标签:lis equal average 转换 start 调用函数 app 结构 针对
目标:使用Python编写爬虫,获取链家青岛站的房产信息,然后对爬取的房产信息进行分析。
环境:win10+python3.8+pycharm
Python库:
1 import requests 2 import bs4 3 from bs4 import BeautifulSoup 4 import lxml 5 import re 6 import xlrd 7 import xlwt 8 import xlutils.copy 9 import time
目标分析:
1、编写爬虫爬取链家青岛站的房产信息
①分析目标链接
第一页:https://qd.fang.lianjia.com/loupan/pg/pg1
第二页:https://qd.fang.lianjia.com/loupan/pg/pg2
由上面的链接可以看出来,不同网页是使用最后的pgx来进行变化的
所以将链接分为两部分,使用字符串拼接获得所有的房产网页链接
1 WebDiZhi = [] 2 for i in range(1,85): 3 UrlHTML = Url + str(i) 4 WebDiZhi.append(UrlHTML)
使用遍历获得所有的链接并保存为列表
②分析网页结构
1 #获取目标网页的html代码并进行解析 2 Xu = 0 3 Shuliang = len(WebDiZhi) 4 while Xu in range(Shuliang):#循环整个列表 5 6 Web = requests.get(WebDiZhi[Xu]) 7 WebText = Web.text 8 9 #第一步、粗筛选目标信息所在的html代码,去除大部分无效信息代码 10 soup_One = BeautifulSoup(WebText,‘html.parser‘) 11 XinXi_One = soup_One.find_all(class_="resblock-list-wrapper") 12 13 #第二步、进一步筛选目标信息所在html代码,去除无效信息代码 14 soup_Two = BeautifulSoup(str(XinXi_One),‘lxml‘) 15 XinXi_Two = soup_Two.find_all(class_="resblock-desc-wrapper")
通过两步简单的筛选将房产信息所对应的html代码筛选出来
方便进一步分析html网页标签获取不同的房产信息
③针对不同的房产信息定义不同的函数,通过调用函数来获取不同的房产信息并保存到目标文件中
1 print("-----------------开始写入第{}页-------------".format(Xu)) 2 Name = GetName(XinXi_Two) # 获取小区名称 3 Write_File(Name, 0,Xu) 4 print("---------小区名称写入成功---------") 5 time.sleep(3) #延时 6 Nature = NatureHouse(XinXi_Two) # 获取小区住宅性质(住宅、商业性) 7 Write_File(Nature, 1,Xu) 8 print("---------小区性质写入成功---------") 9 time.sleep(3) 10 Status = StatusHouse(XinXi_Two) # 获取小区状态(在售) 11 Write_File(Status, 2,Xu) 12 print("---------小区状态写入成功---------") 13 time.sleep(3) 14 Address = AddressHouse(XinXi_Two) # 获取小区地址 15 Write_File(Address, 3,Xu) 16 print("---------小区地址写入成功---------") 17 time.sleep(3) 18 Area = AreaHouse(XinXi_Two) # 获取小区房屋面积 19 Write_File(Area, 4,Xu) 20 print("---------小区面积写入成功---------") 21 time.sleep(3) 22 Average = AveragePriceHouse(XinXi_Two) # 均价 23 Write_File(Average, 5,Xu) 24 print("---------小区均价写入成功---------") 25 time.sleep(3) 26 Total = TotalPriceHouse(XinXi_Two) # 总价 27 Write_File(Total, 6,Xu) 28 print("---------小区总价写入成功---------") 29 time.sleep(3)
各房产信息函数
1 def Write_File(Data, lei,Hang): 2 data = xlrd.open_workbook(r"F:\实例\Python实例\爬虫\111.xls") 3 ws = xlutils.copy.copy(data) 4 table = ws.get_sheet(0) 5 Shu = Hang * 10 6 for i in range(len(Data)): 7 table.write(i + 1 + Shu, lei, Data[i]) 8 print("----第{}项写入成功----".format(i)) 9 ws.save(r"F:\实例\Python实例\爬虫\111.xls") 10 11 12 def GetName(XinXi): 13 """ 14 @param XinXi: 传入GetHTML函数第二步中筛选出的div标签下的html代码以及目标信息 15 @return: 返回小区名称,列表类型 16 """ 17 Nmae_list = [] 18 # 获取小区名称 19 Obtain_Name_One = BeautifulSoup(str(XinXi), ‘lxml‘) 20 Name_One = Obtain_Name_One.findAll(class_="name") 21 for i in Name_One: 22 Get_A = BeautifulSoup(str(i), ‘lxml‘) 23 Nmae_list.append(Get_A.string) 