标签:优化 through 委派 ima 执行 表示 优先 cep for loop
今日得到: 三人行,必有我师焉,择其善者而从之,其不善者而改之。
现在已经是2020年了,而在2010年的时候,大佬David Beazley就做了讲座讲解Python GIL的设计相关问题,10年间相信也在不断改善和优化,但是并没有将GIL从CPython中移除,可想而知,GIL已经深入CPython,难以移除。就目前来看,工作中常用的还是协程,多线程来处理高并发的I/O密集型任务。CPU密集型的大型计算可以用其他语言来实现。

In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.) ----- Global Interpreter Lock
为了防止多线程共享内存出现竞态问题,设置的防止多线程并发执行机器码的一个Mutex。
在python3.2版本之前,定义了一个tick计数器,表示当前线程在释放gil之前连续执行的多少个字节码(实际上有部分执行较快的字节码并不会被计入计数器)。如果当前的线程正在执行一个 CPU 密集型的任务, 它会在 tick 计数器到达 100 之后就释放 gil, 给其他线程一个获得 gil 的机会。
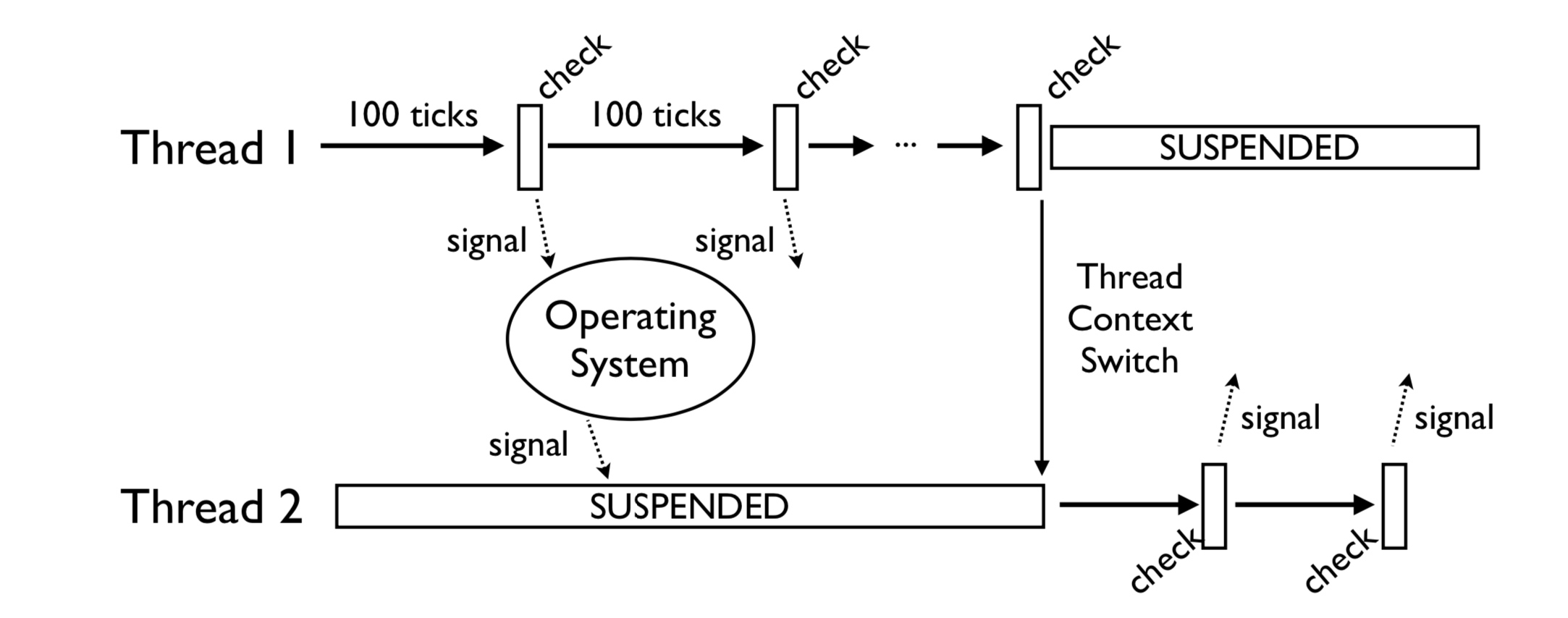
(图片来自 Understanding the Python GIL(youtube))
以opcode个数为基准来计数,如果有些opcode代码复杂耗时较长,一些耗时较短,会导致同样的100个tick,一些线程的执行时间总是执行的比另一些长。是不公平的调度策略。
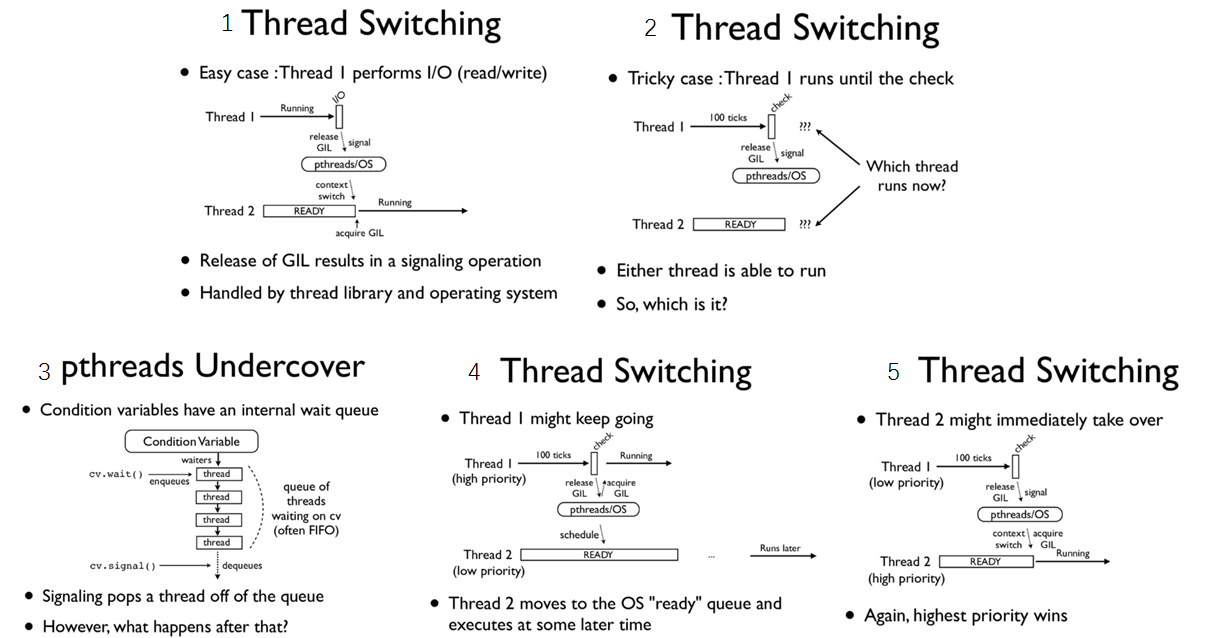
(图片来自Understanding-the-python-gil)
