标签:hide 快速 opp lang exce proxy dso 情况下 nod
Spring Data JPA 是 Spring 基于 ORM 框架、JPA 规范的基础上封装的一套JPA应用框架,可使开发者用极简的代码即可实现对数据库的访问和操作。它提供了包括增删改查等在内的常用功能,且易于扩展!学习并使用 Spring Data JPA 可以极大提高开发效率!
Spring Data JPA 让我们解脱了DAO层的操作,基本上所有CRUD都可以依赖于它来实现,在实际的工作工程中,推荐使用Spring Data JPA + ORM(如:hibernate)完成操作,这样在切换不同的ORM框架时提供了极大的方便,同时也使数据库层操作更加简单,方便解耦
我在接下面的文章中都对它们三者进行扩展及应用,以及三者的封装关系及调用关系,我下面也会以一张图说明,如果此时有对JPA还一窍不通的可以参考我之前的一篇关于JPA文章的介绍
关系:其实看三者框架中,JPA只是一种规范,内部都是由接口和抽象类构建的;hibernate它是我们最初使用的一套由ORM思想构建的成熟框架,但是这个框架内部又实现了一套JPA的规范(实现了JPA规范定义的接口),所有也可以称hibernate为JPA的一种实现方式我们使用JPA的API编程,意味着站在更高的角度上看待问题(面向接口编程);Spring Data JPA它是Spring家族提供的,对JPA规范有一套更高级的封装,是在JPA规范下专门用来进行数据持久化的解决方案。
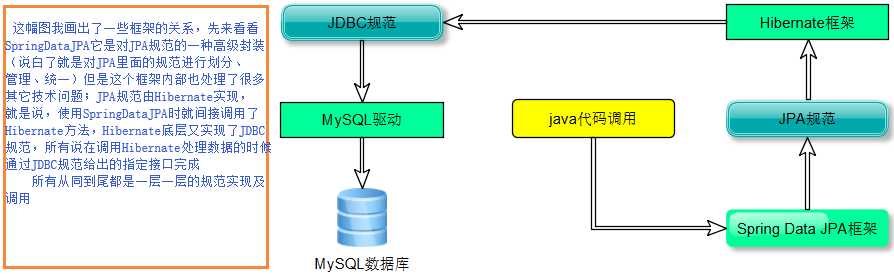
其实规范是死的,但是实现厂商是有很多的,这里我对hibernate的实现商介绍,如其它的实现厂商大家可以自行去理解,因为规范在这,实现类可以更好别的,面向接口编程。

-- 删除库
-- drop database demo_jpa;
-- 创建库
create database if not exists demo_jpa charset gbk collate gbk_chinese_ci;
-- 使用库
use demo_jpa;
-- 创建表
create table if not exists student(
sid int primary key auto_increment, -- 主键id
sname varchar(10) not null, -- 姓名
sage tinyint unsigned default 22, -- 年龄
smoney decimal(6,1), -- 零花钱
saddress varchar(20) -- 住址
)charset gbk collate gbk_chinese_ci;
insert into student values
(1,"蚂蚁小哥",23,8888.8,"安徽大别山"),
(2,"王二麻",22,7777.8,"安徽大别山"),
(3,"李小二",23,6666.8,"安徽大别山"),
(4,"霍元甲",23,5555.8,null),
(5,"叶问",22,4444.8,"安徽大别山"),
(6,"李连杰",23,3333.8,"安徽大别山"),
(7,"马克思",20,2222.8,"安徽大别山");
<dependencies> <!--单元测试坐标 4.12为最稳定--> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> <!--Spring核心坐标 注:导入此坐标也同时依赖导入了一些其它jar包--> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-context</artifactId> <version>5.2.6.RELEASE</version> </dependency> <!--Spring对事务管理坐标--> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-tx</artifactId> <version>5.2.6.RELEASE</version> </dependency> <!--Spring整合ORM框架的必须坐标 如工厂/事务等交由Spring管理--> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-orm</artifactId> <version>5.2.6.RELEASE</version> </dependency> <!--Spring单元测试坐标--> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-test</artifactId> <version>5.2.6.RELEASE</version> </dependency> <!--Spring Data JPA 核心坐标--> <dependency> <groupId>org.springframework.data</groupId> <artifactId>spring-data-jpa</artifactId> <version>1.10.4.RELEASE</version> </dependency> <!--导入AOP切入点表达式解析包--> <dependency> <groupId>org.aspectj</groupId> <artifactId>aspectjweaver</artifactId> <version>1.9.5</version> </dependency> <!--Hibernate核心坐标--> <dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-core</artifactId> <version>5.4.10.Final</version> </dependency> <!--hibernate对持久层的操作坐标--> <dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-entitymanager</artifactId> <version>5.4.10.Final</version> </dependency> <!--这下面的2个el坐标是使用Spring data jpa 必须导入的,不导入则报el异常--> <dependency> <groupId>javax.el</groupId> <artifactId>javax.el-api</artifactId> <version>2.2.4</version> </dependency> <dependency> <groupId>org.glassfish.web</groupId> <artifactId>javax.el</artifactId> <version>2.2.4</version> </dependency> <!--C3P0连接池坐标--> <dependency> <groupId>c3p0</groupId> <artifactId>c3p0</artifactId> <version>0.9.1.2</version> </dependency> <!--MySQL驱动坐标--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.32</version> </dependency> <!--JAXB API是java EE 的API,因此在java SE 9.0 中不再包含这个 Jar 包。 java 9 中引入了模块的概念,默认情况下,Java SE中将不再包含java EE 的Jar包 而在 java 6/7 / 8 时关于这个API 都是捆绑在一起的 抛出:java.lang.ClassNotFoundException: javax.xml.bind.JAXBException异常加下面4个坐标 --> <dependency> <groupId>javax.xml.bind</groupId> <artifactId>jaxb-api</artifactId> <version>2.3.0</version> </dependency> <dependency> <groupId>com.sun.xml.bind</groupId> <artifactId>jaxb-impl</artifactId> <version>2.3.0</version> </dependency> <dependency> <groupId>com.sun.xml.bind</groupId> <artifactId>jaxb-core</artifactId> <version>2.3.0</version> </dependency> <dependency> <groupId>javax.activation</groupId> <artifactId>activation</artifactId> <version>1.1.1</version> </dependency> </dependencies>
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:aop="http://www.springframework.org/schema/aop" xmlns:context="http://www.springframework.org/schema/context" xmlns:tx="http://www.springframework.org/schema/tx" xmlns:jpa="http://www.springframework.org/schema/data/jpa" xmlns:task="http://www.springframework.org/schema/task" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx.xsd http://www.springframework.org/schema/data/jpa http://www.springframework.org/schema/data/jpa/spring-jpa.xsd"> <!--配置注解扫描--> <context:component-scan base-package="cn.xw"></context:component-scan> <!--配置C3P0连接池--> <bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource"> <property name="driverClass" value="com.mysql.jdbc.Driver"></property> <property name="jdbcUrl" value="jdbc:mysql://localhost:3306/demo_jpa"></property> <property name="user" value="root"></property> <property name="password" value="123"></property> </bean> <!--创建EntityManagerFactory交给Spring管理,让Spring生成EntityManager实体管理器操作JDBC--> <bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean"> <!--配置一个连接池,后期获取连接的Connection连接对象--> <property name="dataSource" ref="dataSource"></property> <!--配置要扫描的包,因为ORM操作是基于实体类的--> <property name="packagesToScan" value="cn.xw.domain"></property> <!--配置JPA的实现厂家 实现了JPA的一系列规范--> <property name="persistenceProvider"> <bean class="org.hibernate.jpa.HibernatePersistenceProvider"></bean> </property> <!--JPA供应商适配器 因为我上面使用的是hibernate,所有适配器也选择hibernate--> <property name="jpaVendorAdapter"> <bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter"> <!--指定当前操作的数据库类型 必须大写,底层是一个枚举类--> <property name="database" value="MYSQL"></property> <!--是否自动创建数据库表--> <property name="generateDdl" value="false"></property> <!--是否在运行的时候 在控制台打印操作的SQL语句--> <property name="showSql" value="true"></property> <!--指定数据库方言:支持的语法,如Oracle和Mysql语法略有不同 org.hibernate.dialect下面的类就是支持的语法--> <property name="databasePlatform" value="org.hibernate.dialect.MySQLDialect"></property> <!--设置是否准备事务休眠会话的底层JDBC连接,即是否将特定于事务的隔离级别和/或事务的只读标志应用于底层JDBC连接。--> <property name="prepareConnection" value="false"></property> </bean> </property> <!--JPA方言:高级特性 我下面配置了hibernate对JPA的高级特性 如一级/二级缓存等功能--> <property name="jpaDialect"> <bean class="org.springframework.orm.jpa.vendor.HibernateJpaDialect"></bean> </property> <!