应用实例:
你是否玩过二十个问题的游戏,游戏的规则很简单:参与游戏的一方在脑海里想某个事物,
其他参与者向他提问题,只允许提20个问题,问题的答案也只能用对或错回答。问问题的人通过
推断分解,逐步缩小待猜测事物的范围。决策树的工作原理与20个问题类似,用户输人一系列数
据,然后给出游戏的答案。如下表
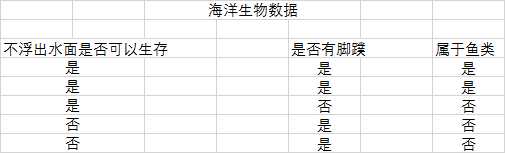
假如我告诉你,我有一个海洋生物,它不浮出水面可以生存,并且没有脚蹼,你来判断一下是否属于鱼类?
通过决策树,你就可以快速给出答案不是鱼类。
决策树的目的就是在一大堆无序的数据特征中找出有序的规则,并建立决策树(模型)。
决策树比较文绉绉的介绍
决策树学习是一种逼近离散值目标函数的方法。通过将一组数据中学习的函数表示为决策树,从而将大量数据有目的的分类,从而找到潜在有价值的信息。决策树分类通常分为两步---生成树和剪枝;
树的生成 --- 自上而下的递归分治法;
剪枝 --- 剪去那些可能增大错误预测率的分枝。
决策树的方法起源于概念学习系统CLS(Concept Learning System), 然后发展最具有代表性的ID3(以信息熵作为目标评价函数)算法,最后又演化为C4.5, C5.0,CART可以处理连续属性。
这篇文章主要介绍ID3算法原理与代码实现(属于分类算法)
分类与回归的区别
回归问题和分类问题的本质一样,都是针对一个输入做出一个输出预测,其区别在于输出变量的类型。
分类问题是指,给定一个新的模式,根据训练集推断它所对应的类别(如:+1,-1),是一种定性输出,也叫离散变量预测;
回归问题是指,给定一个新的模式,根据训练集推断它所对应的输出值(实数)是多少,是一种定量输出,也叫连续变量预测。
举个例子:预测明天的气温是多少度,这是一个回归任务;预测明天是阴、晴还是雨,就是一个分类任务。
分类模型可将回归模型的输出离散化,回归模型也可将分类模型的输出连续化。
信息论相关知识
来自王小猴<<机器学习实战>>学习总结(二)------决策树算法(https://zhuanlan.zhihu.com/p/29980400),他将原理说得很透彻形象,这里借鉴一下。
1. 信息熵
在决策树算法中,熵是一个非常非常重要的概念。
一件事发生的概率越小,我们说它所蕴含的信息量越大。
比如:我们听女人能怀孕不奇怪,如果某天听到哪个男人怀孕了,那这个信息量就很大了......。
所以我们这样衡量信息量:
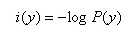
其中,P(y)是事件发生的概率。
信息熵就是所有可能发生的事件的信息量的期望:
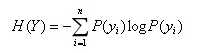
表达了Y事件发生的不确定度。
2. 条件熵
表示在X给定条件下,Y的条件概率分布的熵对X的数学期望。其数学推导如下: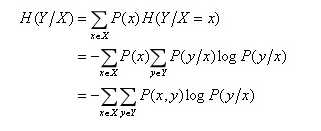
举个例子
例:女生决定主不主动追一个男生的标准有两个:颜值和身高,如下表所示:
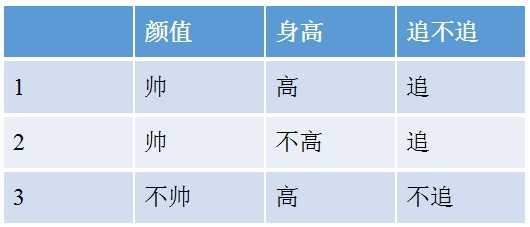
上表中随机变量Y={追,不追},P(Y=追)=2/3,P(Y=不追)=1/3,得到Y的熵:
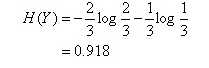
这里还有一个特征变量X,X={高,不高}。当X=高时,追的个数为1,占1/2,不追的个数为1,占1/2,此时:
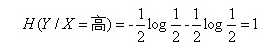
同理:
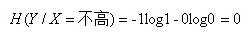
(注意:我们一般约定,当p=0时,plogp=0)
所以我们得到条件熵的计算公式:
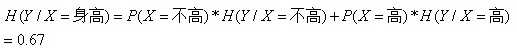
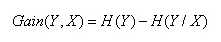
决策树算法
1. 算法简介
决策树算法是一类常见的分类和回归算法,顾名思义,决策树是基于树的结构来进行决策的。
以二分类为例,我们希望从给定训练集中学得一个模型来对新的样例进行分类。
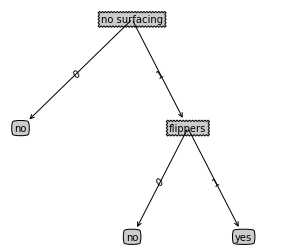
以上面海洋生物为例
no surfacing:不浮出水面是否可以生存
flippers:是否有脚蹼
将表特征量化(是:1,否:0)
我们可以建立这样一颗决策树(后面结果证明,这是最佳的决策树):
代码实现
paython3.6,Spyder运行环境,每行代码我基本都做了注释,最终能生成最优决策树结构,并用pyplot绘制了决策树,以及该决策树的叶子结点,树的深度。
ID3算法的核心是在决策树的各个结点上应用信息增益准则进行特征选择。具体做法是:
- 从根节点开始,对结点计算所有可能特征的信息增益,选择信息增益最大的特征作为结点的特征,并由该特征的不同取值构建子节点;
- 对子节点递归地调用以上方法,构建决策树;
- 直到所有特征的信息增益均很小或者没有特征可选时为止。
myTrees.py文件:



1 # -*- coding: utf-8 -*- 2 """ 3 Created on Thu Aug 2 17:09:34 2018 4 决策树ID3的实现 5 @author: weixw 6 """ 7 from math import log 8 import operator 9 #原始数据 10 def createDataSet(): 11 dataSet = [[1, 1, ‘yes‘], 12 [1, 1, ‘yes‘], 13 [1, 0, ‘no‘], 14 [0, 1, ‘no‘], 15 [0, 1, ‘no‘]] 16 labels = [‘no surfacing‘,‘flippers‘] 17 return dataSet, labels 18 19 #多数表决器 20 #列中相同值数量最多为结果 21 def majorityCnt(classList): 22 classCounts = {} 23 for value in classList: 24 if(value not in classCounts.keys()): 25 classCounts[value] = 0 26 classCounts[value] +=1 27 sortedClassCount = sorted(classCounts.iteritems(),key = operator.itemgetter(1),reverse =True) 28 return sortedClassCount[0][0] 29 30 31 #划分数据集 32 #dataSet:原始数据集 33 #axis:进行分割的指定列索引 34 #value:指定列中的值 35 def splitDataSet(dataSet,axis,value): 36 retDataSet= [] 37 for featDataVal in dataSet: 38 if featDataVal[axis] == value: 39 #下面两行去除某一项指定列的值,很巧妙有没有 40 reducedFeatVal = featDataVal[:axis] 41 reducedFeatVal.extend(featDataVal[axis+1:]) 42 retDataSet.append(reducedFeatVal) 43 return retDataSet 44 45 #计算香农熵 46 def calcShannonEnt(dataSet): 47 #数据集总项数 48 numEntries = len(dataSet) 49 #标签计数对象初始化 50 labelCounts = {} 51 for featDataVal in dataSet: 52 #获取数据集每一项的最后一列的标签值 53 currentLabel = featDataVal[-1] 54 #如果当前标签不在标签存储对象里,则初始化,然后计数 55 if currentLabel not in labelCounts.keys(): 56 labelCounts[currentLabel] = 0 57 labelCounts[currentLabel] += 1 58 #熵初始化 59 shannonEnt = 0.0 60 #遍历标签对象,求概率,计算熵 61 for key in labelCounts.keys(): 62 prop = labelCounts[key]/float(numEntries) 63 shannonEnt -= prop*log(prop,2) 64 return shannonEnt 65 66 #选出最优特征列索引 67 def chooseBestFeatureToSplit(dataSet): 68 #计算特征个数,dataSet最后一列是标签属性,不是特征量 69 numFeatures = len(dataSet[0])-1 70 #计算初始数据香农熵 71 baseEntropy = calcShannonEnt(dataSet) 72 #初始化信息增益,最优划分特征列索引 73 bestInfoGain = 0.0 74 bestFeatureIndex = -1 75 for i in range(numFeatures): 76 #获取每一列数据 77 featList = [example[i] for example in dataSet] 78 #将每一列数据去重 79 uniqueVals = set(featList) 80 newEntropy = 0.0 81 for value in uniqueVals: 82 subDataSet = splitDataSet(dataSet,i,value) 83 #计算条件概率 84 prob = len(subDataSet)/float(len(dataSet)) 85 #计算条件熵 86 newEntropy +=prob*calcShannonEnt(subDataSet) 87 #计算信息增益 88 infoGain = baseEntropy - newEntropy 89 if(infoGain > bestInfoGain): 90 bestInfoGain = infoGain 91 bestFeatureIndex = i 92 return bestFeatureIndex 93 94 #决策树创建 95 def createTree(dataSet,labels): 96 #获取标签属性,dataSet最后一列,区别于labels标签名称 97 classList = [example[-1] for