标签:extend 需要 tps 数据库程序 用户 问题 覆盖 子类 核心
@
异常机制己经成为判断一门编程语言是否成熟的标准,除传统的像 C 语言没有提供异常机制之外,目前主流的编程语言如 Java、 C# 、 Ruby、 Python 等都提供了成熟的异常机制 。 异常机制可以使程序中的异常处理代码和正常业务代码分离 ,保证程序代码更加优雅,并可以提高程序的健壮性 。
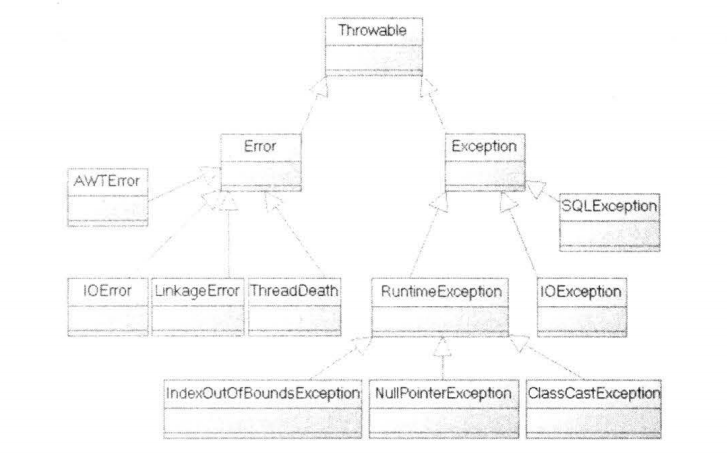
在 Java 程序设计语言中, 异常对象都是派生于 Throwable 类的一个实例。
图 一 是 Java 异常层次结构的一个简化示意图。

需要注意的是,所有的异常都是由 Throwable 继承而来,但在下一层立即分解为两个分支:Error 和 Exception:
Error 类层次结构描述了 Java 运行时系统的内部错误和资源耗尽错误。 应用程序不应该抛出这种类型的对象。 如果出现了这样的内部错误, 除了通告给用户,并尽力使程序安全地终止之外, 再也无能为力了。这种情况很少出现。
在设计 Java 程序时, 需要关注 Exception 层次结构。 这个层次结构又分解为两个分支:
Checked异常和 Runtime 异常 (运行时异常) 。 所有的 RuntimeException类及其子类的实例被称为 Runtime 异常:不是 RuntimeException 类及其子类的异常实例则被称为Checked 异常 。
只有 Java 语言提供了 Checked 异常,其他语言都没有提供 Checked 异常 。 Java 认为 Checked 异常都是可以被处理(修复〉的异常,所以 Java 程序必须显式处理 Checked 异常 。 如果程序没有处理 Checked异常,该程序在编译时就会发生错误,无法通过编译。
Checked 异常体现了 Java 的设计哲学一一没有完善错误处理的代码根本就不会被执行 !
Java 语言规范将派生于Error 类 或 RuntimeException 类的所有异常称为非受检( unchecked ) 异常,所有其他的异常称为受检( checked) 异常。 编译器将核查是否为所有的受査异常提供了异常处理器。
要想捕获一个异常, 必须设置 try/catch语句块。最简单的 try语句块如下所示:
try{
// 业务实现代码
}catch (Exception e){
alert 输入不合法
goto retry
}
如果在 try语句块中的任何代码抛出了一个在 catch 子句中说明的异常类, 那么:
如果在 try 语句块中的代码没有拋出任何异常,那么程序将跳过 catch 子句。
如果方法中的任何代码拋出了一个在 catch 子句中没有声明的异常类型,那么这个方法就会立刻退出(希望调用者为这种类型的异常设记了catch 子句。
如下是一个典型的捕获异常示例:
public void read(String filename) {
try{
InputStream in = new Filei叩utStream(filename);
int b;
while ((b = in.read()3 != -1) {
process input
}
}catch (IOException exception) {
exception.printStackTrace();
}
在一个 try 语句块中可以捕获多个异常类型,并对不同类型的异常做出不同的处理。可以按照下列方式为每个异常类型使用一个单独的 catch 子句:
try{
code that might throwexceptions
}catch (FileNotFoundException e) {
emergencyactionfor missingfiles
}catch (UnknownHostException e) {
emergency actionfor unknown hosts
}catch (IOException e) {
emergencyactionfor all other I/O problems
}
异常对象可能包含与异常本身有关的信息。要想获得异常对象的更多信息, 可以使用以下几个方法:
可以使用
e.getClass().getName()
得到异常对象的实际类型。
在 Java SE 7中,同一个 catch 子句中可以捕获多个异常类型。例如,假设对应缺少文件和未知主机异常的动作是一样的,就可以合并 catch 子句:
try{
code that might throw exceptions
}catch (FileNotFoundException | UnknownHostException e) {
emergency action for missing files and unknown hosts
}catch (IOException e) {
emergency action for all other I/O problems
}
使用一个 catch 块捕获多种类型的异常时需要注意如下两个地方 :
当代码抛出一个异常时, 就会终止方法中剩余代码的处理,并退出这个方法的执行。如果方法获得了一些本地资源,并且只有这个方法自己知道,又如果这些资源在退出方法之前必须被回收,那么就会产生资源回收问题。一种解决方案是捕获并重新抛出所有的异常,这种解决方案并不完美,这是因为需要在两个地方清除所分配的资源。一个在正常的代码中;另一个在异常代码中。