--注入JPA的配置信息 加载JPA的基本配置信息和JPA的实现方式(hibernate)的配置信息 hibernate.hbm2ddl.auto:自动创建数据库表 create:每次读取配置文件都会创建数据库表 update:有则不做操作,没有则创建数据库表 --> <property name="jpaProperties"> <props> <prop key="hibernate.hbm2ddl.auto">update</prop> </props> </property> </bean> <!--配置事务管理器 不同的事务管理器有不同的类 如我们当初使用这个事务管理器DataSourceTransactionManager--> <bean id="jpaTransactionManager" class="org.springframework.orm.jpa.JpaTransactionManager"> <!--把配置好的EntityManagerFactory对象交由Spring内部的事务管理器--> <property name="entityManagerFactory" ref="entityManagerFactory"></property> <!--因为entityManagerFactory内部设置数据库连接了 所有后面不用设置--> <!--<property name="dataSource" ref="dataSource"></property>--> </bean> <!--配置tx事务--> <tx:advice id="txAdvice" transaction-manager="jpaTransactionManager"> <tx:attributes> <tx:method name="save*" propagation="REQUIRED" read-only="false"/> <tx:method name="insert*" propagation="REQUIRED" read-only="false"/> <tx:method name="update*" propagation="REQUIRED" read-only="false"/> <tx:method name="delete*" propagation="REQUIRED" read-only="false"/> <tx:method name="get*" propagation="SUPPORTS" read-only="true"/> <tx:method name="find*" propagation="SUPPORTS" read-only="true"/> <tx:method name="*" propagation="SUPPORTS" read-only="true"/> <!--如果命名规范直接使用下面2行控制事务--> <!--<tx:method name="find*" propagation="SUPPORTS" read-only="true"/>--> <!--<tx:method name="*" propagation="REQUIRED" read-only="false"/>--> </tx:attributes> </tx:advice> <!--配置AOP切面--> <aop:config> <!--在日常业务中配置事务处理的都是Service层,因为这里是案例讲解,所有我直接在测试类进行 所有我把事务配置这,也方便后期拷贝配置到真项目中--> <aop:pointcut id="pt1" expression="execution(* cn.xw.service.impl.*.*(..))"/> <aop:advisor advice-ref="txAdvice" pointcut-ref="pt1"></aop:advisor> </aop:config> <!--整合SpringDataJPA--> <!--base-package:指定持久层接口 entity-manager-factory-ref:引用其实体管理器工厂 transaction-manager-ref:引用事务 --> <jpa:repositories base-package="cn.xw.dao" entity-manager-factory-ref="entityManagerFactory" transaction-manager-ref="jpaTransactionManager"></jpa:repositories> </beans>
@Entity @Table(name = "student") public class Student { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "sid") private Integer id; @Column(name = "sname") private String name; @Column(name = "sage") private Integer age; @Column(name = "smoney") private Double money; @Column(name = "saddress") private String address; //下面get/set/构造/toString都省略 //注意:我上面的都使用包装类,切记要使用包装类, // 原因可能数据库某个字段查询出来的值为空 null }
//@Repository("studentDao") 这里不用加入IOC容器 Spring默认帮我们注入 public interface StudentDao extends JpaRepository<Student, Integer>, JpaSpecificationExecutor<Student> { /* JpaRepository<T,ID>:T:当前表的类型 ID:当前表主键字段类型 功能:用来完成基本的CRUD操作 ,因为内部定义了很多增删改查操作 JpaSpecificationExecutor<T>:T:当前表的类型 功能:用来完成复杂的查询等一些操作 */ }
@RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(locations = "classpath:applicationContext.xml") public class Client { //注入数据 @Autowired @Qualifier(value = "studentDao") private StudentDao sd; @Test public void test() { //查询id为4学生 Student student = sd.findOne(4); System.out.println("开始打印:" + student); //开始打印:Student{id=4, name=‘霍元甲‘, age=23, money=5555.8, address=‘null‘} } }
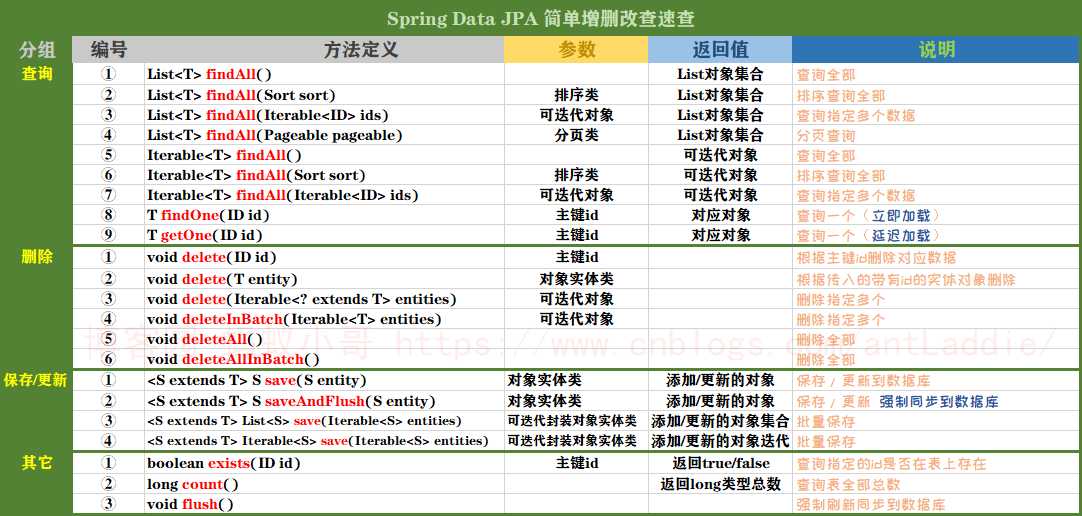
在针对上面方法进行操作的时候,我们的Dao接口必须继承JpaRepository<T,ID>和JpaSpecificationExecutor<T>(后面复杂查询使用),大家也可以去研究一下CrudRepository类,这个类在这里就不说了,JpaRespository类间接实现了它
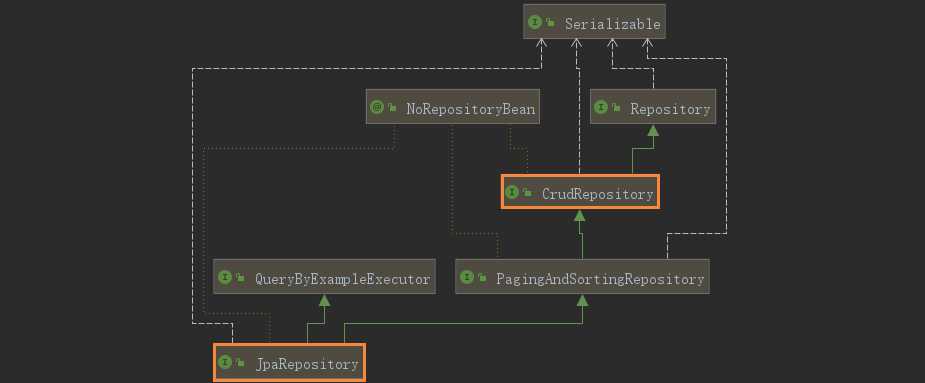
①:Repository:最顶层的接口,是一个空的接口,目的是为了统一所有Repository的类型,且能让组件扫描的时候自动识别。
②:CrudRepository :是Repository的子接口,提供CRUD的功能
③:PagingAndSortingRepository:是CrudRepository的子接口,添加分页和排序的功能
④:JpaRepository:是PagingAndSortingRepository的子接口,增加了一些实用的功能,比如:批量操作等。
⑤:JpaSpecificationExecutor:用来做负责查询的接口
⑥:Specification:是Spring Data JPA提供的一个查询规范,要做复杂的查询,只需围绕这个规范来设置查询条件
@RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(locations = "classpath:applicationContext.xml") public class Client { //注入数据 @Autowired @Qualifier(value = "studentDao") private StudentDao sd; /****************************查询操作*****************************/ @Test //查询并排序 public void findtestA() { //查询全部 先对age排序后在进行id排序 Sort sort = new Sort(Sort.Direction.DESC, "age", "id"); List<Student> students = sd.findAll(sort); //打印省略 } @Test //查询并分页 public void findtestB() { //查询分页 page是第几页 size 每页个数 当前是第2页查询3个 相当limit 6,3 Pageable pageable = new PageRequest(2, 3); Page<Student> page = sd.findAll(pageable); System.out.println("当前页:"+page.getNumber()); System.out.println("每页显示条目数:"+page.getSize()); System.out.println("总页数:"+page.getTotalPages()); System.out.println("结果集总数量:"+page.getTotalElements()); System.out.println("是否是首页:"+page.isFirst()); System.out.println("是否是尾页:"+page.isLast()); System.out.println("是否有上一页:"+page.hasPrevious()); System.out.println("是否有下一页:"+page.hasNext()); System.out.println("结果集:"+page.getContent()); /* 当前页:2 每页显示条目数:3 总页数:3 结果集总数量:7 是否是首页:false 是否是尾页:true 是否有上一页:true 是否有下一页:false 结果集:[Student{id=7, name=‘马克思‘, age=20, money=2222.8, address=‘安徽大别山‘}] */ //总结:以后做分页操作变容易了呀 } @Test //查询指定学生 public void findtesC() { //创建一个集合 List就是一个Iterable可迭代容器对象,因为实现了Iterable接口 List<Integer> list = new ArrayList<Integer>() {{ add(1);add(5);add(3); }}; List<Student> students = sd.findAll(list); //打印省略 } /****************************更新操作*****************************/ @Test //更新多个学生 更新学生全部地址为 安徽合肥 @Transactional @Rollback(value = false) public void savetestA() { //创建2个集合 第一个集合查询全部数据,然后把集合里对象地址改为新的放入新集合上,后面迭代更新 List<Student> list = sd.findAll(); System.out.println(list.size()); List<Student> newlist = sd.findAll(); for (int i = 0; i < list.size(); i++) { Student student = list.get(i); student.setAddress("安徽合肥"); System.out.println(student); newlist.add(student); } List<Student> save = sd.save(newlist); //打印略 } /****************************删除操作*****************************/ @Test //删除指定学生 public void deletetest() { List<Integer> list = new ArrayList<Integer>() {{ add(1);add(5);add(3); }}; List<Student> all = sd.findAll(list); sd.deleteInBatch(all); } /** * 删除方法介绍: * void deleteAll():底层会一条一条删除 * void delete(Iterable<? extends T> entities):底层会一条一条删除 * void deleteAllInBatch():底层会生成一个带or语句删除 * void deleteInBatch(Iterable<T> entities):底层会生成一个带or语句删除 * 如:Hibernate: delete from student where sid=? or sid=? or sid=? */ }
提取注意点:????【添加/更新/查询单个】 ????