24 return Nmae_list 25 26 """ 27 代码以及目标信息均已获取,通过不同函数将html代码在对应函数中逐一进行解析获取函数对应信息并保存即可 28 以下为部分函数,其他函数未定义 29 30 """ 31 def NatureHouse(Nature): 32 """房屋性质""" 33 Nature_list = [] 34 Obtain_Nature = BeautifulSoup(str(Nature), ‘lxml‘) 35 Nature_one = Obtain_Nature.find_all(class_=‘resblock-type‘) 36 for i in Nature_one: 37 Get_Span = BeautifulSoup(str(i), ‘lxml‘) 38 Nature_list.append(Get_Span.string) 39 return Nature_list 40 41 def StatusHouse(Status): 42 """房屋状态""" 43 Status_list = [] 44 Obtain_Nature = BeautifulSoup(str(Status), ‘lxml‘) 45 Status_one = Obtain_Nature.find_all(class_=‘sale-status‘) 46 for i in Status_one: 47 Get_Span = BeautifulSoup(str(i), ‘lxml‘) 48 Status_list.append(Get_Span.string) 49 return Status_list 50 51 def AddressHouse(Area): 52 """ 53 54 55 @param Area:传入GetHTML函数第二步中筛选出的div标签下的html代码以及目标信息 56 @return: 57 Analysis_Label_xxx:分析标签,xxx:代表第几次分析 58 Target_Information_xxx:目标信息,xxx:代表第几个信息部分,总共分为两部分,以及一个整体信息存储列表Target_Information_list 59 """ 60 #获取标签 61 Target_Information_list = [] 62 Analysis_Label_One = BeautifulSoup(str(Area), ‘lxml‘) 63 # 获取div标签,calss=resblock-location 64 Get_label_One = Analysis_Label_One.find_all(class_=‘resblock-location‘) 65 #解析标签并获得span标签 66 Analysis_Label_Two = BeautifulSoup(str(Get_label_One), ‘lxml‘) 67 Get_label_Two = Analysis_Label_Two.find_all(name=‘span‘) 68 69 70 #获取span标签里面的文字内容并保存在列表内 71 72 #第一个 73 Target_Information_One = [] 74 for i in Get_label_Two: 75 #使用正则表达式取出内部信息并保存在列表中 76 Information_Str = re.sub(r‘<.*?>‘,‘‘,str(i)) 77 Target_Information_One.append(Information_Str) 78 #将列表内相同小区的地址进行合并,使用循环嵌套获取内容、合并最后保存在列表内 79 i = 1 80 a = 0 81 82 #第二个,第二个信息是在第一个信息的基础上合并列表内的元素得来 83 Target_Information_Two = [] 84 while i <= len(Target_Information_One): 85 while a < i: 86 #将Target_Information_One中每两项进行合并 87 Information_Two = Target_Information_One[a] 88 Information_One = Target_Information_One[i] 89 Information_Three = Information_One + Information_Two 90 91 Target_Information_Two.append(Information_Three) 92 a += 2 93 i += 2 94 95 96 #获取详细地址 97 98 #第三个 99 Target_Information_Three = [] 100 Span_html_One = Analysis_Label_Two.find_all(name=‘a‘) 101 for c in Span_html_One: 102 Area_Str_1 = re.sub(r‘<.*?>‘, ‘‘, str(c)) 103 Target_Information_Three.append(Area_Str_1) 104 105 106 # 将Target_Information_Two和Target_Information_Three两个列表中的各项元素分别进行合并并保存在Area_list列表中 107 A = min(len(Target_Information_Two),len(Target_Information_Three)) 108 for i in range(A): 109 Target_Information_list.append(Target_Information_Two[i] + Target_Information_Three[i]) 110 111 112 return Target_Information_list 113 114 115 def AreaHouse(Area): 116 """ 117 118 @param Area: 传入GetHTML函数第二步中筛选出的div标签下的html代码以及目标信息 119 @return: 返回房屋房间数量以及房屋总面积 120 """ 121 Area_list = [] 122 #筛选目标信息的父标签 123 Obtain_Area_One = BeautifulSoup(str(Area), ‘lxml‘) 124 Area_one = Obtain_Area_One.find_all(class_=‘resblock-room‘) 125 126 #通过正则表达式去除多余的html标签信息 127 Get_Area_One = [] 128 for c in Area_one: 129 Area_Str_1 = re.sub(r‘<.