标签:设置 分组 多少 会计 group 面积 填充 写法 超过
查询条件查询
我们查询的时候可以加上where条件这样既能取得我们想要的数据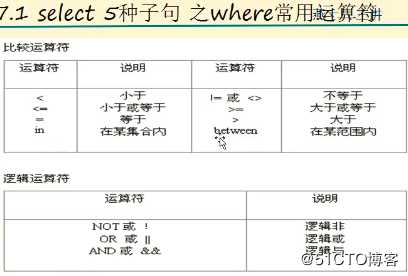
这里做一个简单查询练习
查出满足以下条件的商品
1.1:主键为32的商品
select goods_id,goods_name,shop_price from ecs_goods where goods_id=32;
2.1.2:不属第3栏目的所有商品
select goods_id,cat_id,goods_name,shop_price from ecs_goods where cat_id!=3;
2.1.3:本店价格高于3000元的商品
select goods_id,cat_id,goods_name,shop_price from ecs_goods where shop_price >3000;
2.1.4:本店价格低于或等于100元的商品
select goods_id,cat_id,goods_name,shop_price from ecs_goods where shop_price <=100;
2.1.5:取出第4栏目或第11栏目的商品(不许用or)
select goods_id,cat_id,goods_name,shop_price from ecs_goods
where cat_id in (4,11);
2.1.6:取出100<=价格<=500的商品(不许用and)
select goods_id,cat_id,goods_name,shop_price from ecs_goods
where shop_price between 100 and 500;
2.1.7:取出不属于第3栏目且不属于第11栏目的商品(and,或not in分别实现)
select goods_id,cat_id,goods_name,shop_price from ecs_goods where cat_id!=3 and cat_id!=11;
select goods_id,cat_id,goods_name,shop_price from ecs_goods where cat_id not in (3,11);
2.1.8:取出价格大于100且小于300,或者大于4000且小于5000的商品(and的优先级高于or)
select goods_id,cat_id,goods_name,shop_price from ecs_goods where shop_price>100 and shop_price <300 or shop_price >4000 and shop_price <5000;
2.1.9:取出第3个栏目下面价格<1000或>3000,并且点击量>5的系列商品(注意and的优先级高于or)
select goods_id,cat_id,goods_name,shop_price,click_count from ecs_goods where
cat_id=3 and (shop_price <1000 or shop_price>3000) and click_count>5;
2.1.10:取出第1个栏目下面的商品(注意:1栏目下面没商品,但其子栏目下有)
select goods_id,cat_id,goods_name,shop_price,click_count from ecs_goods
where cat_id in (2,3,4,5);
2.1.11:取出名字以"诺基亚"开头的商品
select goods_id,cat_id,goods_name,shop_price from ecs_goods where goods_name like ‘诺基亚%‘;
2.1.12:取出名字为"诺基亚Nxx"的手机
select goods_id,cat_id,goods_name,shop_price from ecs_goods
where goods_name like ‘诺基亚N__‘;
2.1.13:取出名字不以"诺基亚"开头的商品
select goods_id,cat_id,goods_name,shop_price from ecs_goos
where goods_name not like ‘诺基亚%‘;
2.1.14:取出第3个栏目下面价格在1000到3000之间,并且点击量>5 "诺基亚"开头的系列商品
select goods_id,cat_id,goods_name,shop_price from ecs_goods where
cat_id=3 and shop_price>1000 and shop_price <3000 and click_count>5 and goods_name like ‘诺基亚%‘;
select goods_id,cat_id,goods_name,shop_price from ecs_goods where
shop_price between 1000 and 3000 and cat_id=3 and click_count>5 and goods_name like ‘诺基亚%‘;
2.1.15把num值处于[20,29]之间,改为20,num值处于[30,39]之间的,改为30