①:查询单个getOne/findOne 【延迟加载/立即加载】
@Test //查询单个 立即加载 public void findOneTest(){ Student student = sd.findOne(3); System.out.println("-------分割线-------"); System.out.println("打印对象:"+student); //控制台打印: /* Hibernate: select student0_.sid as sid1_0_0_, student0_.saddress as saddress2_0_0_, student0_.sage as sage3_0_0_, student0_.smoney as smoney4_0_0_, student0_.sname as sname5_0_0_ from student student0_ where student0_.sid=? 【SQL语句】 -------分割线------- 打印对象:Student{id=3, name=‘李小二‘, age=23, money=6666.8, address=‘安徽大别山‘} */ //说明:在一执行到方法时就会去数据库查询,然后把数据封装到实体类对象上 //底层调用: EntityManager里面的find()方法 } @Test //查询单个 懒加载【延迟加载】 @Transactional //此包下import org.springframework.transaction.annotation.Transactional; public void getOneTest(){ Student student=sd.getOne(3); System.out.println("-------分割线-------"); System.out.println("打印对象:"+student); //控制台打印 /* -------分割线------- Hibernate: select student0_.sid as sid1_0_0_, student0_.saddress as saddress2_0_0_, student0_.sage as sage3_0_0_, student0_.smoney as smoney4_0_0_, student0_.sname as sname5_0_0_ from student student0_ where student0_.sid=? 打印对象:Student{id=3, name=‘李小二‘, age=23, money=6666.8, address=‘安徽大别山‘} */ //说明:在执行到getOne方法时并不会去数据库查询数据,而只是把此方法交给了代理对象,在后面 // 某个代码要对查询的对象student操作时才会去数据库做真正查询 //底层调用:EntityManager里面的getReference方法 }
这里说明一下:在使用延迟加载的时候必须在方法上面加事务注解
②:添加/更新操作
@Test //添加 @Transactional //开启事务 @Rollback(value = false) //不自动回滚 public void savetestA(){ //注意这里 我调用了一个不带 ID的构咋函数 Student student=new Student("苍井空",25,555.6,"日本东京"); Student save = sd.save(student); System.out.println("添加的数据是:"+save); } @Test //更新 public void updatetestA(){ //更新操作的时候 首先要知道更新的ID 后通过把数据全部查询出来,然后再通过set方法修改 Student student = sd.findOne(5); //查询 student.setName("小次郎"); student.setAddress("日本"); //更新 Student save = sd.save(student); System.out.println("更新后的数据是:"+save); } /** * 总结:更新/添加都是save * 区别:传入带ID的属性就是更新 不传入ID属性就是添加 * 注意:添加必须添加事务和回滚机制 */
综上总结:在了解了前面的一些简单的增删改查,它都是内部提供好的方法(前提实现指定接口),可以满足我们开发的大部分需求,可是多表查询、多条件查询等等是系统没有定义的,接下来我和大家介绍一下复杂的查询及动态查询等等
其实我们在使用SpringDataJPA提供的方法就可以解决大部分需求了,但是对于某些业务来说是要有更复杂的查询及操作,这里我就要使用自定义接口和注解@Query来完成JPQL的一系列操作,关于JPQL操作我在JPA的一章已经说过大概了
//@Repository("studentDao") //这里不用加入IOC容器 Spring默认帮我们注入 public interface StudentDao extends JpaRepository<Student, Integer>, JpaSpecificationExecutor<Student> { //查询全部 根据年龄和地址查询 @Query("from Student where age=?1 and address=?2") List<Student> findByAgeAndAddress(Integer age,String address); //查询全部 根据姓名模糊查询 @Query("from Student where name like ?1") List<Student> findByLikeName(String name); //查询全部 根据地址为空的返回 @Query("from Student where address is null ") List<Student> findByAddressIsNull(); //查询全部学生零花钱大于平均零花钱的所有学生 @Query("from Student where money > (select avg(money) from Student)") List<Student> findByMoneyBigAvgMoney(); //查询零花钱在某个范围内并且降序 @Query("from Student where money between ?1 and ?2 order by money desc") List<Student> findByMoneyBetweenToOrderBy(Integer begin ,Integer end); //查询全部个数 @Query("select count(id) from Student") Long totalCount(); /*********************删改操作************************/ //根据姓名删除 @Query("delete from Student where name=?1") @Modifying void deleteByName(String name); //更新数据 @Query("update Student set name=?2 , address=?3 where id=?1") @Modifying void updateNameAndAddressById(Integer id,String name,String address); }
@Test @Transactional @Rollback(value = false) public void test() { //里面调用JPQL自定义的删改操作 } 说明: 在使用@Query注解里面定义的JPQL语法时 查询不需要事务支持,但是删改必须有事务及回滚操作,
而且在定义JPQL语句下面要注明@Modify代表是删改 JPQL 里面不存在添加insert操作,所有大家要添加操作的话 调用原来存在的方法
//@Repository("studentDao") //这里不用加入IOC容器 Spring默认帮我们注入 public interface StudentDao extends JpaRepository<Student, Integer>, JpaSpecificationExecutor<Student> { //使用排序 地址模糊查询后 再按照id降序排列 @Query("from Student where address like ?1 ") List<Student> findByLikeAddressOrderById(String address, Sort sort); //使用命名参数 查询年龄和地址模糊查询 @Query("select s from Student as s where address like :address and age=:age") List<Student> findByLikeAddressAndAge(@Param(value="age") Integer s_age,@Param("address") String s_address); } /***下面测试方法****/ @Test //查询学生带排序 public void test() { //说在前面:Sort如果不指定DESC或者ASC 如 new Sort("id");说明默认对id ASC升序排列 //设置id为DESC降序排列 Sort sort = new Sort(Sort.Direction.DESC, "id"); List<Student> students = sd.findByLikeAddressOrderById("%大%", sort); //打印略 } @Test //使用命名参数 public void testA() { List<Student> students = sd.findByLikeAddressAndAge(23, "%大别山%"); //打印略 }
这种写SQL语句的在SpringDataJPA中并不常用,因为SpringDataJPA对封装性那么高,而且是ORM思想,有各种方法及JPQL语句支持,所有我们本地SQL查询也只要了解会用即可,SQL语句和我们平常写的都一样
//@Repository("studentDao") //这里不用加入IOC容器 Spring默认帮我们注入 public interface StudentDao extends JpaRepository<Student, Integer>, JpaSpecificationExecutor<Student> { //查询指定的年龄和地址 @Query(value = "select * from student where sage=?2 and saddress=?1",nativeQuery = true) List<Student> findByAgeAndAddress(String address,Integer age); }