example in dataSet] 98 #树极端终止条件判断 99 #标签属性值全部相同,返回标签属性第一项值 100 if classList.count(classList[0]) == len(classList): 101 return classList[0] 102 #只有一个特征(1列) 103 if len(dataSet[0]) == 1: 104 return majorityCnt(classList) 105 #获取最优特征列索引 106 bestFeatureIndex = chooseBestFeatureToSplit(dataSet) 107 #获取最优索引对应的标签名称 108 bestFeatureLabel = labels[bestFeatureIndex] 109 #创建根节点 110 myTree = {bestFeatureLabel:{}} 111 #去除最优索引对应的标签名,使labels标签能正确遍历 112 del(labels[bestFeatureIndex]) 113 #获取最优列 114 bestFeature = [example[bestFeatureIndex] for example in dataSet] 115 uniquesVals = set(bestFeature) 116 for value in uniquesVals: 117 #子标签名称集合 118 subLabels = labels[:] 119 #递归 120 myTree[bestFeatureLabel][value] = createTree(splitDataSet(dataSet,bestFeatureIndex,value),subLabels) 121 return myTree 122 123 #获取分类结果 124 #inputTree:决策树字典 125 #featLabels:标签列表 126 #testVec:测试向量 例如:简单实例下某一路径 [1,1] => yes(树干值组合,从根结点到叶子节点) 127 def classify(inputTree,featLabels,testVec): 128 #获取根结点名称,将dict转化为list 129 firstSide = list(inputTree.keys()) 130 #根结点名称String类型 131 firstStr = firstSide[0] 132 #获取根结点对应的子节点 133 secondDict = inputTree[firstStr] 134 #获取根结点名称在标签列表中对应的索引 135 featIndex = featLabels.index(firstStr) 136 #由索引获取向量表中的对应值 137 key = testVec[featIndex] 138 #获取树干向量后的对象 139 valueOfFeat = secondDict[key] 140 #判断是子结点还是叶子节点:子结点就回调分类函数,叶子结点就是分类结果 141 #if type(valueOfFeat).__name__==‘dict‘: 等价 if isinstance(valueOfFeat, dict): 142 if isinstance(valueOfFeat, dict): 143 classLabel = classify(valueOfFeat,featLabels,testVec) 144 else: 145 classLabel = valueOfFeat 146 return classLabel 147 148 149 #将决策树分类器存储在磁盘中,filename一般保存为txt格式 150 def storeTree(inputTree,filename): 151 import pickle 152 fw = open(filename,‘wb+‘) 153 pickle.dump(inputTree,fw) 154 fw.close() 155 #将瓷盘中的对象加载出来,这里的filename就是上面函数中的txt文件 156 def grabTree(filename): 157 import pickle 158 fr = open(filename,‘rb‘) 159 return pickle.load(fr) 160 161
treePlotter.py文件:
1 ‘‘‘ 2 Created on Oct 14, 2010 3 4 @author: Peter Harrington 5 ‘‘‘ 6 import matplotlib.pyplot as plt 7 8 decisionNode = dict(boxstyle="sawtooth", fc="0.8") 9 leafNode = dict(boxstyle="round4", fc="0.8") 10 arrow_args = dict(arrowstyle="<-") 11 12 #获取树的叶子节点 13 def getNumLeafs(myTree): 14 numLeafs = 0 15 #dict转化为list 16 firstSides = list(myTree.keys()) 17 firstStr = firstSides[0] 18 secondDict = myTree[firstStr] 19 for key in secondDict.keys(): 20 #判断是否是叶子节点(通过类型判断,子类不存在,则类型为str;子类存在,则为dict) 21 if type(secondDict[key]).