*?>‘, ‘‘, str(c)) 130 Get_Area_One.append(Area_Str_1) 131 132 #通过正则表达式去除多余的换行符 133 Get_Area_Two = [] 134 for i in Get_Area_One: 135 Area_Str_2 = re.sub(r‘\s+‘,‘‘,str(i)) 136 Get_Area_Two.append(Area_Str_2) 137 138 139 #开始获取房屋总面积 140 Obtain_Area_Two = BeautifulSoup(str(Area),‘lxml‘) 141 Area_two = Obtain_Area_Two.find_all(class_=‘resblock-area‘) 142 #通过正则表达式去除多余的html标签信息 143 Get_Area_Three = [] 144 for a in Area_two: 145 Area_Str_3 = re.sub(r‘<.*?>‘, ‘‘, str(a)) 146 Get_Area_Three.append(Area_Str_3) 147 148 # 通过正则表达式去除多余的换行符 149 Get_Area_Four = [] 150 for r in Get_Area_Three: 151 Area_Str_4 = re.sub(r‘\s+‘, ‘‘, str(r)) 152 Get_Area_Four.append(Area_Str_4) 153 154 # 将Get_Area_Two和Get_Area_Four两个列表中的各项元素分别进行合并并保存在Area_list列表中 155 A = min(len(Get_Area_Two), len(Get_Area_Four)) 156 for i in range(A): 157 Area_list.append(Get_Area_Two[i] + Get_Area_Four[i]) 158 159 return Area_list 160 161 def AveragePriceHouse(Average): 162 """ 163 房屋均价 164 @param Average: 165 @return: 166 """ 167 Average_list = [] 168 Obtain_Average = BeautifulSoup(str(Average), ‘lxml‘) 169 Average_one = Obtain_Average.find_all(class_=‘number‘) 170 for i in Average_one: 171 Get_Span = BeautifulSoup(str(i), ‘lxml‘) 172 Average_list.append(Get_Span.string) 173 174 return Average_list 175 176 177 178 def TotalPriceHouse(Total): 179 """ 180 房屋总价 181 182 @param Total: 183 @return: 184 """ 185 Total_list = [] 186 Obtain_Total = BeautifulSoup(str(Total), ‘lxml‘) 187 Total_one = Obtain_Total.fjind_all(class_=‘second‘) 188 for i in Total_one: 189 Get_Span = BeautifulSoup(str(i), ‘lxml‘) 190 Get_Span_one = Get_Span.string 191 Get_Span_two = Get_Span_one.lstrip(‘总价‘) 192 Total_list.append(Get_Span_two) 193 194 195 return Total_list
创建存储文件
1 def Create_File(): 2 name = [‘名称‘,‘性质‘,‘状态‘,‘地址‘,‘面积‘,‘均价‘,‘总价‘,] 3 workbook = xlwt.Workbook(encoding=‘utf-8‘, style_compression=0) 4 sheet = workbook.add_sheet(‘shett1‘, cell_overwrite_ok=True) 5 for i in range(len(name)): 6 sheet.write(0, i, name[i]) 7 workbook.save(r‘F:\实例\Python实例\爬虫\111.xls‘) 8 print("文件创建成功")
2、简单的数据分析并使用饼状图表示房产均价比例
所用到的库:
import pandas as pd import xlrd import re import xlutils.copy import matplotlib.pyplot as plt
①数据清洗----删除空值行