update table set num=floor(num/10)*10 where num >=20 and num <=39
2.1.16把good表中商品名为‘诺基亚xxxx‘的商品,改为‘HTCxxxx‘,
update goods set goods_name=concat("HTC",substring(goods_name,4)) where goods_name like "诺基亚%"
奇怪的null
当我们的某个字段设置为可以为空,我们插入数据时可以插入null。
select from 表 where 字段 != null 这样是查询不到任何数据的
select from 表 where 字段 = null 这样是查询不到任何数据的
注意在mysql数据库中null是不等于null
当我们要想查字段是否是null专门提供一个查询条件 is null 如下
select * from 表 where 字段 is null 这样能查出来字段为null的值
这种查询方式不利于优化,所以不推荐使用,我们建立字段是可以设置成不为空再加上一个默认值,默认值为‘’空字符串。
聚合函数
聚合函数(常用于group by从句的select查询中)
avg(col)返回指定列的平均值
count(col)返回指定列中非null值的个数
min(col)返回指定列的最小值
max(col)返回指定列的最大值
sum(col)返回指定列的所有值之和
group_concat(col) 返回由属于一组的列值连接组合而成的结果
2.1:查出最贵的商品的价格
select max(shop_price) from ecs_goods;
2.2:查出最大(最新)的商品编号
select max(goods_id) from ecs_goods;
2.3:查出最便宜的商品的价格
select min(shop_price) from ecs_goods;
2.4:查出最旧(最小)的商品编号
select min(goods_id) from ecs_goods;
2.5:查询该店所有商品的库存总量
select sum(goods_number) from ecs_goods;
2.6:查询所有商品的平均价
select avg(shop_price) from ecs_goods;
2.7:查询该店一共有多少种商品
select count(*) from ecs_goods;
分组查询
select 聚合函数,分组字段,【其他字段】 from 表 group by 分组字段
group by 时会mysql内部会先根据分组字段排序然后再统计,我们可以给分组字段设置索引。
我们分组查询时我们查找的字段有聚合函数,分组字段,这都是没有问题的,但是有个其他字段是有问题的,这个其他字段到底是那条记录的值呢?就好比我让大家按宿舍统计宿舍人的平均身高,这时我们查询的宿舍号和平均身高都没有问题,但是你又要了姓名,这时该用谁的姓名呢?其实这种写法语义上是有问题的,在orancle上直接会报错,但是mysql上不会报错,这时这个其他字段会使用第一次出现的那一行的那个列来填充。
查询每个栏目下面最贵商品价格
select cat_id,max(shop_price) from ecs_goods group by cat_id;
group_concat的使用
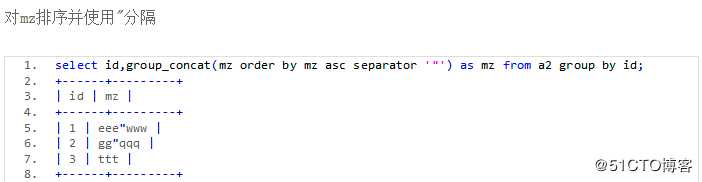
having筛选
我们要想查询市场价比本店高超过200个商品
select goods_id,goods_name,market_price-shop_price
from ecs_goods where market_price-shop_price > 200 ;
上面的写法会计算市场价和本店价差值计算2次
我们可以使用一个别名的方式
select goods_id,goods_name,market_price-shop_price as j
from ecs_goods where j > 200 ;
上面的写法会报错,说不认识 j 这个字段。
这时我们不能使用where了我们得使用having
select goods_id,goods_name,market_price-shop_price as j
from ecs_goods having j > 200 ;
where和having的区别
where是针对磁盘上的数据进行筛选,筛选出结果集后放在内存中我们再使用having进行筛选。having永远不能放在where前面。
分组查询练习
3 having与group综合运用查询:
3.1:查询该店的商品比市场价所节省的价格
select goods_id,goods_name,market_price-shop_price as j
from ecs_goods ;
3.2:查询每个商品所积压的货款(提示:库存单价)
select goods_id,goods_name,goods_numbershop_price from ecs_goods
3.3:查询该店积压的总货款
select sum(goods_number*shop_price) from ecs_goods;
3.4:查询该店每个栏目下面积压的货款.
