ID3,C4.5算法缺点
ID3决策树可以有多个分支,但是不能处理特征值为连续的情况。
在ID3中,每次根据“最大信息熵增益”选取当前最佳的特征来分割数据,并按照该特征的所有取值来切分,
也就是说如果一个特征有4种取值,数据将被切分4份,一旦按某特征切分后,该特征在之后的算法执行中,
将不再起作用,所以有观点认为这种切分方式过于迅速。
C4.5中是用信息增益比率(gain ratio)来作为选择分支的准则。和ID3一样,C4.5算法分类结果存在过拟合。
为了解决过拟合问题,这里介绍一种新的算法CART。
CART(classification and regression tree)
CART由特征选择、树的生成及剪枝组成,既可以用于分类也可以用于回归。
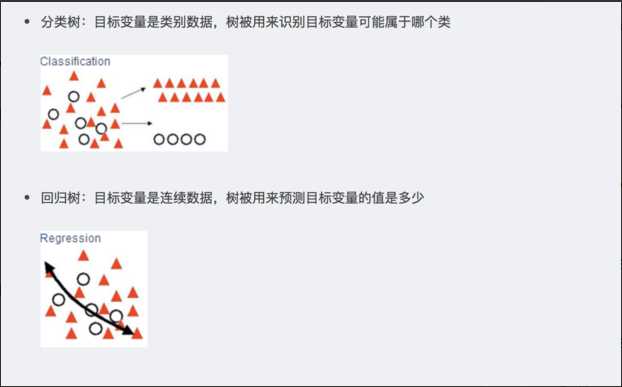
分类:如晴天/阴天/雨天、用户性别、邮件是否是垃圾邮件;
回归:预测实数值,如明天的温度、用户的年龄等;
CART决策树的生成就是递归地构建二叉决策树的过程,对分类、以及剪枝采用信息增益最大化准则,这里信息增益采用的基尼指数公式,
当然也可以使用ID3的信息熵公式算法。
基尼指数
分类问题中,假设有K个类别,样本点属于第类的概率为
,则概率分布的基尼指数定义为
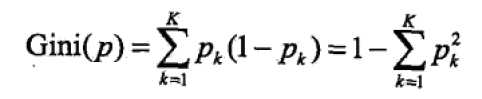
对于给定的样本集合D,其基尼指数为
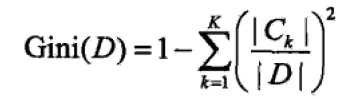
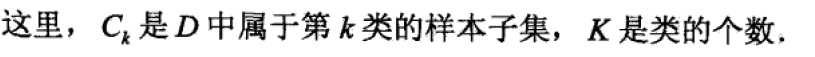
生成的二叉树类似于
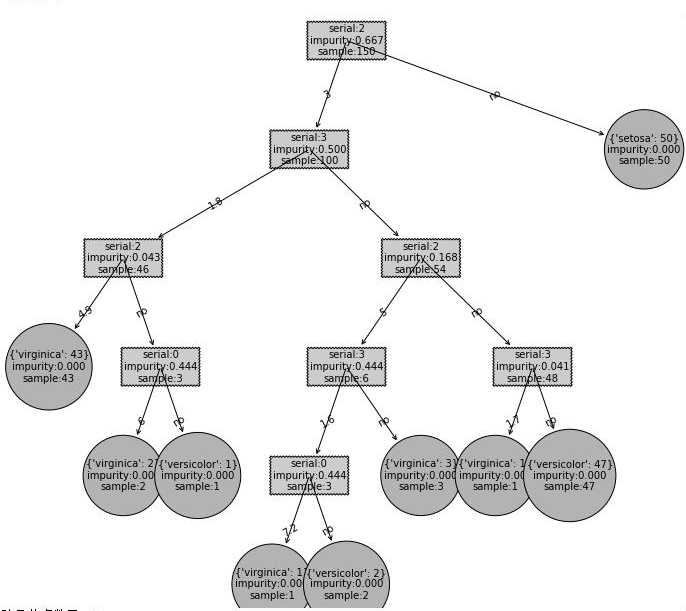
剪枝算法
CART剪枝算法从“完全生长”的决策树的底端减去一些子树,是决策树变小(模型变简单),从而能够对未知数据有更准确的预测,防止过拟合。
后剪枝需要从训练集生成一棵完整的决策树,然后自底向上对非叶子节点进行考察。利用信息增益与给定阈值判断是否将该节点对应的子树替换成叶节点。
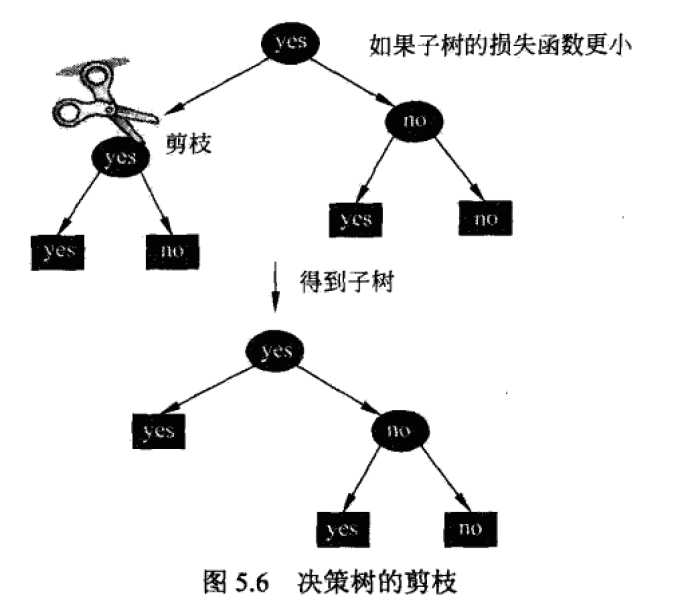
代码实现
每个函数算法我基本上都做了较为详细的注释,希望对大家理解算法原理有所帮助。
因为没有上传附件功能,只能用笨办法。将原始数据复制到本地txt文件中,然后将txt格式改成dataSet.csv文件,
放在代码文件所在的路径。



1 SepalLength,SepalWidth,PetalLength,PetalWidth,Name 2 5.1,3.5,1.4,0.2,setosa 3 4.9,3,1.4,0.2,setosa 4 4.7,3.2,1.3,0.2,setosa 5 4.6,3.1,1.5,0.2,setosa 6 5,3.6,1.4,0.2,setosa 7 5.4,3.9,1.7,0.4,setosa 8 4.6,3.4,1.4,0.3,setosa 9 5,3.4,1.5,0.2,setosa 10 4.4,2.9,1.4,0.2,setosa 11 4.9,3.1,1.5,0.1,setosa 12 5.4,3.7,1.5,0.2,setosa 13 4.8,3.4,1.6,0.2,setosa 14 4.8,3,1.4,0.1,setosa 15 4.3,3,1.1,0.1,setosa 16 5.8,4,1.2,0.2,setosa 17 5.7,4.4,1.5,0.4,setosa 18 5.4,3.9,1.3,0.4,setosa 19 5.1,3.5,1.4,0.3,setosa 20 5.7,3.8,1.7,0.3,setosa 21 5.1,3.8,1.5,0.3,setosa 22 5.4,3.4,1.7,0.2,setosa 23 5.1,3.7,1.5,0.4,setosa 24 4.6,3.6,1,0.2,setosa 25 5.1,3.3,1.7,0.5,setosa 26 4.8,3.4,1.9,0.2,setosa 27 5,3,1.6,0.2,setosa 28 5,3.4,1.6,0.4,setosa 29 5.2,3.5,1.5,0.2,setosa 30 5.2,3.4,1.4,0.2,setosa 31 4.7,3.2,1.6,0.2,setosa 32 4.8,3.1,1.6,0.2,setosa 33 5.4,3.4,1.5,0.4,setosa 34 5.2,4.1,1.5,0.1,setosa 35 5.5,4.2,1.4,0.2,setosa 36 4.9,3.1,1.5,0.1,setosa 37 5,3.2,1.2,0.2,setosa 38 5.5,3.5,1.3,0.2,setosa 39 4.9,3.1,1.5,0.1,setosa 40 4.4,3,1.3,0.2,setosa 41 5.1,3.4,1.5,0.2,setosa 42 5,3.5,1.3,0.3,setosa 43 4.5,2.3,1.3,0.3,setosa 44 4.4,3.2,1.3,0.2,setosa 45 5,3.5,1.6,0.6,setosa 46 5.1,3.8,1.9,0.4,setosa 47 4.8,3,1.4,0.3,setosa 48 5.1,3.8,1.6,0.2,setosa 49 4.6,3.2,1.4,0.2,setosa 50 5.3,3.7,1.5,0.2,setosa 51 5,3.3,1.4,0.2,setosa 52 7,3.2,4.7,1.4,versicolor 53 6.4,3.2,4.5,1.5,versicolor 54 6.9,3.1,4.9,1.5,versicolor 55 5.5,2.3,4,1.3,versicolor 56 