如果当前的线程正在执行一个 IO密集型的 的任务, 你执行 sleep/recv/send(...etc) 这些会阻塞的系统调用时, 即使 tick 计数器的值还没到 100, gil 也会被主动地释放。至于下次该执行哪一个线程这个是操作系统层面的,线程调度算法优先级调度,开发者没办法控制。
在多核机器上, 如果两个线程都在执行 CPU 密集型的任务, 操作系统有可能让这两个线程在不同的核心上运行, 也许会出现以下的情况, 当一个拥有了 gil 的线程在一个核心上执行 100 次 tick 的过程中, 在另一个核心上运行的线程频繁的进行抢占 gil, 抢占失败的循环, 导致 CPU 瞎忙影响性能。 如下图:绿色部分表示该线程在运行,且在执行有用的计算,红色部分为线程被调度唤醒,但是无法获取GIL导致无法进行有效运算等待的时间。
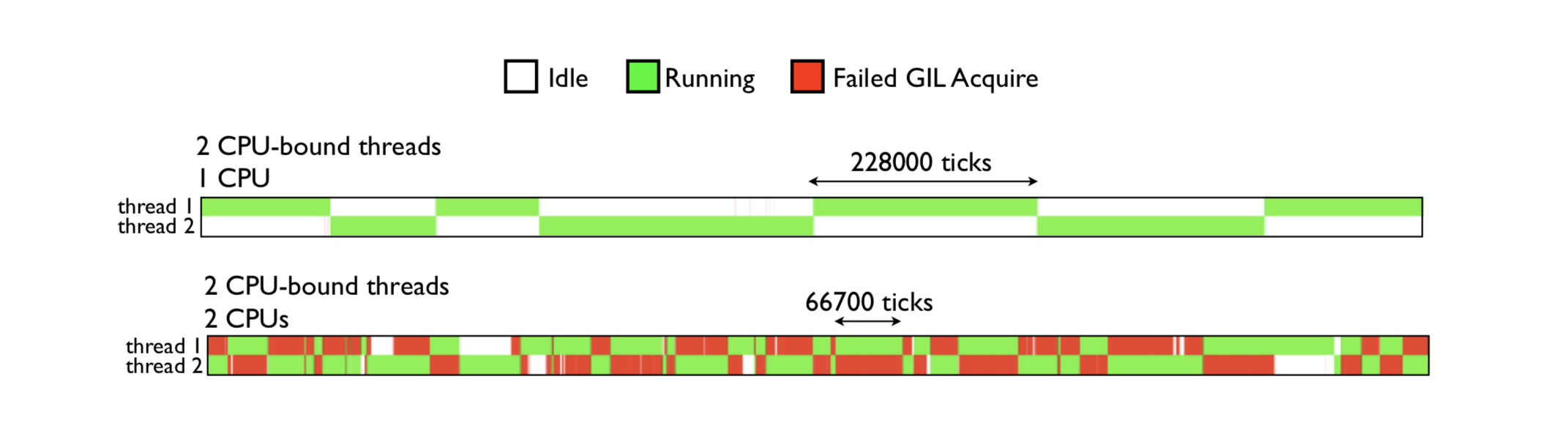
由图可见,GIL的存在导致多线程无法很好的利用多核CPU的并发处理能力。
由于在多核机器下可能导致性能下降, gil的实现在python3.2之后做了一些优化 。python在初始化解释器的时候就会初始化一个gil,并设置一个DEFAULT_INTERVAL=5000, 单位是微妙,即0.005秒(在 C 里面是用 微秒 为单位存储, 在 python 解释器中以秒来表示)这个间隔就是GIL切换的标志。
// Python\ceval_gil.h
#define DEFAULT_INTERVAL 5000
static void _gil_initialize(struct _gil_runtime_state *gil)
{
_Py_atomic_int uninitialized = {-1};
gil->locked = uninitialized;
gil->interval = DEFAULT_INTERVAL;