1 def ExceptNull(): 2 """ 3 数据清洗第一步:去除表中空值 4 @param df: 传入读取的xls表格数据 5 @return: 保存数据后返回, 6 """ 7 df = pd.DataFrame(pd.read_excel(r‘F:\实例\Python实例\爬虫\111.xls‘)) 8 #查找面积列空值,使用99999填充空缺值后删除所在行 9 print(df[‘面积‘].isnull().value_counts()) 10 df["面积"] = df["面积"].fillna(‘99999‘) 11 NullKey = df[(df.面积 == ‘99999‘)].index.tolist() 12 print(NullKey) 13 df = df.drop(NullKey) 14 print("*"*30) 15 print(df[‘面积‘].isnull().value_counts()) 16 17 print("*"*30) 18 #查找总价列空值,使用99999填充空缺值后删除所在行 19 print(df[‘总价‘].isnull().value_counts()) 20 df["总价"] = df["总价"].fillna(‘99999‘) 21 NullKey1 = df[(df.总价 == ‘99999‘)].index.tolist() 22 print(NullKey1) 23 df = df.drop(NullKey1) 24 print("*"*30) 25 print(df[‘总价‘].isnull().value_counts()) 26 df.to_excel(‘111.xls‘,index=False,encoding=‘uf-8‘) 27 28 29 print("修改后数据保存成功")
②数据预处理----将数据转换成易处理格式
1 def LeiChuli(): 2 Data = xlrd.open_workbook(r"F:\实例\Python实例\爬虫\111.xls") 3 ws = xlutils.copy.copy(Data) 4 Table = Data.sheet_by_name("Sheet1") 5 Nrows = Table.nrows 6 list_A = [] 7 for i in range(1,Nrows): 8 A = Table.cell_value(i,6) 9 A_Str = re.sub(‘/套‘,‘‘,A,Nrows) 10 list_A.append(A_Str) 11 Replace = [] 12 for i in range(len(list_A)): 13 Price_Str = list_A[i] 14 Last_Str = Price_Str[-1] 15 if Last_Str == ‘万‘: 16 A_Str = re.sub(‘万‘, ‘0000‘, Price_Str, 1) 17 Replace.append(A_Str) 18 else: 19 Replace.append(Price_Str) 20 table = ws.get_sheet(0) 21 for i in range(len(Replace)): 22 table.write(i + 1, 6, Replace[i]) 23 print("------>开始写入修改后数据<------") 24 print("---->第{}项写入成功<----".format(i)) 25 ws.save(r"F:\实例\Python实例\爬虫\111.xls") 26 print("------>数据写入完成<------")
③对处理后的数据进行分析并绘制饼状图
1 def Data_Analysis_One(): 2 Data = xlrd.open_workbook(r"F:\实例\Python实例\爬虫\111.xls") 3 ws = xlutils.copy.copy(Data) 4 Table = Data.sheet_by_name("Sheet1") 5 Nrows = Table.nrows 6 a,b,c,d,e,f = 0,0,0,0,0,0 7 8 for i in range(1, Nrows): 9 A = Table.cell_value(i, 5) 10 if A == "价格待定": 11 f += 1 12 else: 13 if int(A) <= 5000: 14 a += 1 15 elif int(A) <= 10000: 16 b += 1 17 elif int(A) <= 15000: 18 c += 1 19 elif int(A) <= 20000: 20 d += 1 21 else: 22 e += 1 23 24 # 开始准备绘制饼状图 25 26 #价格区间数据准备 27 sizes = [] 28 Percentage_a = (a / Nrows) * 100 29 sizes.append(int(Percentage_a)) 30 Percentage_b = (b / Nrows) * 100 31 sizes.append(int(Percentage_b)) 32 Percentage_c = (c / Nrows) * 100 33 sizes.append(int(Percentage_c)) 34 Percentage_d = (d / Nrows) * 100 35 sizes.append(int(Percentage_d)) 36 Percentage_e = (e / Nrows) * 100 37 sizes.append(int(Percentage_e)) 38 Percentage_f = (f / Nrows) * 100 39 sizes.append(int(Percentage_f)) 40 #设置占比说明 41 labels = ‘0-5000‘,‘5001-10000‘,‘10001-15000‘,‘15001-20000‘,‘20000-‘,‘Undetermined‘ 42 explode = (0,0,0.1,0,0,0) 43 #开始绘制 44 plt.pie(sizes,explode=explode,labels=labels,autopct=‘%1.1f%%‘,shadow=True,startangle=90) 45 plt.axis(‘equal‘) 46 plt.show() 47 ws.save(r"F:\实例\Python实例\爬虫\111.xls")
最后附上效果图。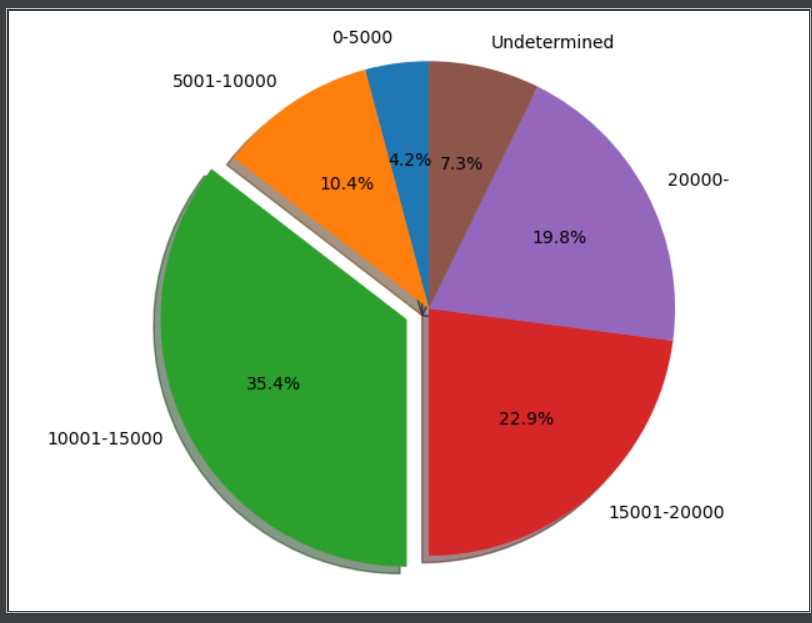
最后附上完整代码:
1、爬虫代码
