标签:技巧 tmp 执行时间 机器 自我 一起 数组 有序数组 com
分而治之归并排序关注「码哥字节」设置星标,接收最新技术干货提升自我。本文完整源码详见 Github:https://github.com/UniqueDong/algorithms.git
前面我们学习了时间复杂度 O(n2) 的经典排序算法:冒泡排序、插入排序、选择排序,今天我们来学习时间复杂度为 O(nlogn) 的归并排序,这种排序思想也更加常用。
归并排序和快速排序都用到了 分治思想 。
作为一种典型的分而治之思想的算法应用,归并排序的实现由两种方法:
把数组从中间分成左右两部分,然后对左右两部分分别排序,再将排序号的两部分合并在一起,最后整个序列有序。其实就是运用了分治思想,顾名思义,就是分而治之,将一个大问题分解成小的子问题。
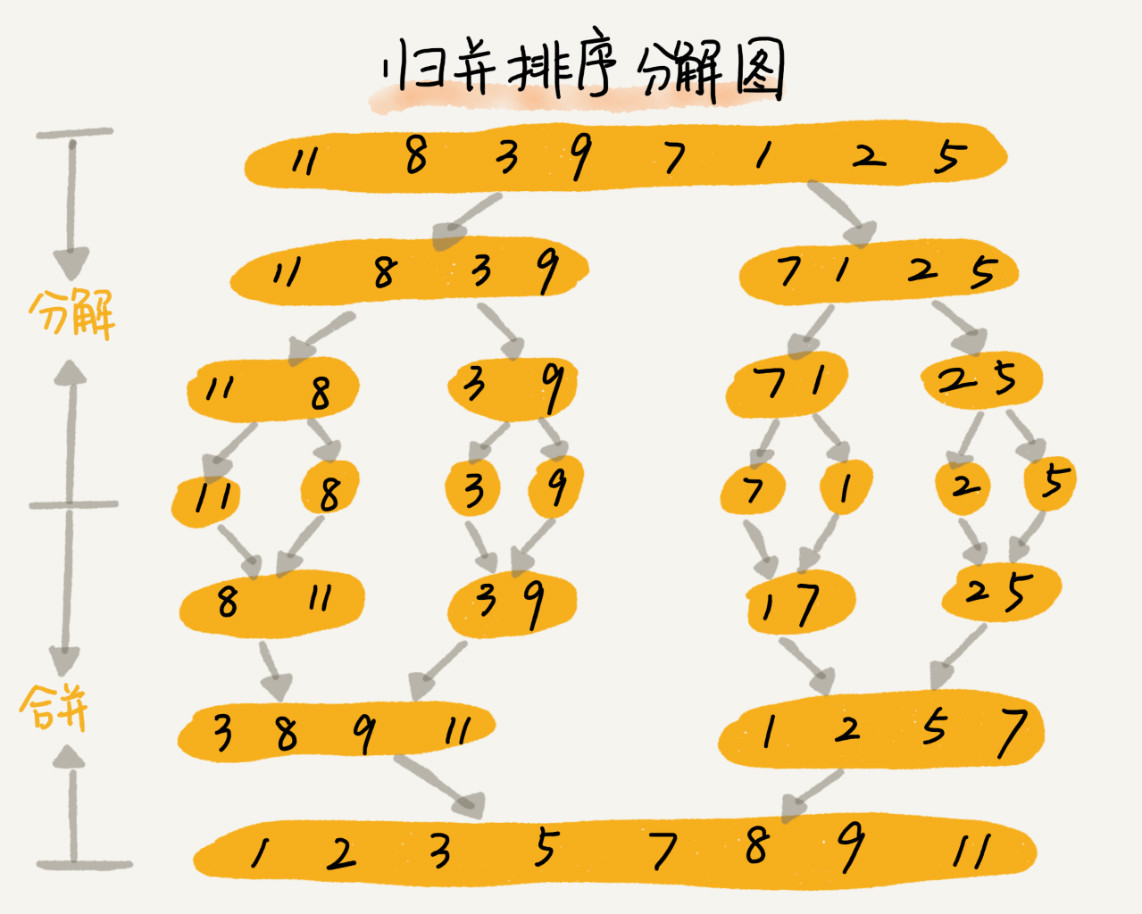
是不是跟递归很像,分治一般都是用递归来实现。分治是一种解决问题的处理思想,递归是一种编程技巧。
之前我们在 递归 篇说过,递归代码的技巧就是分析递推公式,找出终止条件,然后把递推公式翻译代码。
递推公式:
merge_sort(p…r) = merge(merge_sort(p…q), merge_sort(q+1…r))
终止条件:
p >= r 不用再继续分解我来解释一下这个递推公式。
merge_sort(p…r) 表示,给下标从 p 到 r 之间的数组排序。我们将这个排序问题转化为了两个子问题,merge_sort(p…q) 和 merge_sort(q+1…r),其中下标 q 等于 p 和 r 的中间位置,也就是 (p+r)/2。当下标从 p 到 q 和从 q+1 到 r 这两个子数组都排好序之后,我们再将两个有序的子数组合并在一起,这样下标从 p 到 r 之间的数据就也排好序了。
public static void mergeSort(int[] arr) {
sort(arr, 0, arr.length - 1);
}
public static void sort(int[] arr, int left, int right) {
// 递归终止条件
if(left >= right) {
return;
}
// 获取 left right 之间的中间位置
int mid = left + ((right - left) >> 1);
// 分治递归
sort(arr, left, mid);
sort(arr, mid + 1, right);
merge(arr, left, mid, right);
}
// 合并数据
public static void merge(int[] arr, int left, int mid, int right) {
int[] temp = new int[right - left + 1];
int i = 0;
int p1 = left;
int p2 = mid + 1;
// 比较左右两部分的元素,哪个小,把那个元素填入temp中
while(p1 <= mid && p2 <= right) {
temp[i++] = arr[p1] < arr[p2] ? arr[p1++] : arr[p2++];
}
// 上面的循环退出后,把剩余的元素依次填入到temp中
// 以下两个while只有一个会执行
while(p1 <= mid) {
temp[i++] = arr[p1++];
}
while(p2 <= right) {
temp[i++] = arr[p2++];
}
// 把最终的排序的结果复制给原数组
for(i = 0; i < temp.length; i++) {
arr[left + i] = temp[i];
}
}第一,归并排序是稳定的排序算法吗?
