标签:efi reset array cpu tutorials inf enc max port
API。训练神经网络需要很多步骤。需要指定如何输入训练数据、初始化模型参数、在网络中执行向前和向后传递、基于计算的梯度更新权重、执行模型检查点等。在预测过程中,最终会重复这些步骤中的大多数步骤。对于新手和有经验的开发人员来说,所有这些都是非常令人望而生畏的。
幸运的是,MXNet在module(简称mod)包中模块化了用于训练和推理的常用代码。Module提供了用于执行预定义网络的高级和中级接口。两个接口都可以互换使用。在本教程中,我们将展示这两个接口的用法。
首先是一个初级用法demo:
import logging import random logging.getLogger().setLevel(logging.INFO) import mxnet as mx import numpy as np mx.random.seed(1234) np.random.seed(1234) random.seed(1234) fname = mx.test_utils.download(‘https://s3.us-east-2.amazonaws.com/mxnet-public/letter_recognition/letter-recognition.data‘) data = np.genfromtxt(fname, delimiter=‘,‘)[:,1:] label = np.array([ord(l.split(‘,‘)[0])-ord(‘A‘) for l in open(fname, ‘r‘)]) batch_size = 32 ntrain = int(data.shape[0]*0.8) train_iter = mx.io.NDArrayIter(data[:ntrain, :], label[:ntrain], batch_size, shuffle=True) val_iter = mx.io.NDArrayIter(data[ntrain:, :], label[ntrain:], batch_size)
网络定义,利用Symbol:
net = mx.sym.Variable(‘data‘) net = mx.sym.FullyConnected(net, name=‘fc1‘, num_hidden=64) net = mx.sym.Activation(net, name=‘relu1‘, act_type="relu") net = mx.sym.FullyConnected(net, name=‘fc2‘, num_hidden=26) net = mx.sym.SoftmaxOutput(net, name=‘softmax‘) mx.viz.plot_network(net, node_attrs={"shape":"oval","fixedsize":"false"})
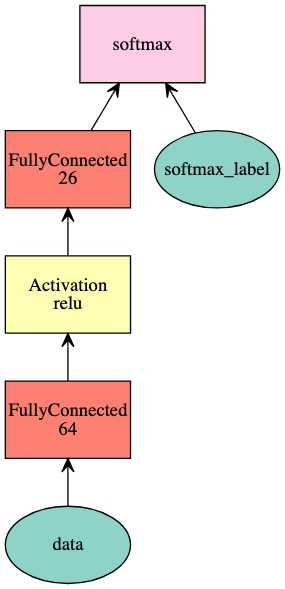
利用Module类来引入模块,可以通过指定一下参数来构建:
对于上面我们定义好的net,仅仅有一个data,且名字为data,仅有一个label被自动命名为softmax_label,这是根据我们在softmaxoutput里的名字softmax来决定的。
mod = mx.mod.Module(symbol=net, context=mx.cpu(), data_names=[‘data‘], label_names=[‘softmax_label‘])
我们已经创建了模块。现在让我们看看如何使用模块的中级api运行训练和推理。这些api通过向前和向后运行传递,使开发人员能够灵活地执行逐步计算。它对调试也很有用。为了训练一个module,需要实现以下几个步骤:
具体实现如下:
# allocate memory given the input data and label shapes mod.bind(data_shapes=train_iter.provide_data, label_shapes=train_iter.provide_label) # initialize parameters by uniform random numbers mod.init_params(initializer=mx.init.Uniform(scale=.1)) # mxnet.initializer # use SGD with learning rate 0.1 to train mod.init_optimizer(optimizer=‘sgd‘, optimizer_params=((‘learning_rate‘, 0.1), )) # mxnet.optimiazer # use accuracy as the metric metric = mx.metric.create(‘acc‘) # mxnet.mxtric # train 5 epochs, i.e. going over the data iter one pass for epoch in range(5): train_iter.reset() # 重新迭代 metric.reset() # 重新评估 for batch in train_iter: mod.forward(batch, is_train=True) # compute predictions 前向 mod.update_metric(metric, batch.label) # accumulate prediction accuracy 计算评估指标 mod.backward() # compute gradients # 反向 mod.update() # update parameters # 更新参数 print(‘Epoch %d, Training %s‘ % (epoch, metric.get()))
注意module.bind和symbol.bind不一样。
注意:mxnet里有很多缩写: mx.symbol=mx.sys; mx.initializer=mx.init; mx.module=mx.mod
Epoch 0, Training (‘accuracy‘, 0.434625) Epoch 1, Training (‘accuracy‘, 0.6516875) Epoch 2, Training (‘accuracy‘, 0.6968125) Epoch 3, Training (‘accuracy‘, 0.7273125) Epoch 4, Training (‘accuracy‘, 0.7575625)
上一节利用的是中级API,所以步骤比较多,这一节利用高阶API中的 fit 函数来实现。
1. 训练
# reset train_iter to the beginning 重置迭代器 train_iter.reset() # create a module mod = mx.mod.Module(symbol=net, # 建立module context=mx.cpu(), data_names=[‘data‘], label_names=[‘softmax_label‘]) # fit the module # 训练 mod.fit(train_iter, eval_data=val_iter, optimizer=‘sgd‘, optimizer_params={‘learning_rate‘:0.1}, eval_metric=‘acc‘, num_epoch=7)
INFO:root:Epoch[0] Train-accuracy=0.325437 INFO:root:Epoch[0] Time cost=0.550 INFO:root:Epoch[0] Validation-accuracy=0.568500 INFO:root:Epoch[1] Train-accuracy=0.622188 INFO:root:Epoch[1] Time cost=0.552 INFO:root:Epoch[1] Validation-accuracy=0.656500 INFO:root:Epoch[2] Train-accuracy=0.694375 INFO:root:Epoch[2] Time cost=0.566 INFO:root:Epoch[2] Validation-accuracy=0.703500 INFO:root:Epoch[3] Train-accuracy=0.732187 INFO:root:Epoch[3] Time cost=0.562 INFO:root:Epoch[3] Validation-accuracy=0.748750 INFO:root:Epoch[4] Train-accuracy=0.755375 INFO:root:Epoch[4] Time cost=0.484 INFO:root:Epoch[4] Validation-accuracy=0.761500 INFO:root:Epoch[5] Train-accuracy=0.773188 INFO:root:Epoch[5] Time cost=0.383 INFO:root:Epoch[5] Validation-accuracy=0.715000 INFO:root:Epoch[6] Train-accuracy=0.794687 INFO:root:Epoch[6] Time cost=0.378 INFO:root:Epoch[6] Validation-accuracy=0.802250
默认情况下,fit中的参数是这样的:
eval_metric set to accuracy, optimizer to sgd and optimizer_params to ((‘learning_rate‘, 0.01),).