在Spring Data JPA里面有一种很不错的操作,那就是在接口中定义方法而不用实现也不用注解就可以实现其查询操作,但是写方法名查询是有一套规范的,这里我在官方文档里面整理出来了分享给大家【注意:方法名命名规则不能对其增加(insert)和修改(update)】
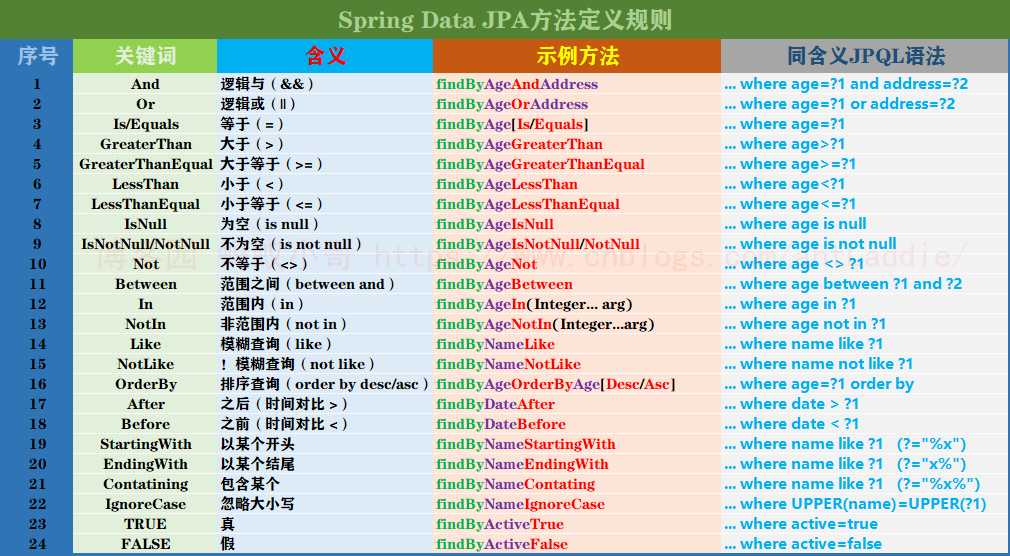
①:方法名查询的具体规则
//示例场景 //当前域为Student 就是对Student上注解了@Entity,表示对于ORM思想它是一张表 //Student域属性有name、age、address、dog //dog里面又是一个封装类 封装了Dog的一些属性如 name、color等 ①:按照Spring data的定义规则,查询的方法必须为【find/findBy/read/readBy/get/getBy】六种方式开头,后面则写条件属性关键字,条件属性的 首字母必须大写,因为框架在进行方法名解析的时候,会把方法名前面多余的前缀截取掉,然后对剩下的进行解析 例: 截取前:getByNameAndAge 截取后:NameAndAge 截取前:findByAddressLikeAndAge 截取后:AddressLikeAndAge 截取前:findByDogName 截取后:DogName 问题:findByNameOrderByDesc 这种最后携带一个 OrderByDesc 排序的怎么办呢? 其实最后面携带这种对数据进行最后的排序等等操作,框架会对其另外拆分 ②:对已经分割好的方法名如 ‘DogName’ ,根据POJO规范会把首字母变为小写 ‘dogName’,然后用 ‘dogName’这个属性去Student域里 面查询是否存在此属性,如果是里面的某个属性则进行查询。 ③:如果查询不到此属性,则会对‘dogName’从右向左来截取,截取到从右向左的第一个大写字母(所有截取到了Name),然后框架会把剩下 的字符‘dog’去Student域里面查询,找到此属性则查询,没有会重复前面的截取操作,(重要步骤) ④:现在框架提取到了到了‘dog’,然后去Student域查询到了,则表示方法最终是根据Student.dog.name方式进行查询,假设name属性后面 还是一个封装类,框架会一直截取,根据③方式截取。 注意:在写上面这类方法名是,而且查询的里面会有一层一层的封装类,所有强烈建议使用findByDog_Name();
②:注意一些细节(必看)
1:查询的条件为null时 实体介绍:Student里面包含 address为String类型 age为Integer类型 查询方法定义:List<Student> findByAddressAndAge(String address, Integer age); 调用时传入值:List<Student> students = sd.findByAddressAndAge(null,23); 后台生成的SQL:where (student0_.saddress is null) and student0_.sage=? 结论:当我们传入了一个null值时,表示会去查询数据库中address中字段为null的数据其实在编写此代码传入null值以为会跳过此判断, 但是恰恰相反,框架会去查询为null的数据。(实现此方式的只能去动态查询,这种简单的查询不能满足要求) 2:排序功能 List<Student> findByAddressOrderByAge(String address); //名称正序(正序时,推荐此方式,简单) List<Student> findByAddressOrderByAgeAsc(String address); //名称正序(效果同上) List<Student> findByAddressOrderByAgeDesc(String address); //名称倒序 3:限定查询结果集大小 ①:Student findFirstByOrderByAgeAsc(); ②:Student findTopByOrderByAgeAsc(); 说明:对表的全部数据根据age进行Asc(升序)排序后再选择第一条数据返回 相应SQL:select .... from student student0_ order by student0_.sage asc limit ? (这里是limit 1) 注意但是我如果写出:List<Student> findTop3ByOrderByAgeAsc(); 则就是每次返回3条 limit 3 ③:List<Student> findFirst2ByAddress(String address,Sort sort); ④:List<Student> findTop2ByAddress(String address,Sort sort); 说明:首先进行数据查询并通过Sort进行排序后 再筛选数据列表中最前面的2行数据返回 limit 2 ⑤:Page<Student> queryFirst2ByAddress(String address, Pageable pageable) ⑥:List<Student> queryFirst2ByAddress(String address, Pageable pageable) 说明:首先进行数据查询 查询全部指定的address后进行分页,分页完后进行数据控制 控制说明:关于带分页的控制是,假设分页过后查询的数据id为3,4,5 查询出这三条数据后进行数据控制, 本案例是控制为2条,那返回的id数据就是3,4两条记录,id为5的就舍弃,那么如果数据控制是5条, 那么就会打印3,4,5另外再去添加6,7补充数据长度 总结:这里的这里的First和Top意思相同都是最前面,query也和find一样; 关于一个小点: Page<Student> students = sd.queryFirst1ByAddress("安徽大别山",new PageRequest(1,2)); 这里我是返回分页后的第一条数据,可是返回了分页数据的前一个,分页后id是3,4控制数据后First1 返回了id为2 4:计数 返回总数 Long countByAddress(String address); 5:删除 void deleteByAddress(String address); //或 void removeByAddress(String address); 说明:必须添加事务和回滚,这样根据条件找到几条就删几条 @Test @Transactional @Rollback(value=false) public void test() { sd.deleteByAddress("安徽大别山"); } //对应的SQL语句 //Hibernate: select .... from student student0_ where student0_.saddress=? //Hibernate: delete from student where sid=? //Hibernate: delete from student where sid=? //Hibernate: delete from student where sid=? //Hibernate: delete from student where sid=? //Hibernate: delete from student where sid=? //Hibernate: delete from student where sid=?
③:列举几个常用的方法定义查询
//根据地址查询后进行姓名模糊匹配 List<Student> findByAddressAndNameLike(String address ,String likeName); //查询指定范围类的个数 List<Student> countByAgeBetween(Integer ... arg); //根据对应的Address查询后对查询出的数据根据age排序后返回第一条数据 Student findFirstByAddressOrderByAgeDesc(String address);
通过前几节的增删改查大家会发现,我们不用写Dao接口实现类而是继承JpaRepository和JpaSpecificationExcutor这两个接口就能够保证正常的增删改查功能,这是为什么呢?
//@Repository("studentDao") //这里不用加入IOC容器 Spring默认帮我们注入 public interface StudentDao extends JpaRepository<Student, Integer>, JpaSpecificationExecutor<Student> {}
@RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(locations = "classpath:applicationContext.xml") public class Client { //注入数据 @Autowired @Qualifier(value = "studentDao") private StudentDao sd; //这里注入进去的数据又是谁呢? @Test public void testA(){ //查询单个 Student one = sd.findOne(2); System.out.println(one); } }
其实不难想象,但凡是凭空就可以注入对象的,这内部肯定用到了JDK动态代理,那JDK代理类又是谁呢?经过debug发现是JdkDynamicAopProxy
final class JdkDynamicAopProxy implements AopProxy, InvocationHandler, Serializable {
....//这个类实现了InvocationHandler 那必然有invoke方法,这里面是操作该生成哪个代理对象返回 }
所有说在那个注入的时候,Spring AOP就是通过JdkDyynamicAopProxy类帮我们实现的,那这个代理类最终创建的代理返回的对象又是谁呢?

那我们再去查看一下SimpleJpaRepository类,肯定是实现了我们自己接口继承的2个类,而且也有许多的操作方法的实现
@Repository @Transactional(readOnly = true) public class SimpleJpaRepository<T, ID extends Serializable> implements JpaRepository<T, ID>, JpaSpecificationExecutor<T> {
.....