6.5,2.8,4.6,1.5,versicolor 57 5.7,2.8,4.5,1.3,versicolor 58 6.3,3.3,4.7,1.6,versicolor 59 4.9,2.4,3.3,1,versicolor 60 6.6,2.9,4.6,1.3,versicolor 61 5.2,2.7,3.9,1.4,versicolor 62 5,2,3.5,1,versicolor 63 5.9,3,4.2,1.5,versicolor 64 6,2.2,4,1,versicolor 65 6.1,2.9,4.7,1.4,versicolor 66 5.6,2.9,3.6,1.3,versicolor 67 6.7,3.1,4.4,1.4,versicolor 68 5.6,3,4.5,1.5,versicolor 69 5.8,2.7,4.1,1,versicolor 70 6.2,2.2,4.5,1.5,versicolor 71 5.6,2.5,3.9,1.1,versicolor 72 5.9,3.2,4.8,1.8,versicolor 73 6.1,2.8,4,1.3,versicolor 74 6.3,2.5,4.9,1.5,versicolor 75 6.1,2.8,4.7,1.2,versicolor 76 6.4,2.9,4.3,1.3,versicolor 77 6.6,3,4.4,1.4,versicolor 78 6.8,2.8,4.8,1.4,versicolor 79 6.7,3,5,1.7,versicolor 80 6,2.9,4.5,1.5,versicolor 81 5.7,2.6,3.5,1,versicolor 82 5.5,2.4,3.8,1.1,versicolor 83 5.5,2.4,3.7,1,versicolor 84 5.8,2.7,3.9,1.2,versicolor 85 6,2.7,5.1,1.6,versicolor 86 5.4,3,4.5,1.5,versicolor 87 6,3.4,4.5,1.6,versicolor 88 6.7,3.1,4.7,1.5,versicolor 89 6.3,2.3,4.4,1.3,versicolor 90 5.6,3,4.1,1.3,versicolor 91 5.5,2.5,4,1.3,versicolor 92 5.5,2.6,4.4,1.2,versicolor 93 6.1,3,4.6,1.4,versicolor 94 5.8,2.6,4,1.2,versicolor 95 5,2.3,3.3,1,versicolor 96 5.6,2.7,4.2,1.3,versicolor 97 5.7,3,4.2,1.2,versicolor 98 5.7,2.9,4.2,1.3,versicolor 99 6.2,2.9,4.3,1.3,versicolor 100 5.1,2.5,3,1.1,versicolor 101 5.7,2.8,4.1,1.3,versicolor 102 6.3,3.3,6,2.5,virginica 103 5.8,2.7,5.1,1.9,virginica 104 7.1,3,5.9,2.1,virginica 105 6.3,2.9,5.6,1.8,virginica 106 6.5,3,5.8,2.2,virginica 107 7.6,3,6.6,2.1,virginica 108 4.9,2.5,4.5,1.7,virginica 109 7.3,2.9,6.3,1.8,virginica 110 6.7,2.5,5.8,1.8,virginica 111 7.2,3.6,6.1,2.5,virginica 112 6.5,3.2,5.1,2,virginica 113 6.4,2.7,5.3,1.9,virginica 114 6.8,3,5.5,2.1,virginica 115 5.7,2.5,5,2,virginica 116 5.8,2.8,5.1,2.4,virginica 117 6.4,3.2,5.3,2.3,virginica 118 6.5,3,5.5,1.8,virginica 119 7.7,3.8,6.7,2.2,virginica 120 7.7,2.6,6.9,2.3,virginica 121 6,2.2,5,1.5,virginica 122 6.9,3.2,5.7,2.3,virginica 123 5.6,2.8,4.9,2,virginica 124 7.7,2.8,6.7,2,virginica 125 6.3,2.7,4.9,1.8,virginica 126 6.7,3.3,5.7,2.1,virginica 127 7.2,3.2,6,1.8,virginica 128 6.2,2.8,4.8,1.8,virginica 129 6.1,3,4.9,1.8,virginica 130 6.4,2.8,5.6,2.1,virginica 131 7.2,3,5.8,1.6,virginica 132 7.4,2.8,6.1,1.9,virginica 133 7.9,3.8,6.4,2,virginica 134 6.4,2.8,5.6,2.2,virginica 135 6.3,2.8,5.1,1.5,virginica 136 6.1,2.6,5.6,1.4,virginica 137 7.7,3,6.1,2.3,virginica 138 6.3,3.4,5.6,2.4,virginica 139 6.4,3.1,5.5,1.8,virginica 140 6,3,4.8,1.8,virginica 141 6.9,3.1,5.4,2.1,virginica 142 6.7,3.1,5.6,2.4,virginica 143 6.9,3.1,5.1,2.3,virginica 144 5.8,2.7,5.1,1.9,virginica 145 6.8,3.2,5.9,2.3,virginica 146 6.7,3.3,5.7,2.5,virginica 147 6.7,3,5.2,2.3,virginica 148 6.3,2.5,5,1.9,virginica 149 6.5,3,5.2,2,virginica 150 6.2,3.4,5.4,2.3,virginica 151 5.9,3,5.1,1.8,virginica
