysql 4.x 上面可能不反回任何行,其不支持 * ,要改为 -ropes 意思变成 并排除含有 ropes 的行
上述的 - 和 * 就是全文本布尔操作符
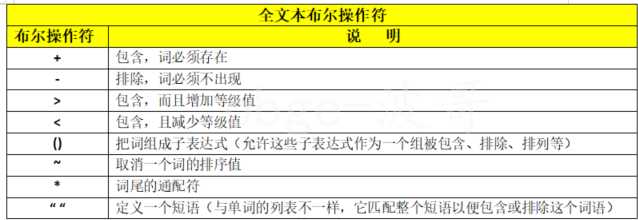
小小使用
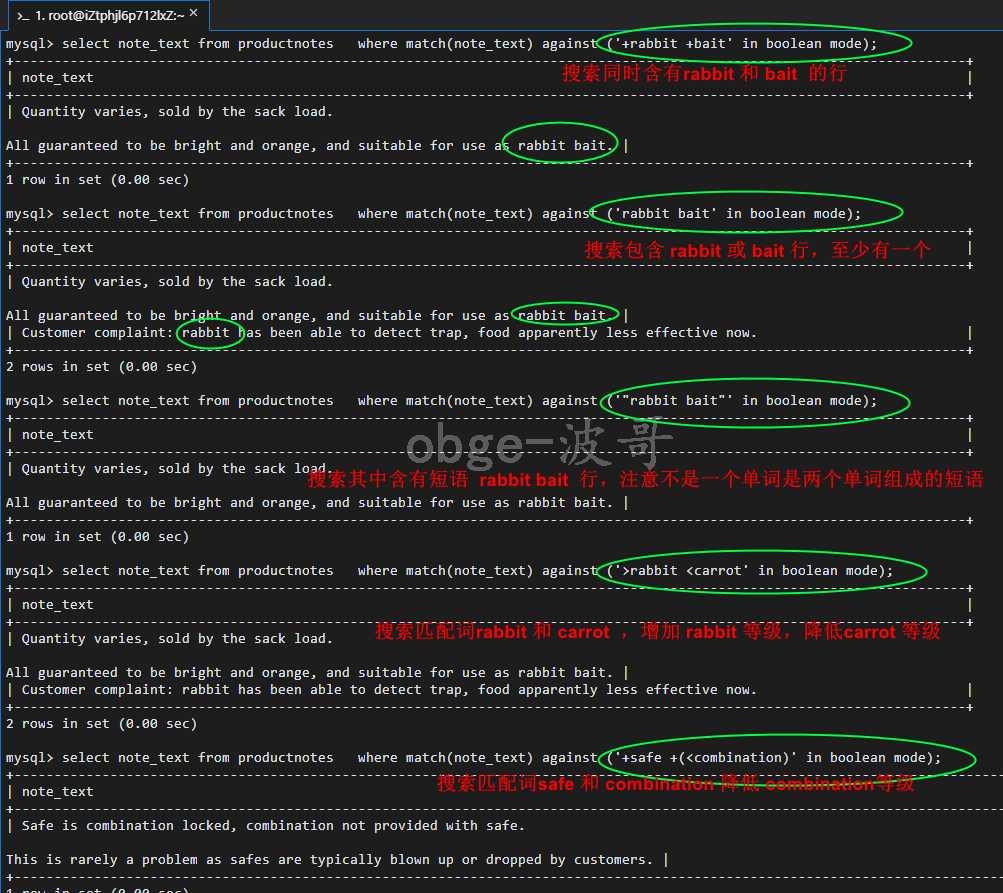
注意:在布尔方式中不按照等级值降序排列返回行
全文本搜索的使用说明
1、在索引全文本数据时,短词被忽略且从索引中排除。短词定义为那些具有3个或3个以下字符的词(如果需要,这个数目可以改)
2、MySQL带有一个内建的非用词(stopword)列表,这些词在索引全文本数据时总是被忽略。如果需要,可以覆盖这个列表
3、许多词出现的频率很高,搜索他们没有用处(返回太多的结果),因此,MySQL规定了一条50%规则,如果一个词出现50%以上的行中。则将他作为一个非用词忽略。50%规则不用于 IN BOOLEAN MODE
4、如果表中的行数少于3行,则全文本搜索不返回结果(因为每个词或者不出现,或者至少出现在50%行中)
5、忽略词中的单引号,列如: don‘t 索引为dont
6、不具有词分隔符(包括日语和汉语)的语言不能恰当地返回全文本搜索结果
7、仅在myisam 数据引擎中支持全文本搜索
8、邻近搜索是许多全文本搜索支持的一个特定,它能搜索相邻的词(在相同的句子中,相同段落中或者在特定数目的词的部分中等等),但是MySQL全文本搜索现在不支持邻近操作符
9、MySQL使用 match() 和 against() 函数进行全文本搜索
10、查询扩展(WITH QUERY EXPANSION)
11、布尔文本搜索(IN BOOLEAN MODE)
MySQL ------ 全文本搜索( match和Against),以及查询扩展和 布尔方式(十七)
标签:数据引擎 pes match 重要 常用 image 用处 customer 列表
原文地址:https://www.cnblogs.com/obge/p/13028569.html