标签:layer ima 正态分布 loader network eval width eva col
http://neuralnetworksanddeeplearning.com/chap4.html
总结:
1. vanishing gradient problem:神经网络的不同层学习的速度显著不同。原因:weights式服从正态分布,那么w<1,而σ‘(zi) 服从N(0,1/4),那么w*σ‘(zi)<=1/4,而dC/db1的公式为![]() ,那么dC/dbi是逐层减少的。
,那么dC/dbi是逐层减少的。
2. Exploding gradient problem:
6.1 深度神经网络中训练难点
到目前为止,我们例子中使用的神经网络一共只有3层(一个隐藏层)。我们用以上神经网络(通过调参)达到了98%的accuracy。
更深层的神经网络可以学习到不同抽象程度的概念。例如:图像中:第一层学到边角信息,第二层学到一些基本形状,第三层学到物理概念。
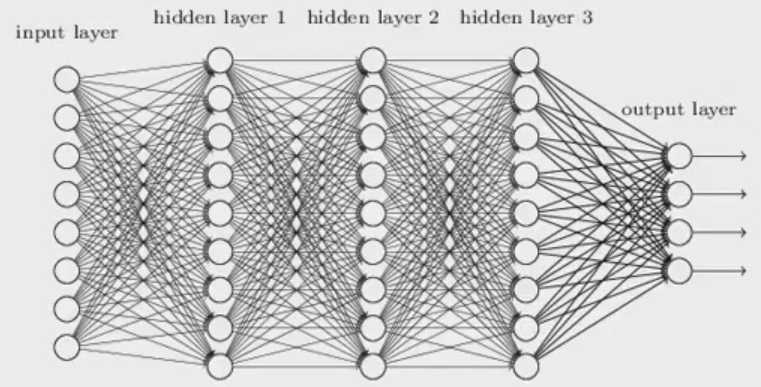
如何训练深度神经网络?
难点:神经网络的不同层学习的速度显著不同。接近输出层更新bias比较快,学习速率比较合适,而前面的几层更新bias的速度比较慢,学习太慢,有时候被困住。
消失的gradient问题(varnishing g‘radient problem):
import mnist_loader training_data, validation_data, test_data = mnist_loader.load_data_wrapper() import network2 net = network2.Network([784,30,10]) net.SGD(training_data,30,10,0.1,lmbda=5.0, evaluation_data=validation_data,monitor_evaluation_accuracy=True)
结果:96.48%
加入一个隐藏层:
net = network2.Network([784,30,30,10])
net.SGD(training_data,30,10,0.1,lmbda=5.0, evaluation_data=validation_data,monitor_evaluation_accuracy=True)
结果:96。9%
再加入一层隐藏层:
net = network2.Network([784,30,30,3010])
net.SGD(training_data,30,10,0.1,lmbda=5.0, evaluation_data=validation_data,monitor_evaluation_accuracy=True)
结果:96.57%
为什么加入一层反而准确率下降了? -》 varnishing g‘radient problem
条形趋于长度代表dC/db,Cost对于bias的变化率:
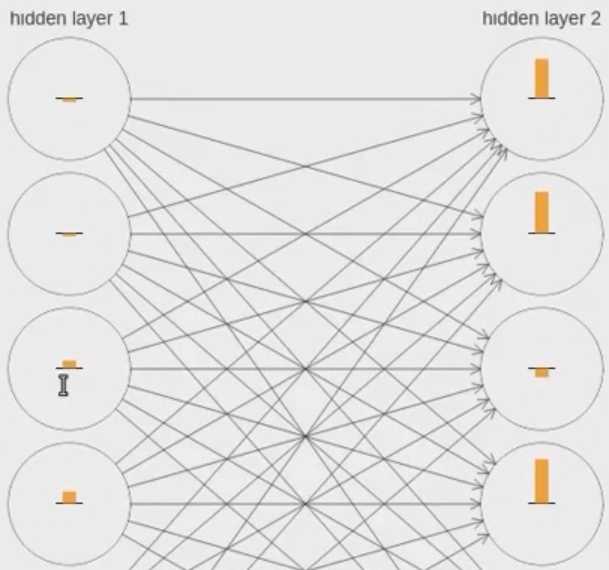