1 # -*- coding: utf-8 -*- 2 """ 3 Created on Tue Aug 14 17:36:57 2018 4 5 @author: weixw 6 """ 7 import numpy as np 8 #定义树结构,采用的二叉树,左子树:条件为true,右子树:条件为false 9 #leftBranch:左子树结点 10 #rightBranch:右子树结点 11 #col:信息增益最大时对应的列索引 12 #value:最优列索引下,划分数据类型的值 13 #results:分类结果 14 #summary:信息增益最大时样本信息 15 #data:信息增益最大时数据集 16 class Tree: 17 def __init__(self, leftBranch =None, rightBranch= None, col =-1, value =None, results =None, summary =None, data =None): 18 self.leftBranch = leftBranch 19 self.rightBranch = rightBranch 20 self.col = col 21 self.value = value 22 self.results = results 23 self.summary = summary 24 self.data = data 25 26 def __str__(self): 27 print(u"列号:%d"%self.col) 28 print(u"列划分值:%s"%self.value) 29 print(u"样本信息:%s"%self.summary) 30 return "" 31 32 33 34 #划分数据集 35 def splitDataSet(dataSet, value, column): 36 leftList=[] 37 rightList=[] 38 #判断value是否是数值型 39 if(isinstance(value, int) or isinstance(value, float)): 40 #遍历每一行数据 41 for rowData in dataSet: 42 #如果某一行指定列值>=value,则将该行数据保存在leftList中,否则保存在rightList中 43 if(rowData[column] >= value): 44 leftList.append(rowData) 45 else: 46 rightList.append(rowData) 47 #value为标称型 48 else: 49 #遍历每一行数据 50 for rowData in dataSet: 51 #如果某一行指定列值==value,则将该行数据保存在leftList中,否则保存在rightList中 52 if(rowData[column] == value): 53 leftList.append(rowData) 54 else: 55 rightList.append(rowData) 56 return leftList, rightList 57 58 #统计标签类每个样本个数 59 ‘‘‘ 60 该函数是计算gini值的辅助函数,假设输入的dataSet为为[‘A‘, ‘B‘, ‘C‘, ‘A‘, ‘A‘, ‘D‘], 61 则输出为[‘A‘:3,‘ B‘:1, ‘C‘:1, ‘D‘:1],这样分类统计dataSet中每个类别的数量 62 ‘‘‘ 63 def calculateDiffCount(dataSet): 64 results = {} 65 for data in dataSet: 66 # data[-1] 是数据集最后一列,也就是标签类 67 if data[-1] not in results: 68 results.setdefault(data[-1], 1) 69 else: 70 results[data[-1]] += 1 71 return results 72 73 74 #基尼指数公式实现 75 def gini(dataSet): 76 # 计算gini的值(Calculate GINI) 77 #数据所有行 78 length = len(dataSet) 79 #标签列合并后的数据集 80 results = calculateDiffCount(dataSet) 81 imp = 0.0 82 for i in results: 83 imp += results[i] / length * results[i] / length 84 return 1 - imp 85 86 #生成决策树 87 ‘‘‘算法步骤‘‘‘ 88 ‘‘‘根据训练数据集,从根结点开始,递归地对每个结点进行以下操作,构建二叉决策树: 89 1 设结点的训练数据集为D,计算现有特征对该数据集的信息增益。此时,对每一个特征A,对其可能取的 90 每个值a,根据样本点对A >=a 的测试为“是”或“否”将D分割成D1和D2两部分,利用基尼指数计算信息增益。 