标签:基础 img jvm 源文件 sdn syn 文件 不可变 报错
javac命令后面跟的是java文件的文件名,例如HelloWorld.java。该命令用于把java源文件编译成为class字节码文件。如: java HelloWorld.java,执行之后如果没有报错,那么就会生成一个HelloWorld.class文件。
java命令后面跟的是类名,例如HelloWorld。记住不带.class的后缀。这是因为 java XXX.yyy 的意思是执行XXX包下面的yyy类,java HelloWorld.class会被以为是执行HelloWorld包下的class类。
java所有组成部分都需要名字,变量名、对象名、方法名都是标识符。
标识符应该遵循以下规则。
1.以大小写字母,或者美元符号($),下划线(_)开头。
2.开头之后除了以上几种,还可以接数字。
3.大小写敏感。
4.不能用关键字
美元符号$一般是内部类编译出来后命名用的,我们平时写代码时最好不要去用它。下划线_是区别于驼峰法的一种命名规则,像python语言给对象取名的时候就多是用下划线。
还有一个,不能用数字开头。这是因为怕你整个变量名都是数字,比如,int 123; a=123,那么请问,第二个123是数字还是变量?
这里解释一下为什么一个源文件只能有一个public类,而且源文件的名称应该和public类保持一致:
这样做的目的是为了加快编译器的编译速度,假设现在不用遵守一个public的原则,那么我写了两个文件a.java和m.java,a.java里面有class A、class B、class C...这些类,m.java里面有class M、class N、class C这些类。好了,现在我来编译a.java,发现里面的class A中的某个办法用到了class M,那么我们应该先编译完class M再接着编译class A。问题来了,因为没有一个public的原则,那么我要从所有java文件里面去一个一个地找class M,这样就会很耗时间。如果有了一个public的原则,而且文件名和public类同名,我只需要找到M.java文件,就肯定可以找到class M,快速地完成编译。
byte->short/char->int->long->float->double
其他的都很容易理解,就是在long->float这里很多人都卡住了,不知道为什么64位的long会转到32位的float。
我们打印一下就可以知道,long的取值范围为-2^63~2^63-1,float的取值范围为-2^127至2^127,很明显float的取值范围要比long大得多。这是因为long的内存有符号的以二进制补码表示的整数,但是float是符合IEEE 754标准的浮点数,第一位是符号位,0为正1为负,后面8位是指数位,再跟23位小数位。
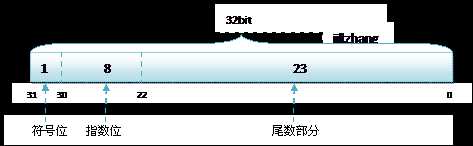
比如8.25用二进制可以表示成1000.01,用二进制科学计数法可以表示为1.00001 * 2^3,这样符号位就是0,指数为就是127+3=130二进制为10000010(127是因为指数有正有负,初始值应该为01111111=127),然后小数位表示0001 0000 0000 0000 0000 000。所以人家一个指数位就能表示-2^127到2^127,还不比long强?
程序中任何变量或者代码都是在编译时由系统自动分配内存来存储的,而所谓的静态就是编译以后分配的内存一直存在,直到程序退出内存才会释放这个空间,也就是只要程序运行,那么这块内存就会一直存在。
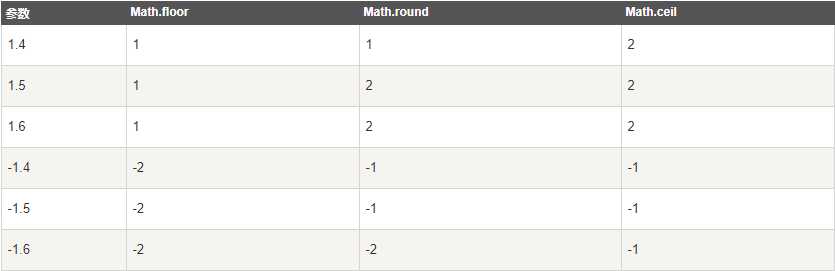
我们可以这么理解,floor方法是取不大于参数的整数,而ceil方法是取不小于参数的整数,round方法比较特别,是先给参数加上0.5,再向下取整的(round=floor(参数+0.5)),这就能解释为什么round(1.5) = 2,round(-1.5) = -1了。
string是字符串常量,stringbuffer字符串变量(线程安全),stringbuilder字符串变量(非线程安全)。
因为string不可变,所以要新建一个String对象,然后再把指针指向新的对象,因为每次生成对象都会对系统性能产生影响,特别是当内存中无用对象多了以后,JVM的GC就会开始工作,那速度就一定会相当慢。
stringbuffer本身是一个字符串缓冲区,有append和insert等方法,可以接可以改,所以可变。
比如说:
String s1 = "This is only a " + "simple " + "test. " 要比 StringBuffer Sb = new StringBuilder(“This is only a”).append(“ simple”).append(“ test”)的速度快上很多。其实这是JVM的一个技巧,它把 "This is only a " + "simple " + "test. " 看成是“This is only a simple test”,所以当然不用花太多时间。
如果是String S2 = “This is only a”; String S3 = “ simple”; String S4 = “ test”; String S1 = S2 +S3 + S4;那么虚拟机就会规规矩矩地按照原先的方法去做了。
因为stringbuffer里面的方法加了synchronized修饰符,而stringbuilder没有,这也是为什么stringbuffer比stringbuilder慢的原因。
① dataType[] arrayName;
②dataType arrayName[];
java是建议使用第一种方法来声明数组的,但是为什么会有第二种方法呢,那是因为C/C++用的就是第二种方法,为了让熟悉C/C++的程序员能更快地上手java,才兼容了第二种方法。
时间仓促再加上本人水平有限,难免有错漏之处,还望批评指正
参考文章:
https://blog.csdn.net/WaitForFree/article/details/51033457
https://blog.csdn.net/wu_pan123/article/details/77766041
https://blog.csdn.net/rmn190/article/details/1492013
标签:基础 img jvm 源文件 sdn syn 文件 不可变 报错
原文地址:https://www.cnblogs.com/isgoto/p/12984939.html