Java 有一种更好的解决方案,这就是 finally 子句。下面将介绍 Java 中如何恰当地关闭一个文件。如果使用 Java 编写数据库程序,就需要使用同样的技术关闭与数据库的连接。当发生异常时,关闭所有数据库的连接是非常重要的。不管是否有异常被捕获,finally 子句中的代码都被执行。在下面的示例中, 程序将在所
有情况下关闭文件:
InputStream in = new FileInputStream(. . .);
try{
code that might throwexceptions
}catch (IOException e) { // 3
showerror message
// 4
}finally{ // 5
in.close();
}
在上面这段代码中,有下列 3 种情况会执行 finally 子句:
1 ) 代码没有抛出异常。 在这种情况下, 程序首先执行 try 语句块中的全部代码,然后执行 finally 子句中的代码t 随后, 继续执行 try 语句块之后的第一条语句。也就是说,执行标注的 1、 2、 5、 6 处。
2 ) 抛出一个在 catch 子句中捕获的异常。在上面的示例中就是 IOException 异常。在这种情况下,程序将执行 try语句块中的所有代码,直到发生异常为止。此时,将跳过 try语句块中的剩余代码,转去执行与该异常匹配的 catch 子句中的代码, 最后执行 finally 子句中的代码。如果 catch 子句没有抛出异常,程序将执行 try 语句块之后的第一条语句。在这里,执行标注 1、 3、 4、5、 6 处的语句。如果 catch 子句抛出了一个异常, 异常将被抛回这个方法的调用者。在这里, 执行标注1、 3、 5 处的语句。
3 ) 代码抛出了一个异常, 但这个异常不是由 catch 子句捕获的。在这种情况下,程序将执行 try 语句块中的所有语句,直到有异常被抛出为止。此时, 将跳过 try 语句块中的剩余代码, 然后执行 finally 子句中的语句, 并将异常抛给这个方法的调用者。在这里, 执行标注 1、 5 处的语句。
try 语句可以只有 finally 子句,而没有 catch 子句。例如,下面这条 try 语句:
InputStream in = . .
try{
code that might throwexceptions
}finally{
in.close();
}
警告:当 finally 子句包含 return 语句时, 将会出现一种意想不到的结果? 假设利用 return语句从 try语句块中退出。在方法返回 前,finally 子句的内容将被执行。如果 finally 子句中也有一个 return 语句,这个返回值将会覆盖原始的返回值。如:
public static int f(int n) {
? try{
? int r = n * n;
? return r;
? }finally{
? if (n = 2) return 0;
? }
? }
如果调用 f(2), 那么 try 语句块的计算结果为 r = 4, 并执行 return 语句然而,在方法真正返回前,还要执行 finally 子句。finally 子句将使得方法返回 0, 这个返回值覆盖了原始的返回值 4
使用throws声明抛出异常的思路是:当前方法不知道如何处理这种类型的异常,该异常应该由上一级调用者处理;如果main方法也不知道如何处理该类型的异常,也可以使用throws声明抛出异常,该异常交给JVM处理,JVM对异常的处理方法是:打印异常的跟踪栈信息,并终止程序运行。
throws只能在方法签名中使用,throws可以声明抛出多个异常类,多个异常类之间以逗号隔开:
throws ExceptionClass1,ExceptionClass2 …………
public class ThrowsTest{
public static void main(String[] args) throws Exception{
// 因为test()方法声明抛出IOException异常,
// 所以调用该方法的代码要么处于try...catch块中,
// 要么处于另一个带throws声明抛出的方法中。
test();
}
public static void test()throws IOException{
// 因为FileInputStream的构造器声明抛出IOException异常,
// 所以调用FileInputStream的代码要么处于try...catch块中,
// 要么处于另一个带throws声明抛出的方法中。
FileInputStream fis = new FileInputStream("a.txt");
}
}
如果需要在程序中自行抛出异常,则应使用 throw 语句。throw 吾句可以单独使用,throw 语句抛出的不是异常类,而是一个异常实例,而且每次只能抛出一个异常实 throw 语句的语法格式如下:
throw ExceptionInstance ;
public class ThrowTest{
public static void main(String[] args){
try{
// 调用声明抛出Checked异常的方法,要么显式捕获该异常
// 要么在main方法中再次声明抛出
throwChecked(-3);
}catch (Exception e){
System.out.println(e.getMessage());
}
// 调用声明抛出Runtime异常的方法既可以显式捕获该异常,