1 import requests 2 import bs4 3 from bs4 import BeautifulSoup 4 import lxml 5 import re 6 # import LianJia_QD_DataProcessing 7 import xlrd 8 import xlwt 9 import xlutils.copy 10 import time 11 12 def GetHTML(Url): 13 """ 14 1、通过传入url组合,获取所有网页地址的url 15 2、获取目标网页的html代码并进行解析 16 3、解析后将目标信息分别写入字典类型的变量并返回 17 18 @param Url: 目标网址的不变链接 19 @return: 网站目标信息 20 21 """ 22 23 #通过传入url组合,获取所有网页地址的url 24 WebDiZhi = [] 25 for i in range(1,85): 26 UrlHTML = Url + str(i) 27 WebDiZhi.append(UrlHTML) 28 29 print("共计{}页".format(len(WebDiZhi))) 30 # Create_File() 31 #获取目标网页的html代码并进行解析 32 Xu = 0 33 Shuliang = len(WebDiZhi) 34 while Xu in range(Shuliang):#range(len(WebDiZhi))--循环整个列表 35 36 Web = requests.get(WebDiZhi[Xu]) 37 WebText = Web.text 38 39 #第一步、粗筛选目标信息所在的html代码,去除大部分无效信息代码 40 soup_One = BeautifulSoup(WebText,‘html.parser‘) 41 XinXi_One = soup_One.find_all(class_="resblock-list-wrapper") 42 43 #第二步、进一步筛选目标信息所在html代码,去除无效信息代码 44 soup_Two = BeautifulSoup(str(XinXi_One),‘lxml‘) 45 XinXi_Two = soup_Two.find_all(class_="resblock-desc-wrapper") 46 47 print("-----------------第{}页爬取成功------------".format(Xu)) 48 # Html.append(XinXi_Two) 49 # time.sleep(1) 50 # return Html 51 52 print("-----------------开始写入第{}页-------------".format(Xu)) 53 Name = GetName(XinXi_Two) # 获取小区名称 54 Write_File(Name, 0,Xu) 55 print("---------小区名称写入成功---------") 56 time.sleep(3) 57 Nature = NatureHouse(XinXi_Two) # 获取小区住宅性质(住宅、商业性) 58 Write_File(Nature, 1,Xu) 59 print("---------小区性质写入成功---------") 60 time.sleep(3) 61 Status = StatusHouse(XinXi_Two) # 获取小区状态(在售) 62 Write_File(Status, 2,Xu) 63 print("---------小区状态写入成功---------") 64 time.sleep(3) 65 Address = AddressHouse(XinXi_Two) # 获取小区地址 66 Write_File(Address, 3,Xu) 67 print("---------小区地址写入成功---------") 68 time.sleep(3) 69 Area = AreaHouse(XinXi_Two) # 获取小区房屋面积 70 Write_File(Area, 4,Xu) 71 print("---------小区面积写入成功---------") 72 time.sleep(3) 73 Average = AveragePriceHouse(XinXi_Two) # 均价 74 Write_File(Average, 5,Xu) 75 print("---------小区均价写入成功---------") 76 time.sleep(3) 77 Total = TotalPriceHouse(XinXi_Two) # 总价 78 Write_File(Total, 6,Xu) 79 print("---------小区总价写入成功---------") 80 time.sleep(3) 81 82 Xu += 1 83 84 # 调用不同函数获取不同信息 85 86 87 def Write_File(Data, lei,Hang): 88 data = xlrd.open_workbook(r"F:\实例\Python实例\爬虫\111.xls") 89 ws = xlutils.copy.copy(data) 90 table = ws.get_sheet(0) 91 Shu = Hang * 10 92 for i in range(len(Data)): 93 table.write(i + 1 + Shu, lei, Data[i]) 94 print("----第{}项写入成功----".format(i)) 95 ws.save(r"F:\实例\Python实例\爬虫\111.xls") 96 97 98 def GetName(XinXi): 99 """ 100 @param XinXi: 传入GetHTML函数第二步中筛选出的div标签下的html代码以及目标信息 101 @return: 返回小区名称,列表类型 102 """ 103 Nmae_list = [] 104 # 获取小区名称 105 Obtain_Name_One = BeautifulSoup(str(XinXi), ‘lxml‘) 106 Name_One = Obtain_Name_One.findAll(class_="name") 107 for i in Name_One: 108 Get_A = BeautifulSoup(str(i), ‘lxml‘) 109 Nmae_list.append(Get_A.string) 110 return Nmae_list 111 112 """ 113 代码以及目标信息均已获取,通过不同函数将html代码在对应函数中逐一进行解析获取函数对应信息并保存即可 114 以下为部分函数,其他函数未定义 115 116 """ 117 def NatureHouse(Nature): 118 """房屋性质""" 