select cat_id,sum(goods_number*shop_price) as k from ecs_goods group by cat_id;
3.5:查询比市场价省钱200元以上的商品及该商品所省的钱(where和having分别实现)
select goods_id,goods_name,market_price-shop_price as k from ecs_goods
where market_price-shop_price >200;
select goods_id,goods_name,market_price-shop_price as k from ecs_goods
having k >200;
3.6:查询积压货款超过2W元的栏目,以及该栏目积压的货款
select cat_id,sum(goods_number*shop_price) as k from ecs_goods group by cat_id having k>20000
排序order by
order by 字段 不写就是正序
order by 字段 asc 正序
order by 字段 desc 倒叙
order by 字段1 正序,字段2 desc 先按照字段1进行正序排,如果字段1都一样的话,再根据字段2进行倒叙排列。
限制条数limit
limit 3 取前3条
limit 5,3 从第5条取,取3条。
select 字段1,字段2 ,聚合函数 from 表 where 条件 group by 字段 having 条件 order by 字段 limit 便宜量,限制条数
有如下表及数据
+------+---------+-------+
| name | subject | score |
+------+---------+-------+
| 张三 | 数学 | 90 |
| 张三 | 语文 | 50 |
| 张三 | 地理 | 40 |
| 李四 | 语文 | 55 |
| 李四 | 政治 | 45 |
| 王五 | 政治 | 30 |
+------+---------+-------+
要求:查询出2门及2门以上不及格者的平均成绩
一种错误做法
mysql> select name,count(score<60) as k,avg(score) from stu group by name having k>=2;
+------+---+------------+
| name | k | avg(score) |
+------+---+------------+
| 张三 | 3 | 60.0000 |
| 李四 | 2 | 50.0000 |
+------+---+------------+
2 rows in set (0.00 sec)
#利用having筛选挂科2门以上的.
mysql> select name,sum(score < 60) as gk ,avg(score) as pj from stu group by name having gk >=2;
+------+------+---------+
| name | gk | pj |
+------+------+---------+
| 张三 | 2 | 60.0000 |
| 李四 | 2 | 50.0000 |
+------+------+---------+
2 rows in set (0.00 sec)
where 型子查询
将查询的结果作为另一条查询语句的查询条件
查询goods_id最大的那条数据
select from goods where goods_id=(select max(goods_id) from goods);
查询每个分类下goods_id最大的那个商品的信心
select from goods where goods_id in (select max(goods_id) from goods group by cate_id);
from型子查询
将查询的结果集作为另一条查询语句的表来看
select from (select from goods order by cate_id asc,goods_id desc) group by cate_id
exists型的子查询
查出栏目下没有商品的栏目
select from cate where exists(select from goods where
goods.cate_id=cate.cate_id;
内连接
select from goods inner join cate on goods.cate_id = cate.cate_id
inner 可以省略
如果goods表中的数据在cate表中匹配不到数据时,就把goods表条这数据就丢掉。
左(外)连接
select from goods left join cate on goods.cate_id = cate.cate_id
如果goods表中的数据在cate表中匹配不到数据时,这是会把goods表中的数据留下来,cate表的字段用null进行填充
右(外)连接
select from goods right join cate on goods.cate_id = cate.cate_id
如果goods表中的数据在cate表中匹配不到数据时,会把cate表中的数据留下来,goods表的字段用null进行填充。
全(外)连接
select from goods full join cate on goods.cate_id = cate.cate_id
如果goods表中的数据在cate表中匹配不到数据时,会把goods表中的数据留下来,cate表的字段用null进行填充。如果cate表中的数据在goods表中匹配不到数据时,会把cate表中的数据留下来,goods表的字段用null进行填充。
交叉查询
select from 表1 cross join 表2
获得表1和表2的笛卡尔积
简写形式 select from 表1,表2
联合查询
将查询的结果集纵向的合并为一个结果集
select goods_id,goods_name from goods where cate_i=2
unnin
select goods_id,goods_name from goods where cate_id=4
数据源可以是同一张表,亦可以是不同表,各个语句取出的列数必须相同,字段名称用的是第一个sql语句的字段。注意上面的数据有完全相同的会被合并(去重),合并和花费大量的时间
我们可以使用 union all 这样就不会将相同的数据合并(不会去重)
select goods_id,goods_name from goods where cate_i=2
unnin all
select goods_id,goods_name from goods where cate_id=4
union联合查询时每个sql语句排序是没有意义的。
标签:设置 分组 多少 会计 group 面积 填充 写法 超过
原文地址:https://blog.51cto.com/5493817/2504291