91 2 在所有可能的特征A以及它们所有可能的切分点a中,选择信息增益最大的特征及其对应的切分点作为最优特征 92 与最优切分点,依据最优特征与最优切分点,从现结点生成两个子结点,将训练数据集依特征分配到两个子结点中去。 93 3 对两个子结点递归地调用1,2,直至满足停止条件。 94 4 生成CART决策树。 95 ‘‘‘‘‘‘‘‘‘‘‘‘‘‘‘‘‘‘‘‘‘ 96 #evaluationFunc= gini :采用的是基尼指数来衡量信息关注度 97 def buildDecisionTree(dataSet, evaluationFunc = gini): 98 #计算基础数据集的基尼指数 99 baseGain = evaluationFunc(dataSet) 100 #计算每一行的长度(也就是列总数) 101 columnLength = len(dataSet[0]) 102 #计算数据项总数 103 rowLength = len(dataSet) 104 #初始化 105 bestGain = 0.0 #信息增益最大值 106 bestValue = None #信息增益最大时的列索引,以及划分数据集的样本值 107 bestSet = None # 信息增益最大,听过样本值划分数据集后的数据子集 108 #标签列除外(最后一列),遍历每一列数据 109 for col in range(columnLength -1): 110 #获取指定列数据 111 colSet = [example[col] for example in dataSet] 112 #获取指定列样本唯一值 113 uniqueColSet = set(colSet) 114 #遍历指定列样本集 115 for value in uniqueColSet: 116 #分割数据集 117 leftDataSet, rightDataSet = splitDataSet(dataSet, value, col) 118 #计算子数据集概率,python3 "/"除号结果为小数 119 prop = len(leftDataSet)/rowLength 120 #计算信息增益 121 infoGain = baseGain - prop*evaluationFunc(leftDataSet) - (1 - prop)*evaluationFunc(rightDataSet) 122 #找出信息增益最大时的列索引,value,数据子集 123 if(infoGain > bestGain): 124 bestGain = infoGain 125 bestValue = (col, value) 126 bestSet = (leftDataSet, rightDataSet) 127 #结点信息 128 # nodeDescription = {‘impurity:%.3f‘%baseGain,‘sample:%d‘%rowLength} 129 nodeDescription = {‘impurity‘: ‘%.3f‘ % baseGain, ‘sample‘: ‘%d‘ % rowLength} 130 #数据行标签类别不一致,可以继续分类 131 #递归必须有终止条件 132 if bestGain > 0: 133 #递归,生成左子树结点,右子树结点 134 leftBranch = buildDecisionTree(bestSet[0], evaluationFunc) 135 rightBranch = buildDecisionTree(bestSet[1], evaluationFunc) 136 return Tree(leftBranch = leftBranch, rightBranch = rightBranch, col = bestValue[0] 137 , value = bestValue[1], summary = nodeDescription, data = bestSet) 138 else: 139 #数据行标签类别都相同,分类终止 140 return Tree(results = calculateDiffCount(dataSet), summary = nodeDescription, data = dataSet) 141 142 def createTree(dataSet, evaluationFunc=gini): 143 # 递归建立决策树, 当gain=0,时停止回归 144 #计算基础数据集的基尼指数 145 baseGain = evaluationFunc(dataSet) 146 #计算每一行的长度(也就是列总数) 147 columnLength = len(dataSet[0]) 148 #计算数据项总数 149 rowLength = len(dataSet) 150 #初始化 151 bestGain = 0.0 #信息增益最大值 152 bestValue = None #信息增益最大时的列索引,以及划分数据集的样本值 153 bestSet = None # 信息增益最大,听过样本值划分数据集后的数据子集 154 #标签列除外(最后一列),遍历每一列数据 155 for col in range(columnLength -1): 156 #获取指定列数据 157 colSet = [example[col] for example in dataSet] 158 #获取指定列样本唯一值 159 uniqueColSet = set(colSet) 160 #遍历指定列样本集 161 for value in uniqueColSet: 162 #分割数据集 163 leftDataSet, rightDataSet = splitDataSet(dataSet, value, col) 164 #计算子数据集概率,python3 "/"除号结果为小数 165 prop = len(leftDataSet)/rowLength 166 #计算信息增益 167 infoGain = baseGain - prop*evaluationFunc(leftDataSet) - (1 - prop)*evaluationFunc(rightDataSet) 168 #找出信息增益最大时的列索引,value,数据子集 169 if(infoGain > bestGain): 170 bestGain = infoGain 171 bestValue = (col, value) 172 bestSet = (leftDataSet, rightDataSet) 173 174 impurity = u‘%.3f‘ % baseGain 175 sample = ‘%d‘ % rowLength 176 177 if bestGain > 0: 178 bestFeatLabel =u‘serial:%s\nimpurity:%s\nsample:%s‘%(bestValue[0], impurity,sample) 179 myTree = {bestFeatLabel:{}} 180 myTree[bestFeatLabel][bestValue[1]] = createTree(bestSet[0], evaluationFunc) 181 myTree[bestFeatLabel][‘no‘] = createTree(bestSet[1], evaluationFunc) 182 return myTree 183 else:#递归需要返回值 184 bestFeatValue =u‘%s\nimpurity:%s\nsample:%s‘%(str(calculateDiffCount(dataSet)), impurity,sample) 185 return bestFeatValue 186 187 #分类测试: 188 ‘‘‘根据给定测试数据遍历二叉树,找到符合条件的叶子结点‘‘‘ 189 ‘‘‘例如测试数据为[5.9,3,4.2,1.75],按照训练数据生成的决策树分类的顺序为 190 第2列对应测试数据4.2 =>与决策树根结点(2)的value(3)比较,>=3则遍历左子树,否则遍历右子树, 191 叶子结点就是结果‘‘‘ 192 def classify(data, tree): 193 #判断是否是叶子结点,是就返回叶子结点相关信息,否就继续遍历 194 if tree.results != None: 195 return u"%s\n%s"%(tree.results, tree.summary) 196 else: 197 branch = None 198 v = data[tree.col] 199 #数值型数据 200 if isinstance(v, int) or isinstance(v, float): 201 if v >= tree.value: 202 branch = tree.leftBranch 203 else: 204 branch = tree.rightBranch 205 else:#标称型数据 206 if v == tree.value: 207 branch = tree.leftBranch 208 else: 209 branch = tree.rightBranch 210 return classify(data, branch) 211 212 def loadCSV(fileName): 213 def convertTypes(s): 214 s = s.strip() 215 try: 216 return float(s) if ‘.‘ in s else int(s) 217 except ValueError: 218 return s 219 data = np.loadtxt(fileName, dtype=‘str‘, delimiter=‘,‘) 220 data = data[1:, :] 221 dataSet =([[convertTypes(item) for item in row] for row in data]) 222 return dataSet 223 224 #多数表决器 225 #列中相同值数量最多为结果 226 def majorityCnt(classList): 227 import operator 228 classCounts = {} 229 for value in classList: 230 if(value not in classCounts.keys()): 231 classCounts[value] = 0 232 classCounts[value] +=1 233 sortedClassCount = sorted(classCounts.items(),key = operator.itemgetter(1),reverse =True) 234 return sortedClassCount[0][0] 235 236 #剪枝算法(前序遍历方式:根=>左子树=>右子树) 237 ‘‘‘算法步骤 238 1. 从二叉树的根结点出发,递归调用剪枝算法,直至左、右结点都是叶子结点 239 2. 计算父节点(子结点为叶子结点)的信息增益infoGain 240 3. 如果infoGain < miniGain,则选取样本多的叶子结点来取代父节点 241 4. 