119 Nature_list = [] 120 Obtain_Nature = BeautifulSoup(str(Nature), ‘lxml‘) 121 Nature_one = Obtain_Nature.find_all(class_=‘resblock-type‘) 122 for i in Nature_one: 123 Get_Span = BeautifulSoup(str(i), ‘lxml‘) 124 Nature_list.append(Get_Span.string) 125 return Nature_list 126 127 def StatusHouse(Status): 128 """房屋状态""" 129 Status_list = [] 130 Obtain_Nature = BeautifulSoup(str(Status), ‘lxml‘) 131 Status_one = Obtain_Nature.find_all(class_=‘sale-status‘) 132 for i in Status_one: 133 Get_Span = BeautifulSoup(str(i), ‘lxml‘) 134 Status_list.append(Get_Span.string) 135 return Status_list 136 137 def AddressHouse(Area): 138 """ 139 140 141 @param Area:传入GetHTML函数第二步中筛选出的div标签下的html代码以及目标信息 142 @return: 143 Analysis_Label_xxx:分析标签,xxx:代表第几次分析 144 Target_Information_xxx:目标信息,xxx:代表第几个信息部分,总共分为两部分,以及一个整体信息存储列表Target_Information_list 145 """ 146 #获取标签 147 Target_Information_list = [] 148 Analysis_Label_One = BeautifulSoup(str(Area), ‘lxml‘) 149 # 获取div标签,calss=resblock-location 150 Get_label_One = Analysis_Label_One.find_all(class_=‘resblock-location‘) 151 #解析标签并获得span标签 152 Analysis_Label_Two = BeautifulSoup(str(Get_label_One), ‘lxml‘) 153 Get_label_Two = Analysis_Label_Two.find_all(name=‘span‘) 154 155 156 #获取span标签里面的文字内容并保存在列表内 157 158 #第一个 159 Target_Information_One = [] 160 for i in Get_label_Two: 161 #使用正则表达式取出内部信息并保存在列表中 162 Information_Str = re.sub(r‘<.*?>‘,‘‘,str(i)) 163 Target_Information_One.append(Information_Str) 164 #将列表内相同小区的地址进行合并,使用循环嵌套获取内容、合并最后保存在列表内 165 i = 1 166 a = 0 167 168 #第二个,第二个信息是在第一个信息的基础上合并列表内的元素得来 169 Target_Information_Two = [] 170 while i <= len(Target_Information_One): 171 while a < i: 172 #将Target_Information_One中每两项进行合并 173 Information_Two = Target_Information_One[a] 174 Information_One = Target_Information_One[i] 175 Information_Three = Information_One + Information_Two 176 177 Target_Information_Two.append(Information_Three) 178 a += 2 179 i += 2 180 181 182 #获取详细地址 183 184 #第三个 185 Target_Information_Three = [] 186 Span_html_One = Analysis_Label_Two.find_all(name=‘a‘) 187 for c in Span_html_One: 188 Area_Str_1 = re.sub(r‘<.*?>‘, ‘‘, str(c)) 189 Target_Information_Three.append(Area_Str_1) 190 191 192 # 将Target_Information_Two和Target_Information_Three两个列表中的各项元素分别进行合并并保存在Area_list列表中 193 A = min(len(Target_Information_Two),len(Target_Information_Three)) 194 for i in range(A): 195 Target_Information_list.append(Target_Information_Two[i] + Target_Information_Three[i]) 196 197 198 return Target_Information_list 199 200 201 def AreaHouse(Area): 202 """ 203 204 @param Area: 传入GetHTML函数第二步中筛选出的div标签下的html代码以及目标信息 205 @return: 返回房屋房间数量以及房屋总面积 206 """ 207 Area_list = [] 208 #筛选目标信息的父标签 209 Obtain_Area_One = BeautifulSoup(str(Area), ‘lxml‘) 210 Area_one = Obtain_Area_One.find_all(class_=‘resblock-room‘) 211 212 #通过正则表达式去除多余的html标签信息 213 Get_Area_One = [] 214 for c in Area_one: 215 Area_Str_1 = re.sub(r‘<.