标签:esc 查询语句 原理 select 语句拼接 修改 唯一索引 create car
mysql存储引擎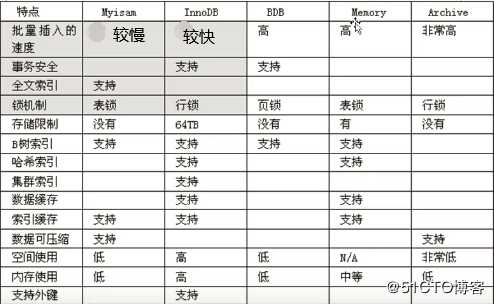
当我们创建视图是可以指定创建视图的算法
create algorithm=merge|temptable view 视图名 as 查询
创建视图时algorithm这个选项可以不写,到时候创建视图,会自己根据创建视图的语句,自动指定算法。
查看所有表和视图
show tables
查看表结构和视图
desc 视图名
查看创建视图过程
show create view 视图名称
查看表的详细信息
show table status where name ="表名|视图" \G
如果是个视图他的comment注释是view。
删除视图
drop view 视图名
索引
数据库的数据归根结底是存储在硬盘上的文件,那我们进行查询,怎么能以最快的速度查到想要的文件。这是我们要使用索引维护我们的数据,索引是高效查询的数据结构,当我们查找数据时首先查找索引,索引会以一定的算法(hash或btree)很快的定位到行数据放在那里。就像数的目录和数的内容一样。
索引的使用提高了查询速度,降低了增删改的速度,所以不是索引添加的越多越好。
加索引的条件:
1 一般表中数据量比较大的时候加索引
2在查询频次比较高的列上加索引
3列中的数据重复度比较低加索引效果更好
索引的分类
主键索引 primary key:一张表只能有一个主键。
唯一索引 unique key:如果某一列的数据要求不能重复,且查询频次比较高时我们可以建立唯一索引。
普通索引 key:如果一列查询频次比较高,我们可以建立一个普通索引。
全文索引 fulltext:在英文环境下,mysql把会把英文单词作为一个一个的分词,当我们搜索单词时我们能用到全文索引,在中文环境下,我们的汉字都是连着的,只有搜索的文字和数据库存放的文字一样时,才能使用上全文索引,这种一般不符合需求,所以全文索引在中文下无效,一般选择使用第三方软件,比如:sphinx或者使用ElasticSearch。
组合索引:将多列的值看成一个整体,然后建立索引,组合索引要遵循最左原则。
https://www.jianshu.com/p/fd781d6e1158
冗余索引:我们可以在同一列上建立多个索引,比如我们在全文索引上在加上普通索引。
建立索引时可以给 某一列的前一部分建立索引。比如email列的前10个字符创建索引,在需要在建立索引时后面加个长度比如:unique key email(email(10))
create table user(
id int(10) primary key auto_increment, 主键索引
name char(5) not null,
email char(20) not null,
firstname varchar(20),
lastname varchar(20),
key name(name), 普通索引
unique key email(email), 唯一索引
key xingming(firstname,lastname) 组合索引
)
索引的操作:
在navcate中我们可以使用图形化工具操作索引
show index from 表 查看表的索引
show create table 表 查看表的结构,也能看到索引。
删除索引:alter table 表 drop index 索引名称。
drop index 索引名 on 表。
explain 查询语句 查看查询语句使用到那个索引了。
事务
比如:我们的转账业务,张三要将钱转给李四,首先;应该执行
update card set money=money-500 where user=张三
update cart set money=money+500 where user=李四
只有上面的两条SQL语句都执行成功时,整个转钱的过程才算执行成功。这个时候我们要用到事务。
事务的使用
1开启事务
start transaction;
2执行sql语句
3要么提交,要么回滚
提交:commit 回滚:rollback()
只有innodb引擎的表才能使用事务。
事务的特性(ACID)
隔离性
隔离性是多个事物的时候, 相互不能干扰。
原子性
我们的sql语句要么都执行成功,要么都执行失败
一致性
一致性关注数据的可见性,中间状态的数据对另一个进程不可见,只有最初状态和最终状态的数据对外可见
持久性
事务一旦执行完毕后,就撤销不回来了。
标签:esc 查询语句 原理 select 语句拼接 修改 唯一索引 create car
原文地址:https://blog.51cto.com/5493817/2504479