}
python中查看gil切换的时间
In [7]: import sys
In [8]: sys.getswitchinterval()
Out[8]: 0.005
如果当前有不止一个线程, 当前等待 gil 的线程在超过一定时间的等待后, 会把全局变量 gil_drop_request 的值设置为 1, 之后继续等待相同的时间, 这时拥有 gil 的线程看到了 gil_drop_request 变为 1, 就会主动释放 gil 并通过 condition variable 通知到在等待中的线程, 第一个被唤醒的等待中的线程会抢到 gil 并执行相应的任务, 将gil_drop_request设置为1的线程不一定能抢到gil
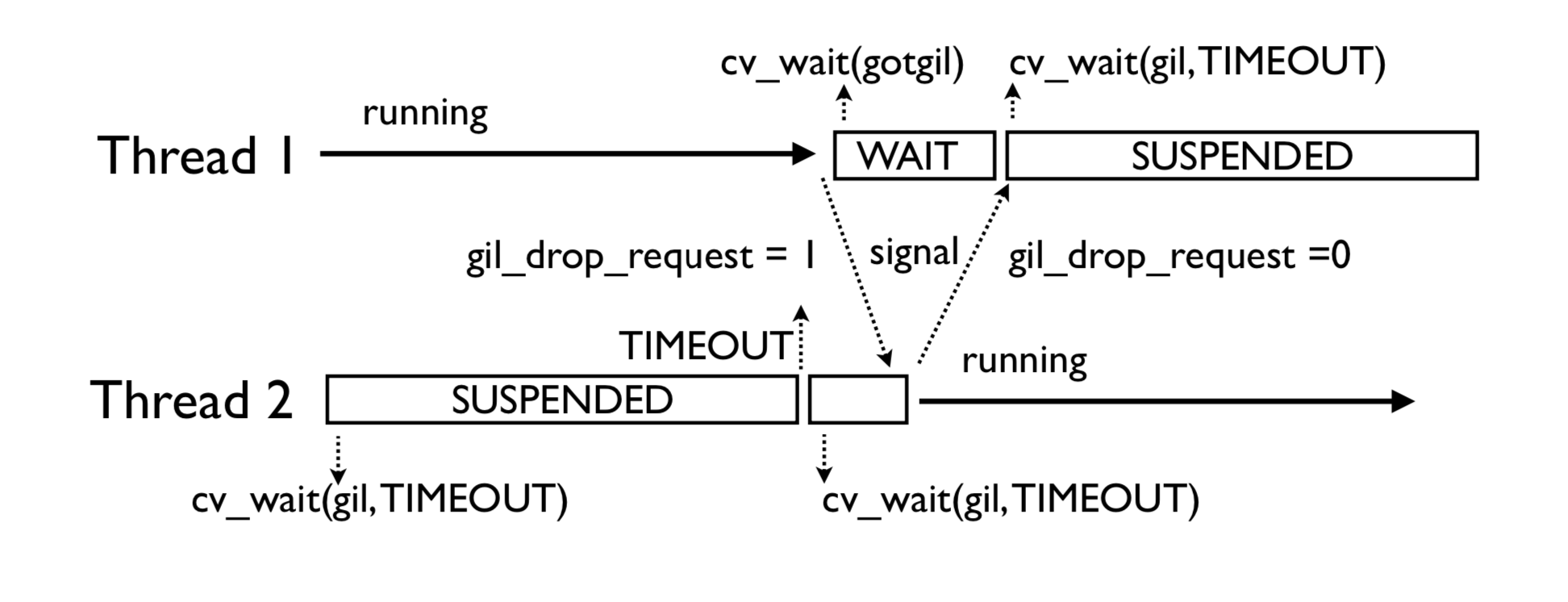
_Py_atomic_int, 值-1表示还未初始化,0表示当前的gil处于释放状态,1表示某个线程已经占用了gil,这个值的类型设置为原子类型之后在 ceval.c 就可以不加锁的对这个值进行读取。gil_drop_request这个变量之前需要等待的时长,默认是5000毫秒locked, last_holder, switch_number 还有 _gil_runtime_state 中的其他变量switch_cond 是另一个 condition variable, 和 switch_mutex 结合起来可以用来保证释放后重新获得 gil 的线程不是同一个前面释放 gil 的线程, 避免 gil 切换时线程未切换浪费 cpu 时间
这个功能如果编译时未定义 FORCE_SWITCHING 则不开启
static void
drop_gil(struct _ceval_runtime_state *ceval, PyThreadState *tstate)
{
...