__name__==‘dict‘:#test to see if the nodes are dictonaires, if not they are leaf nodes 22 numLeafs += getNumLeafs(secondDict[key]) 23 else: numLeafs +=1 24 return numLeafs 25 26 #获取树的层数 27 def getTreeDepth(myTree): 28 maxDepth = 0 29 #dict转化为list 30 firstSides = list(myTree.keys()) 31 firstStr = firstSides[0] 32 secondDict = myTree[firstStr] 33 for key in secondDict.keys(): 34 if type(secondDict[key]).__name__==‘dict‘:#test to see if the nodes are dictonaires, if not they are leaf nodes 35 thisDepth = 1 + getTreeDepth(secondDict[key]) 36 else: thisDepth = 1 37 if thisDepth > maxDepth: maxDepth = thisDepth 38 return maxDepth 39 40 def plotNode(nodeTxt, centerPt, parentPt, nodeType): 41 createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords=‘axes fraction‘, 42 xytext=centerPt, textcoords=‘axes fraction‘, 43 va="center", ha="center", bbox=nodeType, arrowprops=arrow_args ) 44 45 def plotMidText(cntrPt, parentPt, txtString): 46 xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0] 47 yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1] 48 createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30) 49 50 def plotTree(myTree, parentPt, nodeTxt):#if the first key tells you what feat was split on 51 numLeafs = getNumLeafs(myTree) #this determines the x width of this tree 52 depth = getTreeDepth(myTree) 53 firstSides = list(myTree.keys()) 54 firstStr = firstSides[0] #the text label for this node should be this 55 cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff) 56 plotMidText(cntrPt, parentPt, nodeTxt) 57 plotNode(firstStr, cntrPt, parentPt, decisionNode) 58 secondDict = myTree[firstStr] 59 plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD 60 for key in secondDict.keys(): 61 if type(secondDict[key]).__name__==‘dict‘:#test to see if the nodes are dictonaires, if not they are leaf nodes 62 plotTree(secondDict[key],cntrPt,str(key)) #recursion 63 else: #it‘s a leaf node print the leaf node 64 plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW 65 plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode) 66 plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key)) 67 plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD 68 #if you do get a dictonary