标签:style blog http io color ar os sp for
上次说到冒泡排序
一共可以产生4种方式来产生,因为两个for循环皆可从小到大,也可从大到小
分类 排序算法
数据结构 vector、数组
最差时间复杂度 O(n^2)
最优时间复杂度 O(n)
平均时间复杂度 O(n^2)
最差空间复杂度 总共O(n),需要辅助空间O(1)//用于交换所需临时变量
冒泡排序算法的运作如下:
1、 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
2、 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
3、 针对所有的元素重复以上的步骤,除了最后一个。
4、 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
由于它的简洁,冒泡排序通常被用来对于程序设计入门的学生介绍算法的概念。
四、插入算法

一句话就是从未处理的数组(或vector)向前面处理好的数组插入,因为前面处理好的已经有一定规律
一般来说,插入排序都采用in-place在数组上实现。具体算法描述如下:
1、 从第一个元素开始,该元素可以认为已经被排序
2、 取出下一个元素,在已经排序的元素序列中从后向前扫描
3、 如果该元素(已排序)大于新元素,将该元素移到下一位置
4、 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
5、 将新元素插入到该位置后
6、 重复步骤2~5
如果比较操作的代价比交换操作大的话,可以采用二分查找法来减少比较操作的数目。该算法可以认为是插入排序的一个变种,称为二分查找排序。
如果目标是把n个元素的序列升序排列,那么采用插入排序存在最好情况和最坏情况。最好情况就是,序列已经是升序排列了,在这种情况下,需要进行的比较操作需(n-1)次即可。最坏情况就是,序列是降序排列,那么此时需要进行的比较共有n(n-1)/2次。插入排序的赋值操作是比较操作的次数减去(n-1)次。平均来说插入排序算法复杂度为O(n2)。因而,插入排序不适合对于数据量比较大的排序应用。但是,如果需要排序的数据量很小,例如,量级小于千,那么插入排序还是一个不错的选择。 插入排序在工业级库中也有着广泛的应用,在STL的sort算法和stdlib的qsort算法中,都将插入排序作为快速排序的补充,用于少量元素的排序(通常为8个或以下)。
1 #include <iostream> 2 #include <iterator> 3 #include <vector> 4 #include <ctime> 5 #include <random> 6 #include <functional> 7 #include <algorithm> 8 using namespace std; 9 int intSwap(int& a,int& b) 10 { 11 int intswaptemp=a; 12 a=b; 13 b=intswaptemp; 14 return 0; 15 } 16 /*---------------------------------------- 17 插入排序 18 从小到大 19 vector<int> 20 -----------------------------------------*/ 21 int insertionSort(vector<int> &ivec) 22 { 23 int i,j,temp; 24 for(i=1;i<=ivec.size();i++) 25 { 26 j=i-1; 27 temp=ivec[i]; 28 while((temp<ivec[j])&&(j>=0)) 29 { 30 ivec[j+1]=ivec[j]; 31 j--; 32 } 33 ivec[j+1]=temp; 34 35 } 36 return 0; 37 } 38 //照猫画猫-------->>>>上面 39 template<typename T> 40 int insertionSort_(T begin,T end) 41 { 42 typedef typename iterator_traits<T>::value_type value_type; 43 value_type key; 44 T ins=begin; 45 T j; 46 advance(ins,1); 47 while(ins!=end) 48 { 49 key=*ins; 50 j=ins; 51 T pre=j; 52 advance(j,-1); 53 while(key<*j&&pre!=begin) 54 { 55 iter_swap(pre,j); 56 advance(pre,-1); 57 advance(j,-1); 58 } 59 *pre=key; 60 advance(ins,1); 61 } 62 } 63 inline void insertSort_1(vector<int>&ivec) 64 { 65 insertionSort_(ivec.begin(),ivec.end()); 66 } 67 int main() 68 { 69 clock_t start,end; 70 vector<int> ivec,copyivec; 71 srand(14); 72 for(int i=0;i<10000;i++)//10k 73 ivec.push_back((int)rand()); 74 copyivec=ivec; 75 start=clock(); 76 insertionSort(ivec); 77 end=clock(); 78 for(int i=0;i<10000;i+=500) 79 cout<<ivec[i]<<‘\t‘; 80 cout<<endl; 81 cout<<"the time of 1 is "<<end-start<<endl; 82 start=clock(); 83 insertSort_1(copyivec); 84 end=clock(); 85 for(int i=0;i<10000;i+=500) 86 cout<<ivec[i]<<‘\t‘; 87 cout<<endl; 88 cout<<"the time of 2 is "<<end-start<<endl; 89 return 0; 90 }