// 也可不理会该异常
throwRuntime(3);
}
public static void throwChecked(int a)throws Exception{
if (a > 0){
// 自行抛出Exception异常
// 该代码必须处于try块里,或处于带throws声明的方法中
throw new Exception("a的值大于0,不符合要求");
}
}
public static void throwRuntime(int a){
if (a > 0){
// 自行抛出RuntimeException异常,既可以显式捕获该异常
// 也可完全不理会该异常,把该异常交给该方法调用者处理
throw new RuntimeException("a的值大于0,不符合要求");
}
}
}
在程序中,可能会遇到任何标准异常类都没有能够充分地描述清楚的问题。 在这种情况下,可以自定义异常类。
是定义一个派生于Exception 的类,或者派生于 Exception 子类的类。例如, 定义一个派生于 IOException 的类。
习惯上, 定义的类应该包含两个构造器, 一个是默认的构造器;另一个是带有详细描述信息的构造器(超类 Throwable 的 toString 方法将会打印出这些详细信息, 这在调试中非常有用)。
class FileFormatException extends IOException{
public FileFormatExceptionO {}
public FileFormatException(String gripe) {
super(gripe);
}
接下来,就可以抛出自定义的异常类型:
String readData(BufferedReader in) throws FileFormatException{
while (. . .) {
if (ch == -1){ // EOF encountered
if (n < len){
throw new FileFornatException();
}
}
}
对于真实的企业级应用而言,常常有严格的分层关系,层与层之间有非常清晰的划分,上层功能的实现严格依赖于下 API,也不会跨层访问:
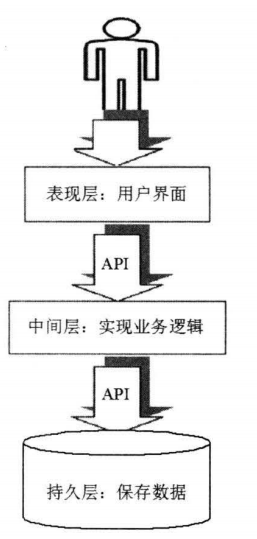 当业务逻辑层访问持久层出现
当业务逻辑层访问持久层出现把底层的原始异常直接传给用户是一种不负责任的表现。 通常的做法是:程序先捕获原始异常, 然后抛出一个新的业务异常, 新的业务异常中包含了对用户的提示信息, 这种处理方式被称为异常转译。 假设程序需要实现工资计算的方法,
则程序应该采用如下结构的代码来实现该方法:
public void calSal() throws SalException{
try{
// 实现结算工资的业务逻辑
}catch(SQLException sqle){
// 把原始异常记录下来, 留给管理员
// 下面异常中的 message 就是对用户的提示
throw new SalException("访问底层数据库出现异常");
} catch(Exception e)
// 把原始异常记录下来, 留给管理员
// 下面异常中的 message 就是对用户的提示
throw new SalException( "系统出现未知异常");
}
}
异常对象的 printStackTrace()方法用于打印异常的跟踪栈信息, 根据 printStackTrace()方法的输出结果, 开发者可以找到异常的源头, 并跟踪到异常一路触发的过程。
class SelfException extends RuntimeException
{
SelfException(){}
SelfException(String msg)
{
super(msg);
}
}
public class PrintStackTraceTest
{
public static void main(String[] args)
{
firstMethod();
}
public static void firstMethod()
{
secondMethod();
}
public static void secondMethod()
{
thirdMethod();
}
public static void thirdMethod()
{
throw new SelfException("自定义异常信息");
}
}
运行结果:

异常从thirdMethod方法开始触发 , 传到 secondMethod 方法,再传到firstMethod 方法, 最后传到 main 方法, 在 main 方法终止, 这个过程就是 Java 的异常跟踪栈。
面向对象的应用程序运行时, 经常会发生一系列方法调用, 从而形成“ 方法调用栈”, 异常的传播则相反: 只要异常没有被完全捕获( 包括异常没有被捕获, 或异常被处理后重新抛出了新异常),异常从发生异常的方法逐渐向外传播, 首先传给该方法的调用者, 该方法调用者再次传给其调用者……直至最后传到 main 方法, 如果 main 方法依然没有处理该异常, JVM 会中止该程序, 并打印异常的跟踪栈信息。
图中所示的异常跟踪栈信息非常清晰——它记录了应用程序中执行停止的各个点:
第一行的信息详细显示了异常的类型和异常的详细消息。
接下来跟踪栈记录程序中所有的异常发生点, 各行显示被调用方法中执行的停止位置, 并标明类、类中的方法名、 与故障点对应的文件的行。