}
总结:就是通过Jdk动态代理生成一个对象返回注入后,我们就可以调出各种操作方法
在日常编程中往往是查询某个实体的时候,给定的条件是不固定的,那我们在不固定查询条件的情况下就在Dao编写查询方法吗?这显然是不可取的,只要在确定及肯定会用到这个查询条件后才会去Dao编写此查询方法;那么在查询不固定的情况下我们就会用到Specification动态查询,要想使用动态查询的话必须在当前使用的Dao接口下继承JpaSpecificationExecutor接口;在使用动态查询对比JPQL,其动态查询是类型安全,更加面向对象。
/** * ①:JpaSpecificationExecutor: * 用来做动态查询的接口 * ②:Specification: * 是Spring Data JPA提供的一个查询规范,要做复杂的查询,只需围绕这个规范来设置查询条件。 * JpaSpecificationExecutor接口下一共就5个接口方法 * 有查询单个、查询全部、查询全部【分页】、查询全部【排序】、统计总数 */ public interface JpaSpecificationExecutor<T> { T findOne(Specification<T> spec); List<T> findAll(Specification<T> spec); Page<T> findAll(Specification<T> spec, Pageable pageable); List<T> findAll(Specification<T> spec, Sort sort); long count(Specification<T> spec); }
①:Root<X> 接口 此接口是代表查询根对象,可以获取实体类中的属性 如:root.get("name"); 获取了实体类的name属性 ②:CriteriaBuilder 接口 此接口用来构建查询,此对象里面有许多查询条件方法 方法名称 Sql对应关系 equle filed = value gt(greaterThan ) filed > value lt(lessThan ) filed < value ge(greaterThanOrEqualTo ) filed >= value le( lessThanOrEqualTo) filed <= value notEqule filed != value like filed like value notLike filed not like value 注:其实这里面还有许多的查询条件方法如求平均值啦查询指定范围等等
①:根据某个字段查询单个数据
//查询单个 @Test public void testB() { // Specification:查询条件设置 Specification<Student> spe = new Specification<Student>() { //实现接口的方法 关于Root、CriteriaBuilder上面有介绍 public Predicate toPredicate(Root<Student> root, CriteriaQuery<?> query, CriteriaBuilder cb) { //获取实体属性name Path<Object> name = root.get("name"); //根据指定的姓名查询 Predicate select = cb.equal(name, "蚂蚁小哥"); //返回一定是Predicate类型 return select; } }; //查询单个 Student student = sd.findOne(spe); System.out.println(student); }
②:多条件查询、模糊查询等一些操作
@RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(locations = "classpath:applicationContext.xml") public class Client { //注入数据 @Autowired @Qualifier(value = "studentDao") private StudentDao sd; @Test //多条件查询 public void testC() { //根据年龄和地址查询 Specification<Student> spe=new Specification<Student>() { public Predicate toPredicate(Root<Student> root, CriteriaQuery<?> query, CriteriaBuilder cb) { Path<Object> age = root.get("age"); Path<Object> address = root.get("address"); Predicate p1 = cb.equal(age, "23"); Predicate p2 = cb.equal(address, "安徽大别山"); Predicate select = cb.and(p1, p2); return select; } }; List<Student> students = sd.findAll(); //打印略 } @Test //查询多个条件 public void testD(){ //根据精准地址和模糊姓名查询 List<Student> students = sd.findAll(new Specification<Student>() { public Predicate toPredicate(Root<Student> root, CriteriaQuery<?> query, CriteriaBuilder cb) { Path<Object> address = root.get("address"); Path<Object> name = root.get("name"); Predicate p1 = cb.equal(address, "安徽大别山"); Predicate p2 = cb.like(name.as(String.class), "李%"); return cb.and(p1,p2); } }); //注!!!:在使用gt、lt、ge、le、like等条件方法查询的时候需要告知传入的属性的class属性 //如:cb.like(name.as(String.class), "李%"); //打印略 } @Test //查询全部为指定住址的学生带年龄排序 public void testE(){ List<Student> students = sd.findAll(new Specification<Student>() { public Predicate toPredicate(Root<Student> root, CriteriaQuery<?> query, CriteriaBuilder cb) { return cb.equal(root.get("address"), "安徽大别山"); } }, new Sort(Sort.Direction.DESC, "age")); } @Test //查询全部带分页 public void testF(){ Page<Student> students = sd.findAll(new Specification<Student>() { public Predicate toPredicate(Root<Student> root, CriteriaQuery<?> query, CriteriaBuilder cb) { return null; //return null 代表没条件查询全部 } }, new PageRequest(2, 2)); } }
我们在之前使用过了Root和CriteriaBuilder的2个接口,可是里面还有一个参数,是CriteriaQuery接口,它代表一个顶层查询条件,用来自定义查询,操作顶层查询可以使我们更灵活,但是在灵活的基础上又多了一丝丝复杂
@Test //多条件查询 public void testC() { //根据年龄和地址查询 Specification<Student> spe=new Specification<Student>() { public Predicate toPredicate(Root<Student> root, CriteriaQuery<?> query, CriteriaBuilder cb) { Path<Object> age = root.get("age"); Path<Object> address = root.get("address"); Predicate p1 = cb.equal(age, "23"); Predicate p2 = cb.equal(address, "安徽大别山"); //query内部提供了一些连接用的如where 、having、groupBy.... query.where(cb.and(p1,p2)); return query.getRestriction(); } }; List<Student> students = sd.findAll(); System.out.println(students); //打印略 }
1:确定多表之间的关系: 一对一和一对多: 一的一方称为主表,而多的一方称为从表,外键就要建立在从表上,它们的取值的来源主要来自主键 多对多: 这个时候需要建立一个中间表,中间表中最少由2个字段组成,这2个字段作为外键指向2张表的主键又组成了联合主键 2:配置多表联系注解介绍 @OneToOne(一对一) @ManyToOne(多对一) @OneToMany(一对多) @ManyToMany(多对多) 内部参数: cascade:配置级联操作 CascadeType.ALL:所有 CascadeType.MERGE:更新 CascadeType.PERSIST:保存 CascadeType.REMOVE:删除 fetch:配置延迟加载和立即加载 FetchType.EAGER 立即加载 FetchType.LAZY 延迟加载 mappedBy:放弃外键维护 3:配置外键关系的注解 @JoinColumn(定义主键字段和外键字段的对应关系) 内部参数: name:外键字段的名称 referencedColumnName:指定引用主表的主键字段名称 unique:是否唯一。默认值不唯一 nullable:是否允许为空。默认值允许。 insertable:是否允许插入。默认值允许。 updatable:是否允许更新。默认值允许。 columnDefinition:列的定义信息。 @JoinTable(针对中间表的设置) 内部参数: name:配置中间表的名称 joinColumns:中间表的外键字段关联当前实体类所对应表的主键字段 inverseJoinColumn:中间表的外键字段关联对方表的主键字段
在多表操作中、一对一并不是我们掌握的重点,因为在开发中最多的还是使用一对多(多对一)和多对多,废话不多说,我先来和大家说说一对一的具体操作步骤吧!
我们在开始使用多表操作的时候,要对原来的部分代码进行改造,建议大家搭建一个全新的项目,具体的代码我已经在最上面的入门案例中给出了,只要在新项目中导入相应的坐标和配置文件即可,然后修改配置文件里面的具体数据库和数据库密码即可,还有就是现在的建表语句和上面的全部操作不太一样,为了更好的演示一对一的操作我这边准备了一个数据库建表语句,下面的表含义是,每个学生表(student)都有一条家庭(family)的登记的记录表,为一对一关系(理想化表,双胞胎除外)
-- 一对一关系 -- 删除库 drop database demo_jpa_one_one; -- 创建库 create database if not exists demo_jpa_one_one charset gbk collate gbk_chinese_ci; -- 使用库 use demo_jpa_one_one; # 家庭表创建 create table if not exists family( fid int(11) primary key auto_increment, -- 家庭主键 fmember int(11) not null, -- 成员个数 fguardian varchar(10) not null, -- 监护人 ftel char(11) not null, -- 监护人号码 fdad varchar(10), -- 爸爸姓名 fmom varchar(10), -- 妈妈姓名 faddress varchar(20) -- 家庭详细地址 )charset gbk; # 创建学生表 create table if not exists student ( sid int(11) primary key auto_increment, -- 编号 sname varchar(5) not null, -- 姓名 ssex enum(‘男‘,‘女‘) default ‘男‘, -- 性别 sage tinyint(11) unsigned not null default 20, -- 年龄 smoney decimal(4,1) default 0, -- 零花钱 最高999.9 saddress varchar(10), -- 住址 senrol date default ‘0000-00-00‘, -- 入学时间 f_id int(11), -- 连接家庭id foreign key(f_id) references family(fid) -- 连接家庭id主键 )charset gbk; # 添加家庭信息 insert into family(fmember,fguardian,ftel,fdad,fmom,faddress)values (0,"余蒙飘","","戚曦维","余蒙飘","安徽省六安市裕安区"), (0,"孙恋烈","","梁轮亭","孙恋烈","安徽省合肥市瑶海区"), (0,"张频时","","张频时","","安徽省安庆市宜秀区"), (0,"王京正","","王京正","梁昼庭","安徽省六安市金安区"), (0,"刘资纳","","王谆斌","刘资纳","安徽省滁州市全椒县"), (0,"白飞解","","廖旺赐","白飞解","安徽省安庆市大观区"), (0,"梁昀辉","","邬国耿","梁昀辉","安徽省蚌埠市蚌山区"), (0,"古录钢","","","古录钢","安徽省滁州市定远县"), (0,"姬桥毅","","姬桥毅","宁竹熊","安徽省合肥市蜀山区"), (0,"刘始瑛","","刘始瑛","韦欢亿","安徽省淮南市大通区"); # 添加学生数据 insert into student(sid,sname,saddress,f_id)values (1 ,"王生安","安徽六安",1 ),(2 ,"李鑫灏","安徽合肥",2 ), (3 ,"薛佛世","安徽蚌埠",3 ),(4 ,"蔡壮保","安徽安庆",4 ), (5 ,"钱勤堃","安徽合肥",5 ),(6 ,"潘恩依","安徽合肥",6 ), (7 ,"陈国柏","安徽六安",7 ),(8 ,"魏皑虎","安徽六安",8 ), (9 ,"周卓浩","安徽六安",9 ),(10,"汤辟邦","安徽六安",10); -- 更新数据 update student set ssex=ceil(rand()*2),sage=ceil(rand()*5+20),smoney=(rand()*999), senrol=concat(ceil(rand()*3+2017),‘-‘ , ceil(rand()*12) , ‘-‘,ceil(rand()*20)); update family set ftel=concat(if(ceil(rand()*3)=1,if(ceil(rand()*3)=2,if(ceil(rand()*3)=1, if(ceil(rand()*3)=2,"155","166"),if(ceil(rand()*3)=3,"163","170")),"164"), if(ceil(rand()*3)=3,"188","176")),floor(rand()*90000000+9999999)),fmember=ceil(rand()*3+2); -- 查询数据 show create table student\G show create table family\G select * from student; select * from family;