*?>‘, ‘‘, str(c)) 216 Get_Area_One.append(Area_Str_1) 217 218 #通过正则表达式去除多余的换行符 219 Get_Area_Two = [] 220 for i in Get_Area_One: 221 Area_Str_2 = re.sub(r‘\s+‘,‘‘,str(i)) 222 Get_Area_Two.append(Area_Str_2) 223 224 225 #开始获取房屋总面积 226 Obtain_Area_Two = BeautifulSoup(str(Area),‘lxml‘) 227 Area_two = Obtain_Area_Two.find_all(class_=‘resblock-area‘) 228 #通过正则表达式去除多余的html标签信息 229 Get_Area_Three = [] 230 for a in Area_two: 231 Area_Str_3 = re.sub(r‘<.*?>‘, ‘‘, str(a)) 232 Get_Area_Three.append(Area_Str_3) 233 234 # 通过正则表达式去除多余的换行符 235 Get_Area_Four = [] 236 for r in Get_Area_Three: 237 Area_Str_4 = re.sub(r‘\s+‘, ‘‘, str(r)) 238 Get_Area_Four.append(Area_Str_4) 239 240 # 将Get_Area_Two和Get_Area_Four两个列表中的各项元素分别进行合并并保存在Area_list列表中 241 A = min(len(Get_Area_Two), len(Get_Area_Four)) 242 for i in range(A): 243 Area_list.append(Get_Area_Two[i] + Get_Area_Four[i]) 244 245 return Area_list 246 247 def AveragePriceHouse(Average): 248 """ 249 房屋均价 250 @param Average: 251 @return: 252 """ 253 Average_list = [] 254 Obtain_Average = BeautifulSoup(str(Average), ‘lxml‘) 255 Average_one = Obtain_Average.find_all(class_=‘number‘) 256 for i in Average_one: 257 Get_Span = BeautifulSoup(str(i), ‘lxml‘) 258 Average_list.append(Get_Span.string) 259 260 return Average_list 261 262 263 264 def TotalPriceHouse(Total): 265 """ 266 房屋总价 267 268 @param Total: 269 @return: 270 """ 271 Total_list = [] 272 Obtain_Total = BeautifulSoup(str(Total), ‘lxml‘) 273 Total_one = Obtain_Total.fjind_all(class_=‘second‘) 274 for i in Total_one: 275 Get_Span = BeautifulSoup(str(i), ‘lxml‘) 276 Get_Span_one = Get_Span.string 277 Get_Span_two = Get_Span_one.lstrip(‘总价‘) 278 Total_list.append(Get_Span_two) 279 280 281 return Total_list 282 283 284 def Create_File(): 285 name = [‘名称‘,‘性质‘,‘状态‘,‘地址‘,‘面积‘,‘均价‘,‘总价‘,] 286 workbook = xlwt.Workbook(encoding=‘utf-8‘, style_compression=0) 287 sheet = workbook.add_sheet(‘shett1‘, cell_overwrite_ok=True) 288 for i in range(len(name)): 289 sheet.write(0, i, name[i]) 290 workbook.save(r‘F:\实例\Python实例\爬虫\111.xls‘) 291 print("文件创建成功") 292 293 294 if __name__ == ‘__main__‘: 295 url = "https://qd.fang.lianjia.com/loupan/pg" 296 Create_File() 297 DataHtml = GetHTML(url) 298 299 print("全部房产信息写入成功")
2、数据处理代码
1 import pandas as pd 2 import xlrd 3 import re 4 import xlutils.copy 5 import matplotlib.pyplot as plt 6 7 def ExceptNull(): 8 """ 9 数据清洗第一步:去除表中空值 10 @param df: 传入读取的xls表格数据 11 @return: 保存数据后返回, 12 """ 13 df = pd.DataFrame(pd.read_excel(r‘F:\实例\Python实例\爬虫\111.xls‘)) 14 #查找面积列空值,使用99999填充空缺值后删除所在行 15 print(df[‘面积‘].isnull().value_counts()) 16 df["面积"] = df["面积"].fillna(‘99999‘) 17 NullKey = df[(df.