#ifdef FORCE_SWITCHING
if (_Py_atomic_load_relaxed(&ceval->gil_drop_request) && tstate != NULL) {
MUTEX_LOCK(gil->switch_mutex);
/* Not switched yet => wait */
if (((PyThreadState*)_Py_atomic_load_relaxed(&gil->last_holder)) == tstate)
{
/* 如果 last_holder 是当前线程, 释放 switch_mutex 这把互斥锁, 等待 switch_cond 这个条件变量的信号 */
RESET_GIL_DROP_REQUEST(ceval);
/* NOTE: if COND_WAIT does not atomically start waiting when
releasing the mutex, another thread can run through, take
the GIL and drop it again, and reset the condition
before we even had a chance to wait for it. */
/* 注意, 如果 COND_WAIT 不在互斥锁释放后原子的启动,
另一个线程有可能会在这中间拿到 gil 并释放,
‘并且重置这个条件变量, 这个过程发生在了 COND_WAIT 之前 */
COND_WAIT(gil->switch_cond, gil->switch_mutex);
}
MUTEX_UNLOCK(gil->switch_mutex);
}
#endif
}
//
main_loop:
for (;;) {
/* 如果 gil_drop_request 被其他线程设置为 1 */
/* 给其他线程一个获得 gil 的机会 */
if (_Py_atomic_load_relaxed(&ceval->gil_drop_request)) {
/* Give another thread a chance */
if (_PyThreadState_Swap(&runtime->gilstate, NULL) != tstate) {
Py_FatalError("ceval: tstate mix-up");
}
drop_gil(ceval, tstate);
/* Other threads may run now */
take_gil(ceval, tstate);
/* Check if we should make a quick exit. */
exit_thread_if_finalizing(runtime, tstate);
if (_PyThreadState_Swap(&runtime->gilstate, tstate) != NULL) {
Py_FatalError("ceval: orphan tstate");
}
}
/* Check for asynchronous exceptions. */
/* 忽略 */
fast_next_opcode:
switch (opcode) {
case TARGET(NOP): {
FAST_DISPATCH();
}
/* 忽略 */
case TARGET(UNARY_POSITIVE): {
PyObject *value = TOP();
PyObject *res = PyNumber_Positive(value);
Py_DECREF(value);
SET_TOP(res);
if (res == NULL)
goto error;
DISPATCH();
}
/* 忽略 */
}
/* 忽略 */
}
这个很大的 for loop 会按顺序逐个的加载 opcode, 并委派给中间很大的 switch statement 去进行执行, switch statement 会根据不同的 opcode 跳转到不同的位置执行
for loop在开始位置会检查 gil_drop_request变量, 必要的时候会释放 gil
不是所有的 opcode 执行之前都会检查 gil_drop_request 的, 有一些 opcode 结束时的代码为 FAST_DISPATCH(), 这部分 opcode 会直接跳转到下一个 opcode 对应的代码的部分进行执行
而另一些 DISPATCH() 结尾的作用和 continue 类似, 会跳转到 for loop 顶端, 重新检测 gil_drop_request, 必要时释放 gil 。
GIL只会对CPU密集型的程序产生影响,规避GIL限制主要有两种常用策略:一是使用多进程,二是使用C语言扩展,把计算密集型的任务转移到C语言中,使其独立于Python,在C代码中释放GIL。当然也可以使用其他语言编译的解释器如 Jpython、PyPy。
参考
Youtube-Understanding the Python GIL
标签:优化 through 委派 ima 执行 表示 优先 cep for loop
原文地址:https://www.cnblogs.com/panlq/p/13081161.html