其实我们并不需要创建数据库表(数据库必须创建),因为我们使用的是ORM思想的框架,说白了就是程序自动帮我们创建表(设置create配置),我们只需要关心实体类就可以了,这个实体类我也为大家准备好了
/** * 创建了一个Student的实体-表关系类 */ @Entity @Table(name = "student") public class Student { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "sid") private Integer id; @Column(name = "sname") private String name; @Column(name = "ssex") private String sex; @Column(name = "sage") private Integer age; @Column(name = "smoney") private Double money; @Column(name = "saddress") private String address; @Column(name = "senrol") private String enrol; //get/set/toString/无参有参构造器 大家自己创建 }
/** * 创建了一个Family的实体-表关系类 */ @Entity @Table(name = "family") public class Family { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "fid") private Integer id; @Column(name = "fmember") private Integer member; @Column(name = "fguardian") private String guardian; @Column(name = "ftel") private String tel; @Column(name = "fdad") private String dad; @Column(name = "fmom") private String mom; @Column(name = "faddress") private String address; //get/set/toString/无参有参构造器 大家自己创建 }
在准备好了映射关系之后,我们要创建StudentDao、FamilyDao这2个接口,并且分别继承JpaRepository和JpaSpecificationExecutor这2个接口,完成了这些操作后就可以开始编写测试类了
<!--大家把配置文件的JPA配置方式改为create每次都创建表--> <property name="jpaProperties"> <props> <prop key="hibernate.hbm2ddl.auto">create</prop> </props> </property>
@RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(locations = "classpath:applicationContext.xml") public class Client { //注入数据 @Autowired @Qualifier(value = "studentDao") private StudentDao sd; @Autowired @Qualifier(value = "familyDao") private FamilyDao fd; @Test //完成保存操作 @Transactional @Rollback(value = false) public void testC() { Student stu=new Student("王二","男",26,666.3,"安徽六安","2020-6-5"); Family fam=new Family(3,"王二牛","17688888888","王二牛","母老虎","安徽六安裕安区白嫖村"); //开始保存 sd.save(stu); fd.save(fam); } }
如果不出意外,大家可能会遇到一个异常,这正是我想和大家说的,具体说明在文章最后的【关于多表操作异常】问题总结和大家说明一下,我们解决问题后回来再次运行后,控制台会打印2条建表语句和插入数据的语句,前面说过,这2张表是一个一对一的关联关系,我们接下来就对这2张表建立关系。
建立关系 Student---Family (一对一) 为Student建立关联到Family的关系(在Student中增加一个字段) @OneToOne(targetEntity = Family.class) @JoinColumn(name = "f_id", referencedColumnName = "fid") private Family family; 为Family建立关联到Student的关系(在Family中增加一个字段) @OneToOne(targetEntity = Student.class) @JoinColumn(name = "f_id", referencedColumnName = "sid") private Student student; 这样就完成了相互引用了,每个实体类都拥护一个对方实体,完成了一对一的关联
完成了关联后我们对测试方法进行改造
@Test //多条件查询 @Transactional @Rollback(value = false) public void testC() { Student stu = new Student("王二", "男", 26, 666.3, "安徽六安", "2020-6-5"); Family fam = new Family(3, "王二牛", "17688888888", "王二牛", "母老虎", "安徽六安裕安区白嫖村"); //通过set方法分别设置对应的字段,使其关联 stu.setFamily(fam); fam.setStudent(stu); sd.save(stu); fd.save(fam); }
运行后会自动帮我们创建2张表并且设置外键
mysql> select * from student; +-----+----------+------+----------+--------+-------+------+------+ | sid | saddress | sage | senrol | smoney | sname | ssex | f_id | +-----+----------+------+----------+--------+-------+------+------+ | 1 | 安徽六安 | 26 | 2020-6-5 | 666.3 | 王二 | 男 | 1 | +-----+----------+------+----------+--------+-------+------+------+ mysql> select * from family; +-----+----------------------+--------+-----------+---------+--------+-------------+------+ | fid | faddress | fdad | fguardian | fmember | fmom | ftel | f_id | +-----+----------------------+--------+-----------+---------+--------+-------------+------+ | 1 | 安徽六安裕安区白嫖村 | 王二牛 | 王二牛 | 3 | 母老虎 | 17688888888 | 1 | +-----+----------------------+--------+-----------+---------+--------+-------------+------+
发现自动帮我们创建的表会有2个外键,可是这2个外键是多余的,我们这个时候需要放弃外键维护,按照之前的一对一建表语句说明,外键是建立在学生表上的,通过学生表上面的外键来寻找到家庭表的信息,这个时候我们在家庭表上面放弃外键维护
//@OneToOne(targetEntity = Student.class) //@JoinColumn(name = "f_id", referencedColumnName = "sid") //引用对方的字段 @OneToOne(mappedBy = "family") private Student student;
<property name="jpaProperties"> <props> <prop key="hibernate.hbm2ddl.auto">update</prop> <!--设置数据库方言--> <prop key="hibernate.dialect">org.hibernate.dialect.MySQL5InnoDBDialect</prop> </props> </property>
@Test //多条件查询 @Transactional @Rollback(value = false) public void testC() { System.out.println(sd.findOne(1)); //我们要编写toString方法后才可以打印全部 }
其实一对多和多对一本质上是一样的,只是顺序发生了变化,我就详细的把一对多给讲一下,在这里我已经有过一个数据库建表语句,但是因为是ORM项目,我们建表语句是由程序帮我们自动创建的,之所以我编写了SQL语句是为了方便后期查询练习
#### 一对多 这里我使用的关系是一个老师对应多个学生,一个学生对应一个老师 #### 老师表为主表、学生表为从表 #### 一对多 -- 删除库 drop database demo_jpa_one_many; -- 创建库 create database if not exists demo_jpa_one_many charset gbk collate gbk_chinese_ci; -- 使用库 use demo_jpa_one_many; -- 创建主表 (辅导员表) create table if not exists teacher( tid int primary key, -- 编号 tname varchar(5) not null, -- 姓名 tsex enum(‘男‘,‘女‘) default ‘男‘, -- 性别 tage tinyint unsigned, -- 年龄 tsalary decimal(6,1) default 0, -- 工资 最高99999.9 taddress varchar(10) -- 住址 )charset gbk collate gbk_chinese_ci; -- 创建从表 (学生表) create table if not exists student ( sid int(11) primary key auto_increment, -- 编号 sname varchar(5) not null, -- 姓名 ssex enum(‘男‘,‘女‘) default ‘男‘, -- 性别 sage tinyint(11) unsigned not null default 20, -- 年龄 smoney decimal(4,1) default 0, -- 零花钱 最高999.9 saddress varchar(10), -- 住址 senrol date default ‘0000-00-00‘, -- 入学时间 tid int , -- 连接老师id foreign key(tid) references teacher(tid) -- 连接老师主键 )charset gbk; -- 添加老师数据 insert into teacher (tid,tname,taddress)values (1,‘张老师‘,‘江苏南京‘), (2,‘李老师‘,‘江苏无锡‘), (3,‘王老师‘,‘江苏常熟‘); -- 添加学生数据 insert into student(sid,sname,saddress)values (1 ,"王生安","安徽六安"),(2 ,"李鑫灏","安徽合肥"), (3 ,"薛佛世","安徽蚌埠"),(4 ,"蔡壮保","安徽安庆"), (5 ,"钱勤堃","安徽合肥"),(6 ,"潘恩依","安徽合肥"), (7 ,"陈国柏","安徽六安"),(8 ,"魏皑虎",null); -- 数据更新 update teacher set tsex=ceil(rand()*2),tage=ceil(rand()*10+25),tsalary=ceil(rand()*3000+8000); update student set ssex=ceil(rand()*2),sage=ceil(rand()*5+20),smoney=(rand()*999), senrol=concat(ceil(rand()*3+2017),‘-‘ , ceil(rand()*12) , ‘-‘,ceil(rand()*20)),tid=ceil(rand()*3);
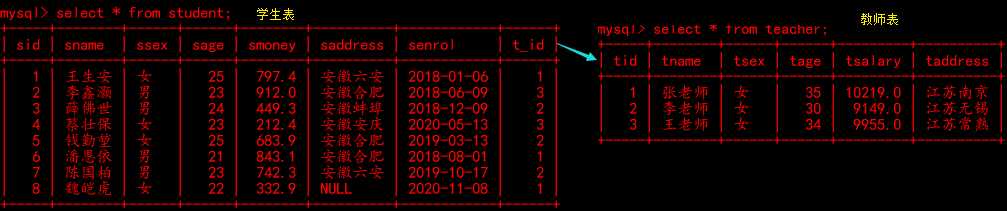
此时的一对多关系是【一个老师有多个学生】,反之,如果是多对一只需要调换关系即可,2者差不多,我就针对这个一对多讲解;在编写程序之前我们必须要搞明白什么是主表和从表的关系,这影响到我们后面编写一对多的关系:
主表:
由主键和其它字段组成,后期由其它表参照当前表主键,此时的表为主表,
在其它表中如果引用主表的主键字段,那么主表的主键被引用后将不能随意更改,
如果强制更改则必须设置级联操作(cascade)
从表:
由主键、外键和其它字段组成,后期由本表的外键字段去引用其它带有主键的表,一旦其它的
表主键被引用后,被引用的表则被称为主表,反之引用其它表主键的表被称之从表
一句话概括:有外键字段的表是从表(排除其它复杂表,因为有的表即引用其它别也被其它表引用)
在我们了解了上面的关系后,我们就可以搭建操作一对多的环境了,首先我们就是要准备建造一个数据库(不是数据表)名称为demo_jpa_one_many,因为这个框架只要编写好映射关系后会自动帮我们创建表的;现在建立一个项目,只需要在空项目导入pom.xml坐标和配置外键(配置文件一定要修改正确数据库连接),我将带大家一步一步完成一对多操作,如果这些都会直接跳过;完成了上面的操作后,我们首先就是要去编写实体类及映射关系:
/** * 创建了一个Teacher的实体-表关系类 * 在案例中 当前老师表为主表 */ @Entity @Table(name = "teacher") public class Teacher { //创建主键字段和普通字段 @Id @Column(name = "tid") private Integer id; @Column(name = "tname") private String name; @Column(name = "tsex") private String sex; @Column(name = "tage") private Integer age; @Column(name = "tsalary") private Double salary; @Column(name = "taddress") private String address; //省略 get/set/有参无参构造器 }
/** * 创建了一个Student的实体-表关系类 * 在案例中 当前学生表为从表 */ @Entity @Table(name = "student") public class Student { //创建主键字段和普通字段 @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "sid") private Integer id; @Column(name = "sname") private String name; @Column(name = "ssex") private String sex; @Column(name = "sage") private Integer age; @Column(name = "smoney") private Double money; @Column(name = "saddress") private String address; @Column(name = "senrol") private String enrol; //省略 get/set/有参无参构造器 }
在完成上面的一些操作后,大家已经完成了实体类及映射的创建,这里我没有为这2张表建立外键关系,因为在没接触过多表操作的话冒然把映射一起写完有可能会出现异常(肯定有人说,这咋这么啰嗦呀)那好,对有操作的,只是复习怎么使用的直接可以当cv攻城师复制即可;现在我们来编写2个dao类
public interface StudentDao extends JpaRepository<Student,Integer>, JpaSpecificationExecutor<Student> { } public interface TeacherDao extends JpaRepository<Teacher,Integer> , JpaSpecificationExecutor<Teacher> { }
写好以后就正式测试了,测试完成后大家会发现是2个没有任何关系的2张独立的表(如果出现异常了去下面查看异常讲解)
@RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(locations = "classpath:applicationContext.xml") public class Client { //注入数据 @Autowired @Qualifier(value = "studentDao") private StudentDao sd; @Autowired @Qualifier(value="teacherDao") private TeacherDao td; @Test //多条件查询 @Transactional @Rollback(value = false) public void testC() { Student student=new Student("张小三","男",25,222.3,"安徽六安","2018-8-8"); Teacher teacher=new Teacher(10,"张老师","男",35,9999.6,"北京顺义"); //保存 td.save(teacher); sd.save(student); } }
mysql> select * from student; +-----+----------+------+----------+--------+--------+------+ | sid | saddress | sage | senrol | smoney | sname | ssex | +-----+----------+------+----------+--------+--------+------+ | 1 | 安徽六安 | 25 | 2018-8-8 | 222.3 | 张小三 | 男 | +-----+----------+------+----------+--------+--------+------+ mysql> select * from teacher; +-----+----------+------+--------+---------+------+ | tid | taddress | tage | tname | tsalary | tsex | +-----+----------+------+--------+---------+------+ | 10 | 北京顺义 | 35 | 张老师 | 9999.6 | 男 | +-----+----------+------+--------+---------+------+
注:创建2表的联系
在创建2表的关系中,我们必须要分清主表和从表的关系,这样才可以设计出一个完整的关系创建,具体的主表和从表上面以给出介绍
创建从表的关系连接(student) 在从表中添加一个引用teacher属性,因为一个student中有一个teacher //创建外键字段 因为从表上有明确外键引用其它表 所以必须要有外键字段 @ManyToOne(targetEntity = Teacher.class) @JoinColumn(name="t_id",referencedColumnName = "tid") private Teacher teacher; 注: targetEntity = Teacher.class:当前引用的主表类型 name="t_id" 代表当前student表中的外键字段 referencedColumnName = "tid" 代表参照主表的哪个字段 建表样式: mysql> select * from student; +-----+----------+------+----------+--------+--------+------+------+ | sid | saddress | sage | senrol | smoney | sname | ssex | t_id | +-----+----------+------+----------+--------+--------+------+------+ | 1 | 安徽六安 | 25 | 2020-6-6 | 666.3 | 李小二 | 男 | 100 | +-----+----------+------+----------+--------+--------+------+------+ ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ 创建主表的关系连接(teacher) 在主表中添加一个引用student的属性,因为一个teacher中有多个student //创建外键字段 这里是主表,所以主动放弃外键维护 //@OneToMany(targetEntity = Student.class) //@JoinColumn(name = "s_id",referencedColumnName = "sid") //引用从的外键字段 @OneToMany(mappedBy = "teacher") private Set<Student> students=new HashSet<Student>(); 注: mappedBy = "teacher" :代表参照对方表 假设主表不放弃外键维护就会出现下面情况: mysql> select * from teacher; +-----+----------+------+--------+---------+------+------+ | tid | taddress | tage | tname | tsalary | tsex | s_id | +-----+----------+------+--------+---------+------+------+ | 100 | 北京顺义 | 32 | 王老师 | 6666.6 | 男 | 1 | +-----+----------+------+--------+---------+------+------+ 问题所在:这时候主表引用从表,而从表也引用主表,这显然不是一个合格设计 解决后:在主表上设置的放弃外键维护,并参照从表的关系 mysql> select * from teacher; +-----+----------+------+--------+---------+------+ | tid | taddress | tage | tname | tsalary | tsex | +-----+----------+------+--------+---------+------+ | 100 | 北京顺义 | 32 | 王老师 | 6666.6 | 男 | +-----+----------+------+--------+---------+------+
创建测试,在测试的时候大家把配置文件的配置改为create,代表每次执行都会创建表
@RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(locations = "classpath:applicationContext.xml") public class Client { //注入数据 @Autowired @Qualifier(value = "studentDao") private StudentDao sd; @Autowired @Qualifier(value="teacherDao") private TeacherDao td; @Test //多条件查询 @Transactional @Rollback(value = false) public void testC() { //创建2个对象 Student student=new Student("李小二","男",25,666.3,"安徽六安","2020-6-6"); Teacher teacher=new Teacher(100,"王老师","男",32,6666.6,"北京顺义"); //把老师放入学生数据中 把学生数据放入老师表中 student.setTeacher(teacher); teacher.getStudents().add(student); //保存 这里注意一下,因为我的teacher主键不是自动生成 , // 所以先保存teacher才可以保存student,因为teacher主键不是自动生成,直接先保存student会无法获取teacher主键 td.save(teacher); sd.save(student); } }
然后会生成和我给出的创建sql语句生成的相同的字段,并且外键也是可以的,如果出现异常,大家检查一下get/set/无参构造/有参构造,这里的无参构造必须存在,否则真的会异常
级联操作分级联删除、级联添加、级联更新,如果设置了级联操作就可以完成级联操作,具体的在一对一上的补充介绍了
@OneToMany(mappedBy = "teacher",cascade = CascadeType.ALL) private Set<Student> students=new HashSet<Student>();
在主表上设置了级联操作(ALL=全部都支持),只要保存teaccher就会级联着保存student
@Test //多条件查询 @Transactional @Rollback(value = false) public void testC() { //创建2个对象 Student student=new Student("李小二","男",25,666.3,"安徽六安","2020-6-6"); Teacher teacher=new Teacher(100,"王老师","男",32,6666.6,"北京顺义"); //把老师放入学生数据中 把学生数据放入老师表中 student.setTeacher(teacher); teacher.getStudents().add(student); //直接添加老师就可以保存双方数据 td.save(teacher); }
这个时候我们导入之前的sql语句,然后把配置改为update,每次执行,有表则不创建表,
@Test //多条件查询 @Transactional //必须添加事务 public void testC() { Teacher teacher = td.findOne(2); System.out.println(teacher); }
多对多是一个双向关系,我首先来展示一下SQL语句
##### 多对多 -- 删除库 drop database demo_jpa_many_many; -- 创建库 create database if not exists demo_jpa_many_many charset gbk collate gbk_chinese_ci; -- 使用库 use demo_jpa_many_many; -- 创建从表 (学生表) create table if not exists student ( sid int(11) primary key auto_increment, -- 编号 sname varchar(5) not null, -- 姓名 ssex enum(‘男‘,‘女‘) default ‘男‘, -- 性别 sage tinyint(11) unsigned not null default 20, -- 年龄 smoney decimal(4,1) default 0, -- 零花钱 最高999.9 saddress varchar(10), -- 住址 senrol date default ‘0000-00-00‘ -- 入学时间 )charset gbk; # 学生社团组织 create table if not exists organization( oid int(11) primary key auto_increment, -- 社团主键id oname varchar(10) not null unique -- 社团名称 )charset gbk; # 中间表 社团和学生对应多对多关系 create table if not exists student_organization( soid int(11) primary key auto_increment, -- 中间表id s_id int(11), -- 学生id o_id int(11), -- 社团id foreign key(s_id) references student(sid), -- 连接学生id foreign key(o_id) references organization(oid) -- 连接社团id )charset gbk; # 添加学生社团组织学习 insert into organization (oname) values ("书法协会"),("法律协会"),("武术协会"), ("魔术社团"),("网球协会"),("啦啦队团"); -- 添加学生数据 insert into student(sid,sname,saddress)values (1 ,"王生安","安徽六安"),(2 ,"李鑫灏","安徽合肥"), (3 ,"薛佛世","安徽蚌埠"),(4 ,"蔡壮保","安徽安庆"), (5 ,"钱勤堃","安徽合肥"),(6 ,"潘恩依","安徽合肥"), (7 ,"陈国柏","安徽六安"),(8 ,"魏皑虎",null); # 添加学生和社团的中间表 insert into student_organization(s_id,o_id) values (1,1),(1,3),(1,2),(1,6),(2,5),(2,1),(2,2), (6,6),(6,2),(6,4),(6,3),(7,4),(7,2);
上面多对多关系是一个学生可以加入多个社团(组织),一个组织可以有多名学生,间就构建成多对多关系,废话不多说,直接上映射关系