you know it‘s a tree, and the first element will be another dict 69 #绘制决策树 70 def createPlot(inTree): 71 fig = plt.figure(1, facecolor=‘white‘) 72 fig.clf() 73 axprops = dict(xticks=[], yticks=[]) 74 createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) #no ticks 75 #createPlot.ax1 = plt.subplot(111, frameon=False) #ticks for demo puropses 76 plotTree.totalW = float(getNumLeafs(inTree)) 77 plotTree.totalD = float(getTreeDepth(inTree)) 78 plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0; 79 plotTree(inTree, (0.5,1.0), ‘‘) 80 plt.show() 81 82 #绘制树的根节点和叶子节点(根节点形状:长方形,叶子节点:椭圆形) 83 #def createPlot(): 84 # fig = plt.figure(1, facecolor=‘white‘) 85 # fig.clf() 86 # createPlot.ax1 = plt.subplot(111, frameon=False) #ticks for demo puropses 87 # plotNode(‘a decision node‘, (0.5, 0.1), (0.1, 0.5), decisionNode) 88 # plotNode(‘a leaf node‘, (0.8, 0.1), (0.3, 0.8), leafNode) 89 # plt.show() 90 91 def retrieveTree(i): 92 listOfTrees =[{‘no surfacing‘: {0: ‘no‘, 1: {‘flippers‘: {0: ‘no‘, 1: ‘yes‘}}}}, 93 {‘no surfacing‘: {0: ‘no‘, 1: {‘flippers‘: {0: {‘head‘: {0: ‘no‘, 1: ‘yes‘}}, 1: ‘no‘}}}} 94 ] 95 return listOfTrees[i] 96 97 #thisTree = retrieveTree(0) 98 #createPlot(thisTree) 99 #createPlot() 100 #myTree = retrieveTree(0) 101 #numLeafs =getNumLeafs(myTree) 102 #treeDepth =getTreeDepth(myTree) 103 #print(u"叶子节点数目:%d"% numLeafs) 104 #print(u"树深度:%d"%treeDepth)
testTrees_3.py测试文件:
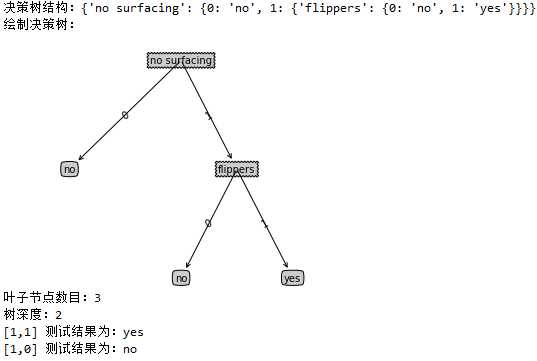
1 # -*- coding: utf-8 -*- 2 """ 3 Created on Fri Aug 3 19:52:10 2018 4 5 @author: weixw 6 """ 7 import myTrees as mt 8 import treePlotter as tp 9 #测试 10 dataSet, labels = mt.createDataSet() 11 #copy函数:新开辟一块内存,然后将list的所有值复制到新开辟的内存中 12 labels1 = labels.copy() 13 #createTree函数中将labels1的值改变了,所以在分类测试时不能用labels1 14 myTree = mt.createTree(dataSet,labels1) 15 #保存树到本地 16 mt.storeTree(myTree,‘myTree.txt‘) 17 #在本地磁盘获取树 18 myTree = mt.grabTree(‘myTree.txt‘) 19 print (u"决策树结构:%s"%myTree) 20 #绘制决策树 21 print(u"绘制决策树:") 22 tp.createPlot(myTree) 23 numLeafs =tp.getNumLeafs(myTree) 24 treeDepth =tp.getTreeDepth(myTree) 25 print(u"叶子节点数目:%d"% numLeafs) 26 print(u"树深度:%d"%treeDepth) 27 #测试分类 简单样本数据3列 28 labelResult =mt.classify(myTree,labels,[1,1]) 29 print(u"[1,1] 测试结果为:%s"%labelResult) 30 labelResult =mt.classify(myTree,labels,[1,0]) 31 print(u"[1,0] 测试结果为:%s"%labelResult)
运行结果: