一、实验要求
- 以fork和execve系统调用为例分析中断上下文的切换;
- 分析execve系统调用中断上下文的特殊之处;
- 分析fork子进程启动执行时进程上下文的特殊之处;
- 以系统调用作为特殊的中断,结合中断上下文切换和进程上下文切换分析Linux系统的一般执行过程。
二、实验目的
- 总结分析Linux系统的一般执行过程;
- 对Linux系统的整体运作形成一套逻辑自洽的模型;
- 将所学的各种OS和Linux内核知识/原理融通进模型中。
三、实验环境
ubuntu-16.04.6(实验楼环境:https://www.shiyanlou.com/courses/195/learning/?id=725)
四、实验相关
1、关于fork函数系统调用
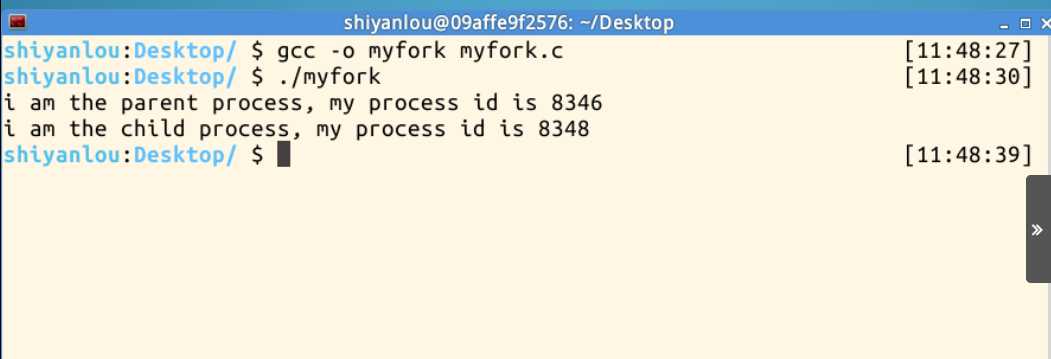
fork系统调用用于创建一个新进程,称为子进程,它与进程(称为系统调用fork的进程)同时运行,此进程称为父进程。创建新的子进程后,两个进程将执行fork()系统调用之后的下一条指令。子进程使用相同的pc(程序计数器),相同的CPU寄存器,在父进 程中使用的相同打 开文件。它不需要参数并返回一个整数值。下面是fork()返回的不同值:
负值:创建子进程失败。
零:返回到新创建的子进程。
正值:返回父进程或调电者。该值包含新创建的子进程的进程ID
#include <unistd.h> #include <stdio.h> #include <sys/types.h> int main (){ pid_t pid; pid = fork(); if (pid < 0){ printf("error in fork!\n"); } else if (pid == 0){ printf("i am the child process, my process id is %d\n",getpid()); } else{ printf("i am the parent process, my process id is %d\n",getpid()); } return 0; }
fork之后,操作系统会复制一个与父进程全然同样的子进程,虽说是父子关系,可是在操作系统看来,他们更像兄弟关系,这2个进程共享代码空间,可是数据空间是互相独立的,子进程数据空间中的内容是父进程的完整拷贝,指令指针也全然同样,但仅仅有一点不同,假设fork成功, 子进程中fork的返回值是0,父进程中fork的返回值是子进程的进程号,假设fork不成功,父进程会返回错误。
函数原型
long do_fork(unsigned long clone_flags, unsigned long stack_start, unsigned long stack_size, int __user *parent_tidptr, int __user *child_tidptr) { struct task_struct *p; int trace = 0; long nr; /* * Determine whether and which event to report to ptracer. When * called from kernel_thread or CLONE_UNTRACED is explicitly * requested, no event is reported; otherwise, report if the event * for the type of forking is enabled. */ if (!(clone_flags & CLONE_UNTRACED)) { if (clone_flags & CLONE_VFORK) trace = PTRACE_EVENT_VFORK; else if ((clone_flags & CSIGNAL) != SIGCHLD) trace = PTRACE_EVENT_CLONE; else trace = PTRACE_EVENT_FORK; if (likely(!ptrace_event_enabled(current, trace))) trace = 0; } p = copy_process(clone_flags, stack_start, stack_size, child_tidptr, NULL, trace); /* * Do this prior waking up the new thread - the thread pointer * might get invalid after that point, if the thread exits quickly. */ if (!IS_ERR(p)) { struct completion vfork; struct pid *pid; trace_sched_process_fork(current, p); pid = get_task_pid(p, PIDTYPE_PID); nr = pid_vnr(pid); if (clone_flags & CLONE_PARENT_SETTID) put_user(nr, parent_tidptr); if (clone_flags & CLONE_VFORK) { p->vfork_done = &vfork; init_completion(&vfork); get_task_struct(p); } wake_up_new_task(p); /* forking complete and child started to run, tell ptracer */ if (unlikely(trace)) ptrace_event_pid(trace, pid); if (clone_flags & CLONE_VFORK) { if (!wait_for_vfork_done(p, &vfork)) ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid); } put_pid(pid); } else { nr = PTR_ERR(p); } return nr; }