y = mod.predict(val_iter) assert y.shape == (4000, 26)
有时候我们并不关心具体预测值是多少,只想知道在测试集上的指标如何,那么就可以调用score()函数来实现。它将会根据你提供的metric来评估:
score = mod.score(val_iter, [‘acc‘]) print("Accuracy score is %f" % (score[0][1])) assert score[0][1] > 0.76, "Achieved accuracy (%f) is less than expected (0.76)" % score[0][1]
Accuracy score is 0.802250
当然也可以利用其他指标:top_k_acc(top-k-accuracy), F1, RMSE, MSE, MAE, ce(CrossEntropy). 更多指标参见 Evaluation metric.
# construct a callback function to save checkpoints model_prefix = ‘mx_mlp‘ checkpoint = mx.callback.do_checkpoint(model_prefix) mod = mx.mod.Module(symbol=net) mod.fit(train_iter, num_epoch=5, epoch_end_callback=checkpoint) # 写到epoch_end_callback里就会每个epoch保存一次
INFO:root:Epoch[0] Train-accuracy=0.098437 INFO:root:Epoch[0] Time cost=0.421 INFO:root:Saved checkpoint to "mx_mlp-0001.params" INFO:root:Epoch[1] Train-accuracy=0.257437 INFO:root:Epoch[1] Time cost=0.520 INFO:root:Saved checkpoint to "mx_mlp-0002.params" INFO:root:Epoch[2] Train-accuracy=0.457250 INFO:root:Epoch[2] Time cost=0.562 INFO:root:Saved checkpoint to "mx_mlp-0003.params" INFO:root:Epoch[3] Train-accuracy=0.558187 INFO:root:Epoch[3] Time cost=0.434 INFO:root:Saved checkpoint to "mx_mlp-0004.params" INFO:root:Epoch[4] Train-accuracy=0.617750 INFO:root:Epoch[4] Time cost=0.414 INFO:root:Saved checkpoint to "mx_mlp-0005.params"
为了载入模型参数,可以调用load_checkpoint函数,它会将Symbol和相关的参数load进来,然后可以将载好的参数送入module中:
sym, arg_params, aux_params = mx.model.load_checkpoint(model_prefix, 3)
assert sym.tojson() == net.tojson()
# assign the loaded parameters to the module
mod.set_params(arg_params, aux_params)
如果只想导入一个保存好的模型来继续训练,就可以不用set_params()了,而直接在fit()里面传递参数。此时fit就知道了你想加载一个已有的参数而非随机初始化参数从头训练。此时也可以再设置一下begin_epoch,表明我们是接着从某个epoch训练。
mod = mx.mod.Module(symbol=sym) mod.fit(train_iter, num_epoch=21, arg_params=arg_params, aux_params=aux_params, begin_epoch=3) assert score[0][1] > 0.77, "Achieved accuracy (%f) is less than expected (0.77)" % score[0][1]
INFO:root:Epoch[3] Train-accuracy=0.555438 INFO:root:Epoch[3] Time cost=0.377 INFO:root:Epoch[4] Train-accuracy=0.616625 INFO:root:Epoch[4] Time cost=0.457 INFO:root:Epoch[5] Train-accuracy=0.658438 INFO:root:Epoch[5] Time cost=0.518 ........................................... INFO:root:Epoch[18] Train-accuracy=0.788687 INFO:root:Epoch[18] Time cost=0.532 INFO:root:Epoch[19] Train-accuracy=0.789562 INFO:root:Epoch[19] Time cost=0.531 INFO:root:Epoch[20] Train-accuracy=0.796250 INFO:root:Epoch[20] Time cost=0.531
Module - Neural network training and inference
标签:efi reset array cpu tutorials inf enc max port
原文地址:https://www.cnblogs.com/king-lps/p/13055184.html