循环1,2,3,直至遍历完整棵树 242 ‘‘‘‘‘‘‘‘‘ 243 def prune(tree, miniGain, evaluationFunc = gini): 244 print(u"当前结点信息:") 245 print(str(tree)) 246 #如果当前结点的左子树不是叶子结点,遍历左子树 247 if(tree.leftBranch.results == None): 248 print(u"左子树结点信息:") 249 print(str(tree.leftBranch)) 250 prune(tree.leftBranch, miniGain, evaluationFunc) 251 #如果当前结点的右子树不是叶子结点,遍历右子树 252 if(tree.rightBranch.results == None): 253 print(u"右子树结点信息:") 254 print(str(tree.rightBranch)) 255 prune(tree.rightBranch, miniGain, evaluationFunc) 256 #左子树和右子树都是叶子结点 257 if(tree.leftBranch.results != None and tree.rightBranch.results != None): 258 #计算左叶子结点数据长度 259 leftLen = len(tree.leftBranch.data) 260 #计算右叶子结点数据长度 261 rightLen = len(tree.rightBranch.data) 262 #计算左叶子结点概率 263 leftProp = leftLen/(leftLen + rightLen) 264 #计算该结点的信息增益(子类是叶子结点) 265 infoGain = (evaluationFunc(tree.leftBranch.data + tree.rightBranch.data) - 266 leftProp*evaluationFunc(tree.leftBranch.data) - (1 - leftProp)*evaluationFunc(tree.rightBranch.data)) 267 #信息增益 < 给定阈值,则说明叶子结点与其父结点特征差别不大,可以剪枝 268 if(infoGain < miniGain): 269 #合并左右叶子结点数据 270 dataSet = tree.leftBranch.data + tree.rightBranch.data 271 #获取标签列 272 classLabels = [example[-1] for example in dataSet] 273 #找到样本最多的标签值 274 keyLabel = majorityCnt(classLabels) 275 #判断标签值是左右叶子结点哪一个 276 if keyLabel in tree.leftBranch.results: 277 #左叶子结点取代父结点 278 tree.data = tree.leftBranch.data 279 tree.results = tree.leftBranch.results 280 tree.summary = tree.leftBranch.summary 281 else: 282 #右叶子结点取代父结点 283 tree.data = tree.rightBranch.data 284 tree.results = tree.rightBranch.results 285 tree.summary = tree.rightBranch.summary 286 tree.leftBranch = None 287 tree.rightBranch = None 288 289 290
1 ‘‘‘ 2 Created on Oct 14, 2010 3 4 @author: Peter Harrington 5 ‘‘‘ 6 import matplotlib.pyplot as plt 7 8 decisionNode = dict(boxstyle="sawtooth", fc="0.8") 9 leafNode = dict(boxstyle="circle", fc="0.7") 10 arrow_args = dict(arrowstyle="<-") 11 12 #获取树的叶子节点 13 def getNumLeafs(myTree): 14 numLeafs = 0 15 #dict转化为list 16 firstSides = list(myTree.keys()) 17 firstStr = firstSides[0] 18 secondDict = myTree[firstStr] 19 for key in secondDict.keys(): 20 #判断是否是叶子节点(通过类型判断,子类不存在,则类型为str;子类存在,则为dict) 21 if type(secondDict[key]).__name__==‘dict‘:#test to see if the nodes are dictonaires, if not they are leaf nodes 22 numLeafs += getNumLeafs(secondDict[key]) 23 else: numLeafs +=1 24 return numLeafs 25 26 #获取树的层数 27 def getTreeDepth(myTree): 28 maxDepth = 0 29 #dict转化为list 30 firstSides = list(myTree.keys()) 31 firstStr = firstSides[0] 32 secondDict = myTree[firstStr] 33 for key in secondDict.keys(): 34 if type(secondDict[key]).