可见还是比较费时。不过由于暂时还没有优化,最后比较的时候才能判断。
五、堆排序
堆排序的前提是要了解二叉树这样一种玩意。这个排序的讲解有个大神,我也是第一次学这方法。
这个地方讲解的很清楚了~(最喜欢这种无脑就可以看懂的玩意,不需要自己拿笔一点点算)http://www.cnblogs.com/dolphin0520/archive/2011/10/06/2199741.html
我的话说就是这玩意可以就是一直要记得二叉树(有规律的,而这种规律可以用来实现排序)
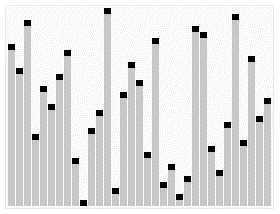 这幅图一共二种信息,第一种就是刚开始会整理,注意,最大的在第一列,这就是二叉树的顶(头,)第二种就是开始排序算法,通过实现未排序最后一个和第一个交换,然后接着形成新的二叉树(头最大),对了,感觉代码解释很少,我需要填写一些信息,第一次写,求不坑人!
这幅图一共二种信息,第一种就是刚开始会整理,注意,最大的在第一列,这就是二叉树的顶(头,)第二种就是开始排序算法,通过实现未排序最后一个和第一个交换,然后接着形成新的二叉树(头最大),对了,感觉代码解释很少,我需要填写一些信息,第一次写,求不坑人!
1 #include <iostream> 2 #include <iterator> 3 #include <vector> 4 #include <ctime> 5 #include <random> 6 #include <functional> 7 #include <algorithm> 8 using namespace std; 9 int intSwap(int& a,int& b) 10 { 11 int intswaptemp=a; 12 a=b; 13 b=intswaptemp; 14 return 0; 15 } 16 /*---------------------------------------- 17 堆构造 18 从小到大 19 para:vector<int> 、int length、int node; 20 vector<int>数据集合 21 length通过该参数,可以不需要把已找到的数据和Ivec种分离出来, 22 就像图片第二幅信息中没有红线的一些数据(一列就是一数据) 23 node该参数确定结点,根据二叉树的原理。 24 -----------------------------------------*/ 25 int buildHeap(vector<int> &ivec,int node,int length) 26 { 27 int bondnode=node;//保存node,防止修改node 28 int lchild=bondnode*2+1;//左孩子数 二叉树关系(+1为了防止从node为0导致左孩子一直为0,先左后右(二叉树)) 29 while(lchild<length) 30 { 31 //存在右孩子,且满足左小右大 32 //从二者中选出较大的并记录为lchild中保存 33 if(lchild+1<length&&ivec[lchild]<ivec[lchild+1]) 34 lchild++; 35 36 //判断node和右子数大小 37 if(ivec[bondnode]>ivec[lchild]) 38 break;//如果满足说明这个3个数或2个数已经按照逻辑关系已经排序好。 39 else// 40 { 41 intSwap(ivec[bondnode],ivec[lchild]); 42 //重置结点和左孩子 43 //这些都是二叉树的一些性质 44 bondnode=lchild;//找下一个结点 45 lchild=2*bondnode+1;//新的左子数 46 } 47 } 48 return 0; 49 } 50 /*---------------------------------------- 51 堆排序 52 从小到大 53 vector<int> 54 -----------------------------------------*/ 55 int SortHeap(vector<int> &ivec) 56 { 57 for(int i=(ivec.size())/2-1;i>=0;i--)//产生node 58 buildHeap(ivec,i,ivec.size());//构造每个小堆,从底层向高层。刚好可以减少很多次无效的循环 59 for(int j=0;j<ivec.size();j++)//排序开始了 60 { 61 intSwap(ivec[0],ivec[ivec.size()-j-1]); 62 //为0的结点发生变换 63 buildHeap(ivec,0,ivec.size()-j-1); 64 } 65 return 0; 66 } 67 int main() 68 { 69 clock_t start,end; 70 vector<int> ivec,copyivec; 71 srand(14); 72 for(int i=0;i<10000;i++)//10k 73 ivec.push_back((int)rand()); 74 copyivec=ivec; 75 start=clock(); 76 SortHeap(ivec); 77 end=clock(); 78 for(int i=0;i<10000;i+=500) 79 cout<<ivec[i]<<‘\t‘; 80 cout<<endl; 81 cout<<"the time of 1 is "<<end-start<<endl; 82 83 return 0; 84 }

堆排序其实也是一种选择排序,是一种树形选择排序。只不过直接选择排序中,为了从R[1...n]中选择最大记录,需比较n-1次,然后从 R[1...n-2]中选择最大记录需比较n-2次。事实上这n-2次比较中有很多已经在前面的n-1次比较中已经做过,而树形选择排序恰好利用树形的特 点保存了部分前面的比较结果,因此可以减少比较次数。对于n个关键字序列,最坏情况下每个节点需比较log2(n)次,因此其最坏情况下时间复杂度为 nlogn。堆排序为不稳定排序,不适合记录较少的排序。(转自上面链接作者)
通常堆是通过一维数组来实现的。在起始数组为 0 的情形中:
标签:style blog http io color ar os sp for
原文地址:http://www.cnblogs.com/cnblogs-maxlleric/p/4083898.html