你应该能发现,归并排序稳不稳定关键要看 merge() 函数,也就是两个有序子数组合并成一个有序数组的那部分代码。
在合并的过程中,如果 A[left…mid] 和 A[mid+1…right] 之间有值相同的元素,那我们可以像伪代码中那样,先把 A[left…mid] 中的元素放入 tmp 数组。这样就保证了值相同的元素,在合并前后的先后顺序不变。所以,归并排序是一个稳定的排序算法。
第二,归并排序的时间复杂度是多少?
归并排序涉及递归,时间复杂度的分析稍微有点复杂。我们正好借此机会来学习一下,如何分析递归代码的时间复杂度。
在递归那一节我们讲过,递归的适用场景是,一个问题 a 可以分解为多个子问题 b、c,那求解问题 a 就可以分解为求解问题 b、c。问题 b、c 解决之后,我们再把 b、c 的结果合并成 a 的结果。
如果我们定义求解问题 a 的时间是 T(a),求解问题 b、c 的时间分别是 T(b) 和 T( c),那我们就可以得到这样的递推关系式:其中 K 等于将两个子问题 b、c 的结果合并成问题 a 的结果所消耗的时间。
T(a) = T(b) + T(c) + K
我们可以得到一个重要的结论:不仅递归求解的问题可以写成递推公式,递归代码的时间复杂度也可以写成递推公式。
我们假设对 n 个元素进行归并排序需要的时间是 T(n),那分解成两个子数组排序的时间都是 T(n/2)。我们知道,merge() 函数合并两个有序子数组的时间复杂度是 O(n)。所以,套用前面的公式,归并排序的时间复杂度的计算公式就是:
T(1) = C; n=1 时,只需要常量级的执行时间,所以表示为 C。
T(n) = 2*T(n/2) + n; n>1通过这个公式,如何来求解 T(n) 呢?还不够直观?那我们再进一步分解一下计算过程。
T(n) = 2*T(n/2) + n
= 2*(2*T(n/4) + n/2) + n = 4*T(n/4) + 2*n
= 4*(2*T(n/8) + n/4) + 2*n = 8*T(n/8) + 3*n
= 8*(2*T(n/16) + n/8) + 3*n = 16*T(n/16) + 4*n
......
= 2^k * T(n/2^k) + k * n
......
通过这样一步一步分解推导,我们可以得到 T(n) = 2^kT(n/2^k)+kn。当 T(n/2^k)=T(1) 时,也就是 n/2^k=1,我们得到 k=log2n 。我们将 k 值代入上面的公式,得到 T(n)=Cn+nlog2n 。如果我们用大 O 标记法来表示的话,T(n) 就等于 O(nlogn)。所以归并排序的时间复杂度是 O(nlogn), 不管是最好情况、最坏情况,还是平均情况,时间复杂度都是 O(nlogn)。
第三,归并排序的空间复杂度是多少?
归并排序的时间复杂度任何情况下都是 O(nlogn),看起来非常优秀。(待会儿你会发现,即便是快速排序,最坏情况下,时间复杂度也是 O(n2)。)但是,归并排序并没有像快排那样,应用广泛,这是为什么呢?因为它有一个致命的“弱点”,那就是归并排序不是原地排序算法。
这是因为归并排序的合并函数,在合并两个有序数组为一个有序数组时,需要借助额外的存储空间。
实际上,递归代码的空间复杂度并不能像时间复杂度那样累加。刚刚我们忘记了最重要的一点,那就是,尽管每次合并操作都需要申请额外的内存空间,但在合并完成之后,临时开辟的内存空间就被释放掉了。在任意时刻,CPU 只会有一个函数在执行,也就只会有一个临时的内存空间在使用。临时内存空间最大也不会超过 n 个数据的大小,所以空间复杂度是 O(n)。
现在你有 10 个接口访问日志文件,每个日志文件大小约 300MB,每个文件里的日志都是按照时间戳从小到大排序的。你希望将这 10 个较小的日志文件,合并为 1 个日志文件,合并之后的日志仍然按照时间戳从小到大排列。如果处理上述排序任务的机器内存只有 1GB,你有什么好的解决思路,能“快速”地将这 10 个日志文件合并吗?
回台回复:日志排序,即可获取答案哦。
后台回复「加群」加入技术群获取更多成长,最新内容一手掌握

标签:技巧 tmp 执行时间 机器 自我 一起 数组 有序数组 com
原文地址:https://blog.51cto.com/14745561/2501521