__name__==‘dict‘:#test to see if the nodes are dictonaires, if not they are leaf nodes 35 thisDepth = 1 + getTreeDepth(secondDict[key]) 36 else: thisDepth = 1 37 if thisDepth > maxDepth: maxDepth = thisDepth 38 return maxDepth 39 40 def plotNode(nodeTxt, centerPt, parentPt, nodeType): 41 createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords=‘axes fraction‘, 42 xytext=centerPt, textcoords=‘axes fraction‘, 43 va="center", ha="center", bbox=nodeType, arrowprops=arrow_args ) 44 45 def plotMidText(cntrPt, parentPt, txtString): 46 xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0] 47 yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1] 48 createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30) 49 50 def plotTree(myTree, parentPt, nodeTxt):#if the first key tells you what feat was split on 51 numLeafs = getNumLeafs(myTree) #this determines the x width of this tree 52 depth = getTreeDepth(myTree) 53 firstSides = list(myTree.keys()) 54 firstStr = firstSides[0] #the text label for this node should be this 55 cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff) 56 plotMidText(cntrPt, parentPt, nodeTxt) 57 plotNode(firstStr, cntrPt, parentPt, decisionNode) 58 secondDict = myTree[firstStr] 59 plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD 60 for key in secondDict.keys(): 61 if type(secondDict[key]).__name__==‘dict‘:#test to see if the nodes are dictonaires, if not they are leaf nodes 62 plotTree(secondDict[key],cntrPt,str(key)) #recursion 63 else: #it‘s a leaf node print the leaf node 64 plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW 65 plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode) 66 plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key)) 67 plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD 68 #if you do get a dictonary you know it‘s a tree, and the first element will be another dict 69 #绘制决策树 样例1 70 def createPlot(inTree): 71 fig = plt.figure(1, facecolor=‘white‘) 72 fig.clf() 73 axprops = dict(xticks=[], yticks=[]) 74 createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) #no ticks 75 #createPlot.ax1 = plt.subplot(111, frameon=False) #ticks for demo puropses 76 #宽,高间距 77 plotTree.totalW = float(getNumLeafs(inTree))-3 78 plotTree.totalD = float(getTreeDepth(inTree))-2 79 # plotTree.totalW = float(getNumLeafs(inTree)) 80 # plotTree.totalD = float(getTreeDepth(inTree)) 81 plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0; 