一行行地往下看, 跟踪栈总是最内部的被调用方法逐渐上传,直到最外部业务操作的起点, 通常就是程序的入口 main 方法或 Thread 类的 rim 方法( 多线程的情形)。
下面给出使用异常机制的几个技巧:
作为一个示例, 在这里编写了一段代码, 试着上百万次地对一个空栈进行退栈操作。在实施退栈操作之前, 首先要查看栈是否为空。
if (!s.empty()) s.popO;
接下来,强行进行退栈操作。然后, 捕获 EmptyStackException 异常来告知我们不能这样做。
try{
s.pop();
}catch (EmptyStackException e) {
}
在测试的机器上, 调用 isEmpty 的版本运行时间为 646 毫秒。捕获 EmptyStackException 的版本运行时间为 21 739 毫秒。
可以看出,与执行简单的测试相比, 捕获异常所花费的时间大大超过了前者, 因此使用异常的基本规则是:只在异常情况下使用异常机制。
很多程序员习惯将每一条语句都分装在一个独立的 try语句块中。
PrintStream out;
Stack s;
for (i = 0;i < 100; i++) {
try
{ n = s.pop(); }
catch (EmptyStackException e) {
II stack was empty
}
try
{
out.writelnt(n); }
catch (IOException e) {
ff problem writing to file
} }
这种编程方式将导致代码量的急剧膨胀。首先看一下这段代码所完成的任务。在这里,希望从栈中弹出 100 个数值, 然后将它们存人一个文件中。如果栈是空的, 则不会变成非空状态;如果文件出现错误, 则也很难给予排除。出现上述问题后,这种编程方式无能为力。因此,有必要将整个任务包装在一个 try语句块中,这样, 当任何一个操作出现问题时, 整个任务都可以取消。
try
{
for (i = 0; i < 100; i++) { n = s.popO ;
out.writelnt(n); } }
catch (IOException e) { // problem writing to file
}
catch (EmptyStackException e) { f] stack was empty
}
这段代码看起来清晰多了。这样也满足了异常处理机制的其中一个目标,将正常处理与错误处理分开。
不要只抛出 RuntimeException 异常。应该寻找更加适当的子类或创建自己的异常类。不要只捕获 Thowable 异常, 否则,会使程序代码更难读、 更难维护。
考虑受查异常与非受查异常的区别。 已检查异常本来就很庞大,不要为逻辑错误抛出这些异常。(例如, 反射库的做法就不正确。 调用者却经常需要捕获那些早已知道不可能发生的异常。)
将一种异常转换成另一种更加适合的异常时不要犹豫。例如, 在解析某个文件中
的 一 个 整 数 时, 捕 获 NumberFormatException 异 常, 然 后 将 它 转 换 成 IOException 或MySubsystemException 的子类。
在 Java 中,往往强烈地倾向关闭异常。如果编写了一个调用另一个方法的方法,而这个方法有可能 100 年才抛出一个异常, 那么, 编译器会因为没有将这个异常列在 throws 表中产生抱怨。而没有将这个异常列在 throws 表中主要出于编译器将会对所有调用这个方法的方法进行异常处理的考虑。因此,应该将这个异常关闭:
public Image loadImage(String s) {
try
{ // code that threatens to throw checked exceptions
}
catch (Exception e) {} // so there
}
现在,这段代码就可以通过编译了。除非发生异常,否则它将可以正常地运行。即使发生了异常也会被忽略。如果认为异常非常重要,就应该对它们进行处理。
当检测到错误的时候, 有些程序员担心抛出异常。在用无效的参数调用一个方法时,返回一个虚拟的数值, 还是抛出一个异常, 哪种处理方式更好? 例如, 当栈空时,Stack.pop 是返回一个 null, 还是抛出一个异常? 我们认为:在出错的地方抛出一个 EmptyStackException异常要比在后面抛出一个NullPointerException 异常更好。
很多程序员都感觉应该捕获抛出的全部异常。如果调用了一个抛出异常的方法,例如,FilelnputStream 构造器或 readLine 方法,这些方法就会本能地捕获这些可能产生的异常。其 实, 传递异常要比捕获这些异常更好:
public void readStuff(String filename) throws IOException // not a sign of shame! {
InputStreaa in = new FilelnputStream(filename);
……
}
让高层次的方法通知用户发生了错误, 或者放弃不成功的命令更加适宜。
规则 5、6 可以归纳为“早抛出,晚捕获"
参考:
【1】:《Java核心技术 卷一》
【2】:《疯狂Java讲义》
标签:extend 需要 tps 数据库程序 用户 问题 覆盖 子类 核心
原文地址:https://www.cnblogs.com/three-fighter/p/13053052.html