2、关于execve函数系统调用
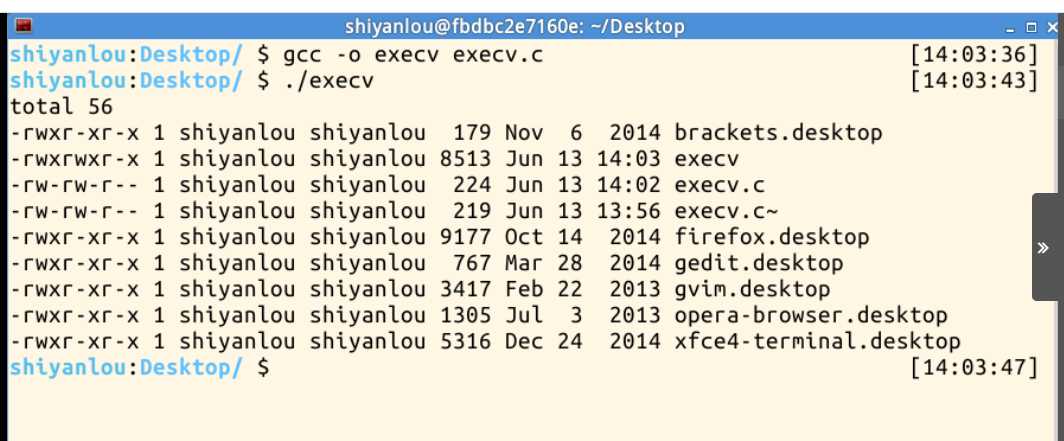
execve()用来执行参数filename字符串所代表的文件路径,第二个参数是利用指针数组来传递给执行文件,并且需要以空指针(NULL)结束,最后一个参数则为传递给执行文件的新环境变量数组。
#include <unistd.h> int main(int arg,char **args) { //char *name="/usr/bin/ls"; char *argv[]={"ls","-l","/home/shiyanlou/Desktop",NULL}; char *envp[]={0,NULL}; execve("/bin/ls",argv,envp); }
argv是要调用的程序执行的参数序列,也就是我们要调用的程序需要传入的参数。
envp 同样也是参数序列,一般来说他是一种键值对的形式 key=value. 作为我们是新程序的环境。
3、进程切换的关键代码switch_to分析
1、进程的切换
(1)为了控制进程的执行,内核必须有能力挂起正在CPU上执行的进程,并恢复以前挂起的某个进程的执行,这叫做进程切换、任务切换、上下文切换;
(2)挂起正在CPU上执行的进程,与中断时保存现场是不同的,中断前后是在同一个进程上下文中,只是由用户态转向内核态执行;
(3)进程上下文包含了进程执行需要的所有信息
1)用户地址空间:包括程序代码,数据,用户堆栈等
2)控制信息:进程描述符,内核堆栈等
3)硬件上下文(注意中断也要保存硬件上下文只是保存的方法不同)
2、schedule()函数选择一个新的进程来运行,并调用context_switch进行上下文的切换,这个宏调用switch_to来进行关键上下文切换
(1)next = pick_ next_task(rq, prev);//进程调度算法都封装这个函数内部
(2)context_switch(rq, prev, next);//进程上下文切换
(3)switch_to利用了prev和next两个参数:prev指向当前进程,next指向被调度的进程
#define switch_to(prev,next,last) do { asm volatile( "pushl %%esi\n\t""pushl %%edi\n\t""pushl %%ebp\n\t""movl %%esp,%0\n\t" /* save ESP */"movl %3,%%esp\n\t" /* restore ESP */"movl $1f,%1\n\t" /* save EIP */"pushl %4\n\t" /* restore EIP */"jmp __switch_to\n""1:\t""popl %%ebp\n\t""popl %%edi\n\t""popl %%esi\n\t" :"=m" (prev->thread.esp), "=m" (prev->thread.eip), "=b" (last) :"m" (next->thread.esp), "m" (next->thread.eip), "a" (prev), "d" (next), "b" (prev)); } while (0)
4、Linux系统的一般执行过程
两个进程间的切换:
- 正在运行的用户态进程X
- 发生中断——save cs:eip/esp/eflags(current) to kernel stack,then load cs:eip(entry of a specific ISR) and ss:esp(point to kernel stack).
- SAVE_ALL //保存现场
- 中断处理过程中或中断返回前调用了schedule(),其中的switch_to做了关键的进程上下文切换
- 标号1之后开始运行用户态进程Y(这里Y曾经通过以上步骤被切换出去过因此可以从标号1继续执行)
- restore_all //恢复现场
- iret - pop cs:eip/ss:esp/eflags from kernel stack
- 继续运行用户态进程Y
中断:
- 通过中断处理过程中的调度时机,用户态进程与内核线程之间互相切换和内核线程之间互相切换,与最一般的情况非常类似,只是内核线程运行过程中发生中断没有进程用户态和内核态的转换;
- 内核线程主动调用schedule(),只有进程上下文的切换,没有发生中断上下文的切换,与最一般的情况略简略;
- 创建子进程的系统调用在子进程中的执行起点及返回用户态,如fork;
- 加载一个新的可执行程序后返回到用户态的情况,如execve;
五、总结
1、Linux进程调度是基于分时和优先级的。
2、Linux中,内核线程是只有内核态没有用户态的特殊进程。
3、内核可以看作各种中断处理过程和内核线程的集合。
4、Linux系统的一般执行过程 可以抽象成正在运行的用户态进程X切换到运行用户态进程Y的过程。
5、Linux中,内核线程可以主动调度,主动调度时不需要中断上下文的切换。
6、Linux内核调用schedule()函数进行调度,并调用context_switch进行上下文的切换,这个宏调用switch_to来进行关键上下文切换。