面积 == ‘99999‘)].index.tolist() 18 print(NullKey) 19 df = df.drop(NullKey) 20 print("*"*30) 21 print(df[‘面积‘].isnull().value_counts()) 22 23 print("*"*30) 24 #查找总价列空值,使用99999填充空缺值后删除所在行 25 print(df[‘总价‘].isnull().value_counts()) 26 df["总价"] = df["总价"].fillna(‘99999‘) 27 NullKey1 = df[(df.总价 == ‘99999‘)].index.tolist() 28 print(NullKey1) 29 df = df.drop(NullKey1) 30 print("*"*30) 31 print(df[‘总价‘].isnull().value_counts()) 32 df.to_excel(‘111.xls‘,index=False,encoding=‘uf-8‘) 33 34 35 print("修改后数据保存成功") 36 37 38 def LeiChuli(): 39 Data = xlrd.open_workbook(r"F:\实例\Python实例\爬虫\111.xls") 40 ws = xlutils.copy.copy(Data) 41 Table = Data.sheet_by_name("Sheet1") 42 Nrows = Table.nrows 43 list_A = [] 44 for i in range(1,Nrows): 45 A = Table.cell_value(i,6) 46 A_Str = re.sub(‘/套‘,‘‘,A,Nrows) 47 list_A.append(A_Str) 48 Replace = [] 49 for i in range(len(list_A)): 50 Price_Str = list_A[i] 51 Last_Str = Price_Str[-1] 52 if Last_Str == ‘万‘: 53 A_Str = re.sub(‘万‘, ‘0000‘, Price_Str, 1) 54 Replace.append(A_Str) 55 else: 56 Replace.append(Price_Str) 57 table = ws.get_sheet(0) 58 for i in range(len(Replace)): 59 table.write(i + 1, 6, Replace[i]) 60 print("------>开始写入修改后数据<------") 61 print("---->第{}项写入成功<----".format(i)) 62 ws.save(r"F:\实例\Python实例\爬虫\111.xls") 63 print("------>数据写入完成<------") 64 65 66 def Data_Analysis_One(): 67 Data = xlrd.open_workbook(r"F:\实例\Python实例\爬虫\111.xls") 68 ws = xlutils.copy.copy(Data) 69 Table = Data.sheet_by_name("Sheet1") 70 Nrows = Table.nrows 71 a,b,c,d,e,f = 0,0,0,0,0,0 72 73 for i in range(1, Nrows): 74 A = Table.cell_value(i, 5) 75 if A == "价格待定": 76 f += 1 77 else: 78 if int(A) <= 5000: 79 a += 1 80 elif int(A) <= 10000: 81 b += 1 82 elif int(A) <= 15000: 83 c += 1 84 elif int(A) <= 20000: 85 d += 1 86 else: 87 e += 1 88 89 # 开始准备绘制饼状图 90 91 #价格区间数据准备 92 sizes = [] 93 Percentage_a = (a / Nrows) * 100 94 sizes.append(int(Percentage_a)) 95 Percentage_b = (b / Nrows) * 100 96 sizes.append(int(Percentage_b)) 97 Percentage_c = (c / Nrows) * 100 98 sizes.append(int(Percentage_c)) 99 Percentage_d = (d / Nrows) * 100 100 sizes.append(int(Percentage_d)) 101 Percentage_e = (e / Nrows) * 100 102 sizes.append(int(Percentage_e)) 103 Percentage_f = (f / Nrows) * 100 104 sizes.append(int(Percentage_f)) 105 #设置占比说明 106 labels = ‘0-5000‘,‘5001-10000‘,‘10001-15000‘,‘15001-20000‘,‘20000-‘,‘Undetermined‘ 107 explode = (0,0,0.1,0,0,0) 108 #开始绘制 109 plt.pie(sizes,explode=explode,labels=labels,autopct=‘%1.1f%%‘,shadow=True,startangle=90) 110 plt.axis(‘equal‘) 111 plt.show() 112 ws.save(r"F:\实例\Python实例\爬虫\111.xls") 113 114 115 if __name__ == ‘__main__‘: 116 # ExceptNull() 117 # LeiChuli() 118 Data_Analysis_One() 119 120
数据来源于链家青岛站部分数据,因为一些原因爬取结果可能不是完全符合预期。
转发请注明出处、欢迎指教、私信。
标签:lis equal average 转换 start 调用函数 app 结构 针对
原文地址:https://www.cnblogs.com/dmsj20190707/p/13121923.html