在创建映射关系的时候我们得确定哪一方会放弃外键维护权, 在多对多的时候我们通常放弃的被动的一方 @Entity @Table(name = "student") public class Student { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "sid") private Integer id; @Column(name = "sname") private String name; @Column(name = "ssex") private String sex; @Column(name = "sage") private Integer age; @Column(name = "smoney") private Double money; @Column(name = "saddress") private String address; @Column(name = "ssenrol") private String senrol; // @ManyToMany(targetEntity = Organization.class) // @JoinTable(name = "student_organization", // joinColumns = {@JoinColumn(name = "s_id", referencedColumnName = "sid")} , // inverseJoinColumns = {@JoinColumn(name = "o_id", referencedColumnName = "oid")} // ) @ManyToMany(mappedBy = "students") private Set<Organization> organizations = new HashSet<Organization>(); } @Entity @Table(name = "organization") public class Organization { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "oid") private Integer id; @Column(name = "oname") private String name; @ManyToMany(targetEntity = Student.class) @JoinTable(name = "student_organization", joinColumns ={@JoinColumn(name = "o_id",referencedColumnName = "oid")} , inverseJoinColumns = {@JoinColumn(name = "s_id",referencedColumnName = "sid")} ) private Set<Student> students=new HashSet<Student>(); }
@RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(locations = "classpath:applicationContext.xml") public class Client { @Autowired @Qualifier(value = "studentDao") private StudentDao sd; @Autowired @Qualifier(value = "organizationDao") private OrganizationDao od; @Test @Transactional @Rollback(value = false) public void fun() { Student student=new Student("张三","男",45,555.6,"安徽六安","2012-8-8"); Organization o=new Organization("魔术社"); student.getOrganizations().add(o); o.getStudents().add(student); od.save(o); sd.save(student); } }
在一对多查询的时候,多的一方数据会有延迟加载,但是对于一对一查询的时候数据会有立即加载
6月 03, 2020 4:57:00 下午 org.hibernate.dialect.Dialect <init> INFO: HHH000400: Using dialect: org.hibernate.dialect.MySQLDialect 省去部分... Hibernate: create table family (...) type=MyISAM //上面一局为我们创建的是一张表并设置MyISAM引擎 错误就在这 无法运行了 6月 03, 2020 4:57:01 下午 org.hibernate.tool.schema.internal.ExceptionHandlerLoggedImpl handleException WARN: GenerationTarget encountered exception accepting command : Error executing DDL "create table family (...) type=MyISAM" via JDBC Statement org.hibernate.tool.schema.spi.CommandAcceptanceException: Error executing DDL "create table family (...) type=MyISAM" via JDBC Statement //从上面错误可以看出 程序运行的时候默认的数据库方言设置了 org.hibernate.dialect.MySQLDialect 而这个默认是MyISAM引擎
问题所在:因为我导入的hibernate坐标是5.4.10.Final,在导入这类高版本的坐标往往要为数据库方言设置MySQL5InnoDBDialect的配置,在我前面也测试了,关于坐标版本问题,发现5.0.x.Final左右的版本不用设置数据库方言,默认即可。
<property name="jpaProperties"> <props> <prop key="hibernate.hbm2ddl.auto">create</prop> <!--设置数据库方言--> <prop key="hibernate.dialect">org.hibernate.dialect.MySQL5InnoDBDialect</prop> </props> </property>
具体的版本在创建数据库表的时候会抛各种异常,这里我整理了一下数据库方言,方便大家参考
<property name="jpaProperties"> <props> <prop key="hibernate.hbm2ddl.auto">create</prop> <!--设置数据库方言--> <prop key="hibernate.dialect">org.hibernate.dialect.MySQL5InnoDBDialect</prop> </props> </property> <!--数据库方言--> DB2 org.hibernate.dialect.DB2Dialect DB2 AS/400 org.hibernate.dialect.DB2400Dialect DB2 OS390 org.hibernate.dialect.DB2390Dialect PostgreSQL org.hibernate.dialect.PostgreSQLDialect MySQL org.hibernate.dialect.MySQLDialect MySQL with InnoDB org.hibernate.dialect.MySQLInnoDBDialect MySQL with MyISAM org.hibernate.dialect.MySQLMyISAMDialect Oracle (any version) org.hibernate.dialect.OracleDialect Oracle 9i/10g org.hibernate.dialect.Oracle9Dialect Sybase org.hibernate.dialect.SybaseDialect Sybase Anywhere org.hibernate.dialect.SybaseAnywhereDialect Microsoft SQL Server org.hibernate.dialect.SQLServerDialect SAP DB org.hibernate.dialect.SAPDBDialect Informix org.hibernate.dialect.InformixDialect HypersonicSQL org.hibernate.dialect.HSQLDialect Ingres org.hibernate.dialect.IngresDialect Progress org.hibernate.dialect.ProgressDialect Mckoi SQL org.hibernate.dialect.MckoiDialect Interbase org.hibernate.dialect.InterbaseDialect Pointbase org.hibernate.dialect.PointbaseDialect FrontBase org.hibernate.dialect.FrontbaseDialect Firebird org.hibernate.dialect.FirebirdDialect
WARNING: Please consider reporting this to the maintainers of org.springframework.data.projection.DefaultMethodInvokingMethodInterceptor WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations WARNING: All illegal access operations will be denied in a future release Hibernate: sql语句 java.lang.StackOverflowError at java.base/java.lang.AbstractStringBuilder.inflate(AbstractStringBuilder.java:202) at java.base/java.lang.AbstractStringBuilder.putStringAt(AbstractStringBuilder.java:1639) at java.base/java.lang.AbstractStringBuilder.append(AbstractStringBuilder.java:513) .......
关以这种错误大多都是编写的toString语句发生了错误,大家在写toString的时候一定要分清主表和从表,在编写主表的toString的时候一定要去除外键字段,而在编写从表的时候一定要加上外键字段,因为平时我们都是通过从表查询数据(因为从表有指向主表的外键),这样可以把主表的数据通过外键查询出来,但是主表上如果也有从表的字段的话就会一只循环,数据没完没了,所有抛异常也是对的,
总结一句话,从表有主表的字段,主表有从表的字段,打印从表顺带打印主表,但是主表里面还有从表字段,然后继续打印从表字段.......
org.hibernate.LazyInitializationException: failed to lazily initialize a collection of role: cn.xw.domain.Teacher.students, could not initialize proxy - no Session
at org.hibernate.collection.internal.AbstractPersistentCollection.throwLazyInitializationException(AbstractPersistentCollection.java:606)
at org.hibernate.collection.internal.AbstractPersistentCollection.withTemporarySessionIfNeeded(AbstractPersistentCollection.java:218)
at org.hibernate.collection.internal.AbstractPersistentCollection.initialize(AbstractPersistentCollection.java:585)
at org.hibernate.collection.internal.AbstractPersistentCollection.read(AbstractPersistentCollection.java:149)
at org.hibernate.collection.internal.PersistentSet.toString(PersistentSet.java:327)
at java.base/java.lang.String.valueOf(String.java:2801)
at java.base/java.lang.StringBuilder.append(StringBuilder.java:135)
关于在使用延迟加载的时候,在当前的方法上必须设置@Transactional,因为在使用延迟加载底层已经使用了事务的相关方法
标签:hide 快速 opp lang exce proxy dso 情况下 nod
原文地址:https://www.cnblogs.com/antLaddie/p/12996320.html