hidden layer 1 的条形值都下于hidden layer2的条形值。即第一层学习的速率远远低于第二层的速率。
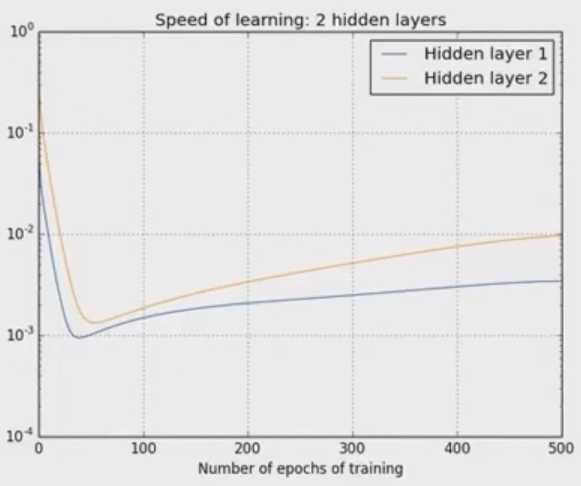
在5层的随机物理中:[784,30,30,30,10],学习率分别为0.012,0..6 and 0.283。越往后,越靠近输出层,他的学习速率就越快。以上是初始的是偶的学习率,下面的图表示了在训练1000张图片,两层神经网络学习率的差异,当神经网络在训练过程当中,不同层随epoch增加时学习率的变化:
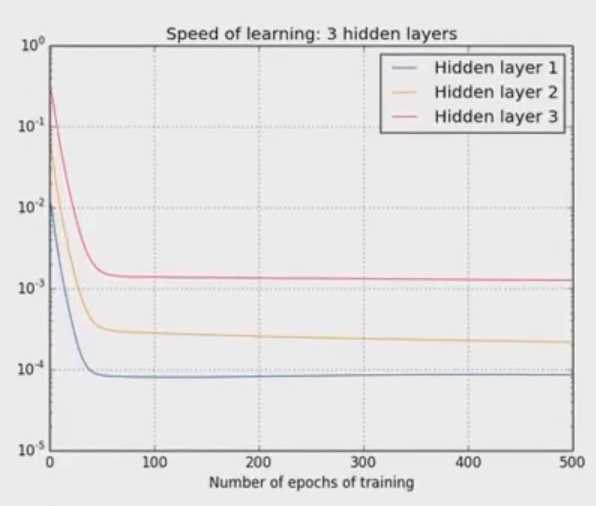
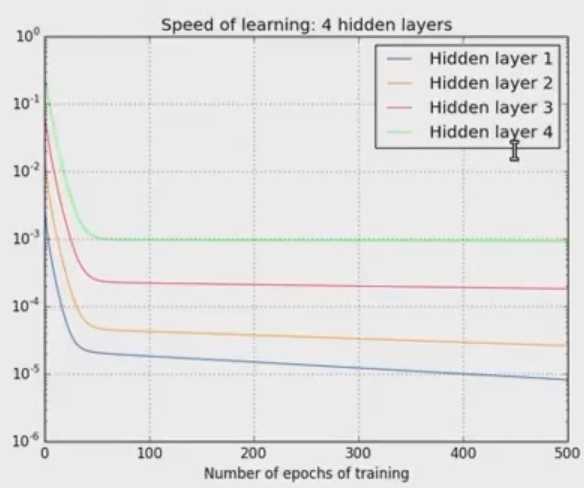
中间图是另外一个例子:[784,30,30,30,10],右图,再加入一层::[784,30,30,30,30,10]。可以看出,第一隐藏层比第四个隐藏层几乎慢100倍这种现象普通存在于神经网络之总,叫做:vanishing gradient problem。另外一种情况是内层的梯度被外层大很多,叫做exploding gradient problem。所以说神经网络算法用gradient之类的算法学习存在不稳定性。
训练深度神经网络,需要解决vanishing gradient problem,造成他的原因:
假设每层只有一个神经元
![]()
![]() ,其中
,其中 ![]() 得到向前更新的表达式:C= σ(W4*σ(w3*σ(w2*σ(w1*x+b1)+b2)+b3)+b4)
得到向前更新的表达式:C= σ(W4*σ(w3*σ(w2*σ(w1*x+b1)+b2)+b3)+b4)
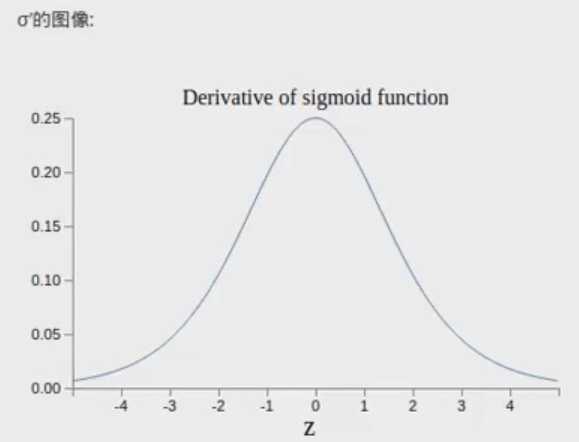
而Cost对bias的偏导的公式为dC/db1为:![]() ,所以从公式可以看出,越靠前的隐藏层的C对b的偏导越小。大部分的weights式服从正态分布,那么w<1,而σ‘(zi) 服从N(0,1/4),那么w*σ‘(zi)<=1/4,而dC/db1的公式为
,所以从公式可以看出,越靠前的隐藏层的C对b的偏导越小。大部分的weights式服从正态分布,那么w<1,而σ‘(zi) 服从N(0,1/4),那么w*σ‘(zi)<=1/4,而dC/db1的公式为![]() ,那么dC/dbi是逐层减少的。
,那么dC/dbi是逐层减少的。
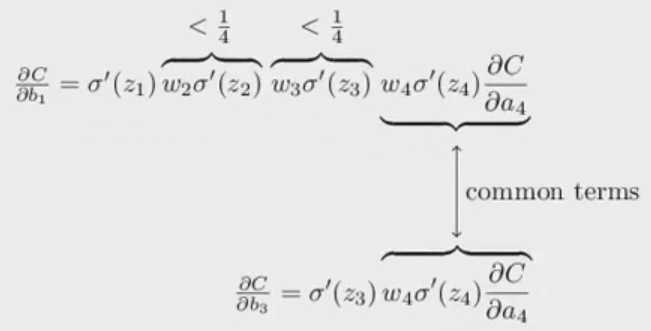
所以对于以上公式的多项乘积来讲,层数越多,连续乘积减小。
6.2 解决vanishing gradient 问题
Exploding gradient problem
Python_DL_麦子学院(算法与应用_进阶)_21~22_训练难点
标签:layer ima 正态分布 loader network eval width eva col
原文地址:https://www.cnblogs.com/tlfox2006/p/13130209.html