82 plotTree(inTree, (0.95,1.0), ‘‘) 83 plt.show() 84 85 #绘制决策树 样例2 86 def createPlot1(inTree): 87 fig = plt.figure(1, facecolor=‘white‘) 88 fig.clf() 89 axprops = dict(xticks=[], yticks=[]) 90 createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) #no ticks 91 #createPlot.ax1 = plt.subplot(111, frameon=False) #ticks for demo puropses 92 #宽,高间距 93 plotTree.totalW = float(getNumLeafs(inTree))-4.5 94 plotTree.totalD = float(getTreeDepth(inTree)) -3 95 plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0; 96 plotTree(inTree, (1.0,1.0), ‘‘) 97 plt.show() 98 99 #绘制树的根节点和叶子节点(根节点形状:长方形,叶子节点:椭圆形) 100 #def createPlot(): 101 # fig = plt.figure(1, facecolor=‘white‘) 102 # fig.clf() 103 # createPlot.ax1 = plt.subplot(111, frameon=False) #ticks for demo puropses 104 # plotNode(‘a decision node‘, (0.5, 0.1), (0.1, 0.5), decisionNode) 105 # plotNode(‘a leaf node‘, (0.8, 0.1), (0.3, 0.8), leafNode) 106 # plt.show() 107 108 def retrieveTree(i): 109 listOfTrees =[{‘no surfacing‘: {0: ‘no‘, 1: {‘flippers‘: {0: ‘no‘, 1: ‘yes‘}}}}, 110 {‘no surfacing‘: {0: ‘no‘, 1: {‘flippers‘: {0: {‘head‘: {0: ‘no‘, 1: ‘yes‘}}, 1: ‘no‘}}}} 111 ] 112 return listOfTrees[i] 113 114 #thisTree = retrieveTree(0) 115 #createPlot(thisTree) 116 #createPlot() 117 #myTree = retrieveTree(0) 118 #numLeafs =getNumLeafs(myTree) 119 #treeDepth =getTreeDepth(myTree) 120 #print(u"叶子节点数目:%d"% numLeafs) 121 #print(u"树深度:%d"%treeDepth)
1 # -*- coding: utf-8 -*- 2 """ 3 Created on Wed Aug 15 14:16:59 2018 4 5 @author: weixw 6 """ 7 import myCart as mc 8 if __name__ == ‘__main__‘: 9 import treePlotter as tp 10 dataSet = mc.loadCSV("dataSet.csv") 11 myTree = mc.createTree(dataSet, evaluationFunc=gini) 12 print(u"myTree:%s"%myTree) 13 #绘制决策树 14 print(u"绘制决策树:") 15 tp.createPlot1(myTree) 16 decisionTree = mc.buildDecisionTree(dataSet, evaluationFunc=gini) 17 testData = [5.9,3,4.2,1.75] 18 r = mc.classify(testData, decisionTree) 19 print(u"分类后测试结果:") 20 print(r) 21 print() 22 mc.prune(decisionTree, 0.4) 23 r1 = mc.classify(testData, decisionTree) 24 print(u"剪枝后测试结果:") 25 print(r1)
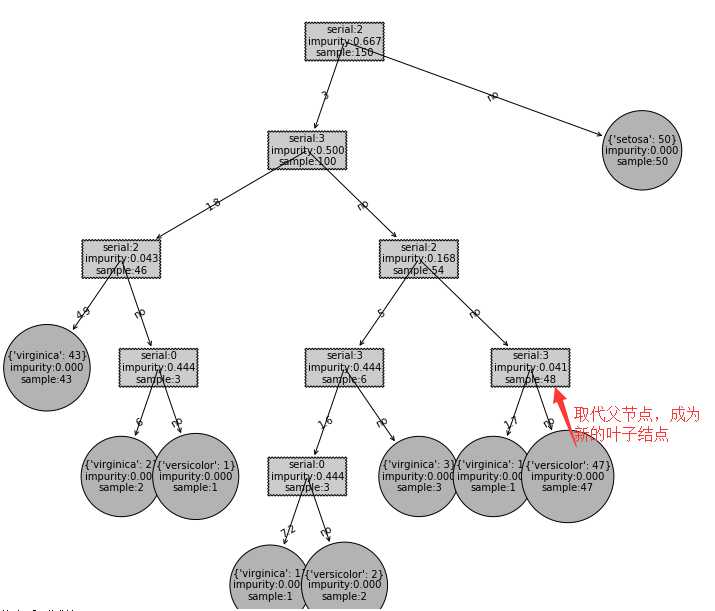
运行结果
为什么我要再写个createTree(dataSet, evaluationFunc=gini)函数,是因为绘制决策树createPlot1(myTree)输入参数需要是json结构数据。

将生成的决策树变为可视图形,这样更直观。
当然,也可以将自定义树对象信息打印出来,我在代码里已加入打印语句。
打印结果如下,因为屏幕的原因,没有全部粘贴出来,大家可以对照决策树绘制图,这样可以相互印证,加深理解。

在未做剪枝处理时的分类测试结果如下:
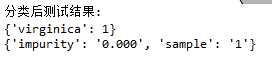
剪枝处理后的分类测试结果:
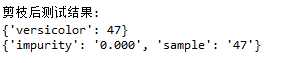
可以看出,{‘versicolor‘: 47}取代了父结点serial:3,成为新的叶子结点。