标签:应对 刷新 抓包工具 发送 定位 RoCE 结果 url编码 har
今日概要
因为在使用urllib模块的时候,会有诸多不便之处,总结如下:
就是一个基于网络请求的模块,可以用来模拟浏览器发请求。
基于requests模块的get请求
import requests
#1以字符串的形式指定url
url = ‘https://www.sogou.com/‘
#2发送请求
response = requests.get(url=url)#get返回一个响应对象
#3获取响应数据,响应数据在响应对象中
page_text = response.text#获取字符串形式的响应数据
print(page_text)
#4持久化存储
with open(‘./sogou.html‘,‘w‘,encoding=‘utf-8‘) as fp:
fp.write(page_text)#将字符串写入到文件中
需求:实现一个简易的网页采集器,即可以在搜狗中录入任何一个关键字,点击搜索,就能得到响应的页面,(爬取到任意关键字对应的页面源码数据)
如下操作:
搜索:Jay,获取其中的一部分url也能访问,
https://www.sogou.com/web?query=jay
#1.以字符串的形式指定url
url = ‘https://www.sogou.com/web?query=jay‘
#2.发送请求
response = requests.get(url=url)#返回一个响应对象
#3获取响应数据
page_taxt = response.text#获取字符串形式的响应数据
#4持久化存储
with open(‘./jay.html‘,‘w‘,encoding=‘utf-8‘) as fp:
fp.write(page_text)
当运行时出现以下结果

#1.以字符串的形式指定url
url = ‘https://www.sogou.com/web?query=jay‘
#2.发送请求
response = requests.get(url=url)#返回一个响应对象
#response.encoding #可以返回原始数据的编码格式
response.encoding = ‘utf-8‘ #将编码改成utf-8的形式
#3获取响应数据
page_text = response.text#获取字符串形式的响应数据
#4持久化存储
with open(‘./jay.html‘,‘w‘,encoding=‘utf-8‘) as fp:
fp.write(page_text)

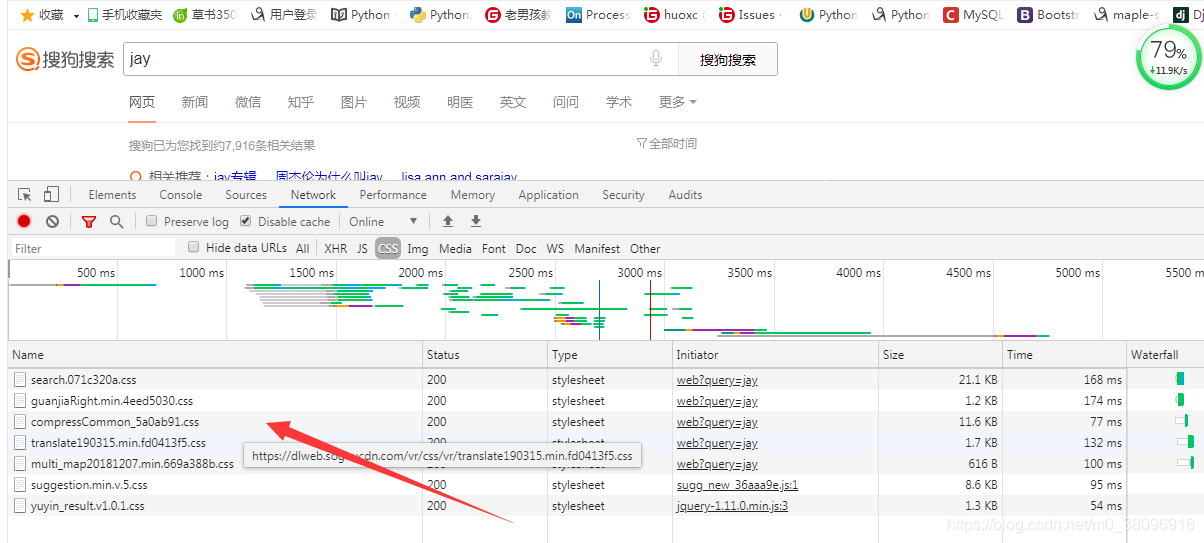
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36
现在正确的爬取方式如下:
#1.以字符串的形式指定url
url = ‘https://www.sogou.com/web?query=jay‘
#使用UA伪装
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36‘
}
#2.发送请求
response = requests.get(url=url,headers=headers)#返回一个响应对象
#response.encoding #可以返回原始数据的编码格式
response.encoding = ‘utf-8‘ #将编码改成utf-8的形式
#3获取响应数据
page_text = response.text#获取字符串形式的响应数据
#4持久化存储
with open(‘./jay.html‘,‘w‘,encoding=‘utf-8‘) as fp:
fp.write(page_text)
key = input("Enter a word:")
#将请求参数封装成键值对
params = {
‘query‘:key
}
#1.以字符串的形式指定url
url = ‘https://www.sogou.com/web?query=jay‘
#使用UA伪装
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36‘
}
#2.发送请求
response = requests.get(url=url,headers=headers,params=params)#返回一个响应对象
#response.encoding #可以返回原始数据的编码格式
response.encoding = ‘utf-8‘ #将编码改成utf-8的形式
#3获取响应数据
page_text = response.text#获取字符串形式的响应数据
fileName = key+‘.html‘
#4持久化存储
with open(‘fileName‘,‘w‘,encoding=‘utf-8‘) as fp:
fp.write(page_text)
print(fileName,‘爬取成功!!!‘)
什么是动态加载的数据:
右键——》审查元素——》NetWork——》刷新页面,发送请求
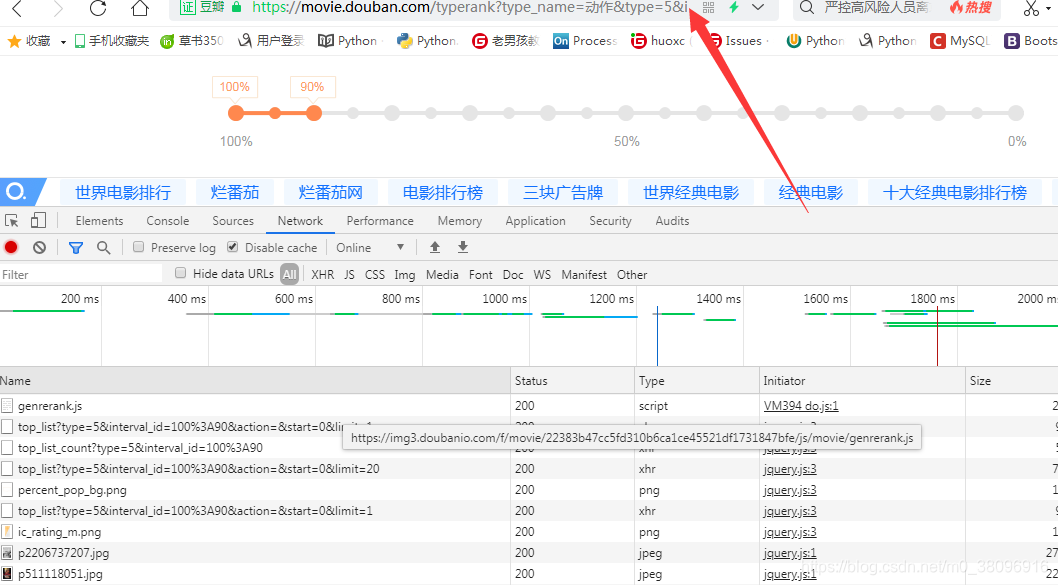
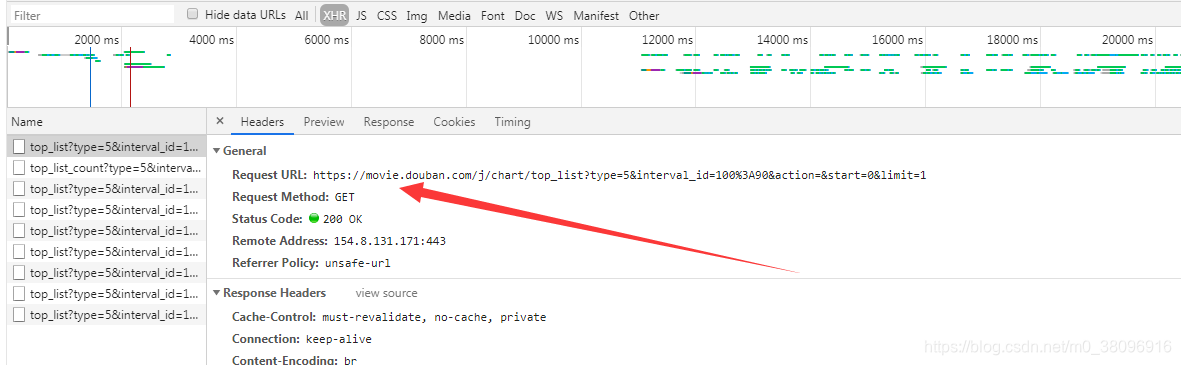
首先找到地址栏URL所对应的的数据包:
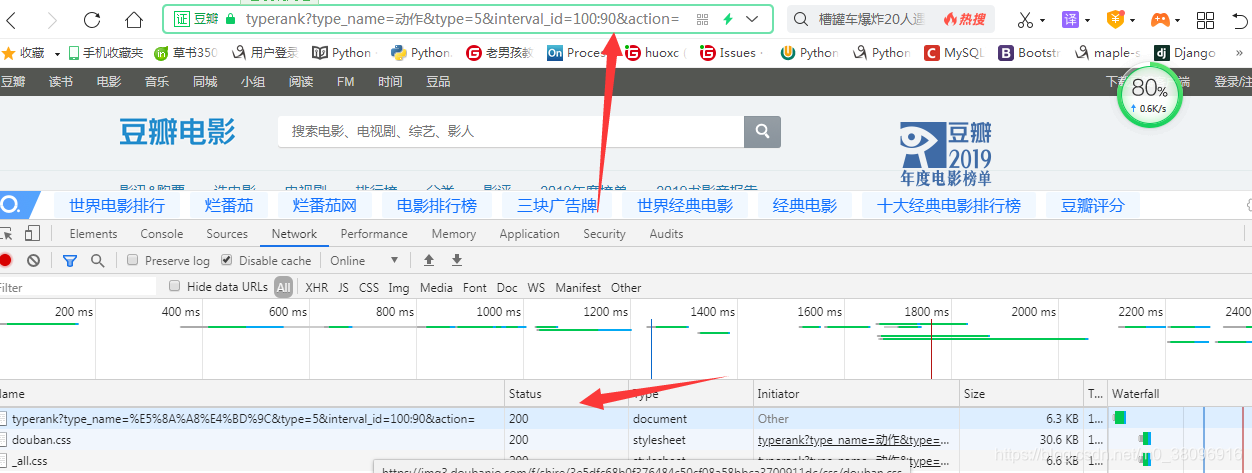
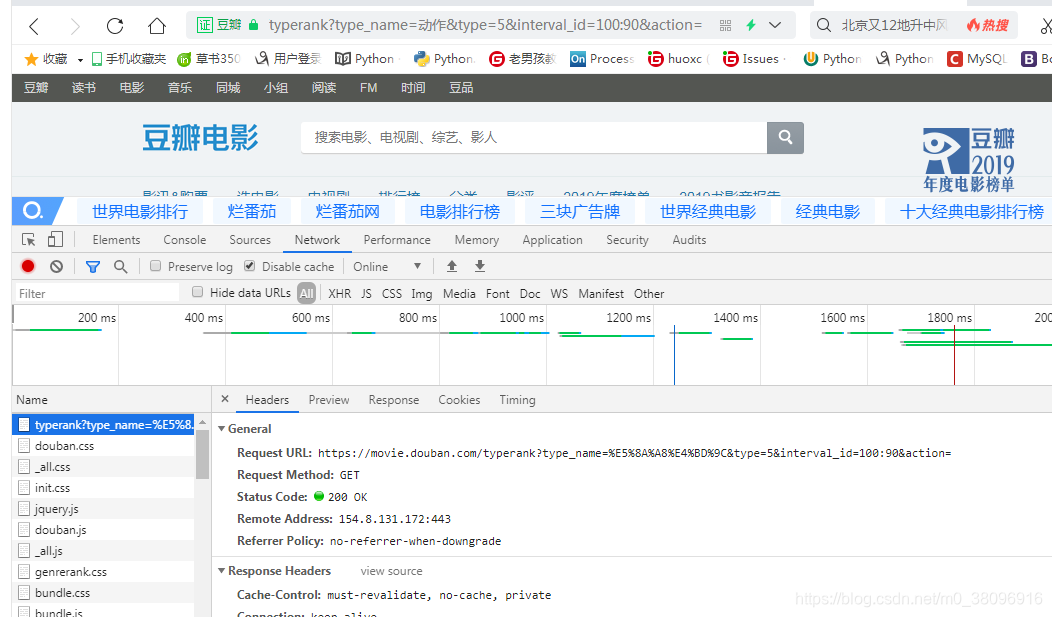
说明地址栏URL所对应的数据包,
其中response代表:requests.get()方法请求到的,页面数据,在这组数据中搜索,有没有《阿凡达》,用Ctrl+F搜索
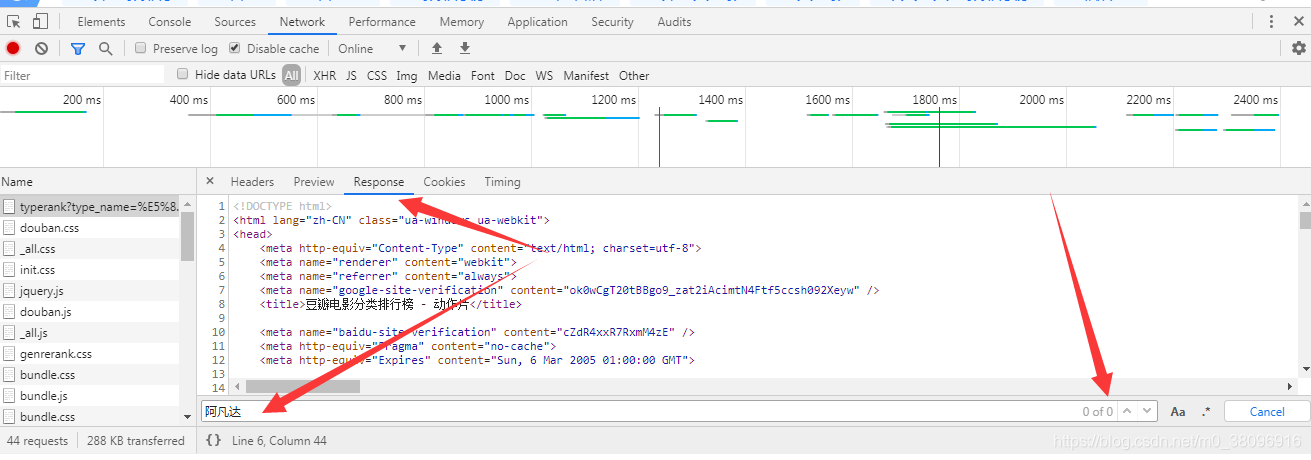
结果没有
all代表捕获全部数据,其中XHR代表,凡是发送ajax请求数据全部能捕获到
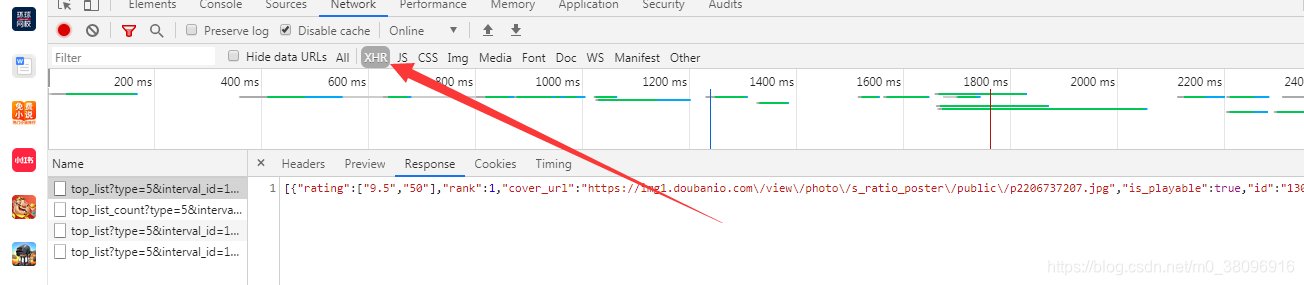
当滚轮向下滑动的时候,就会捕获到相应的数据
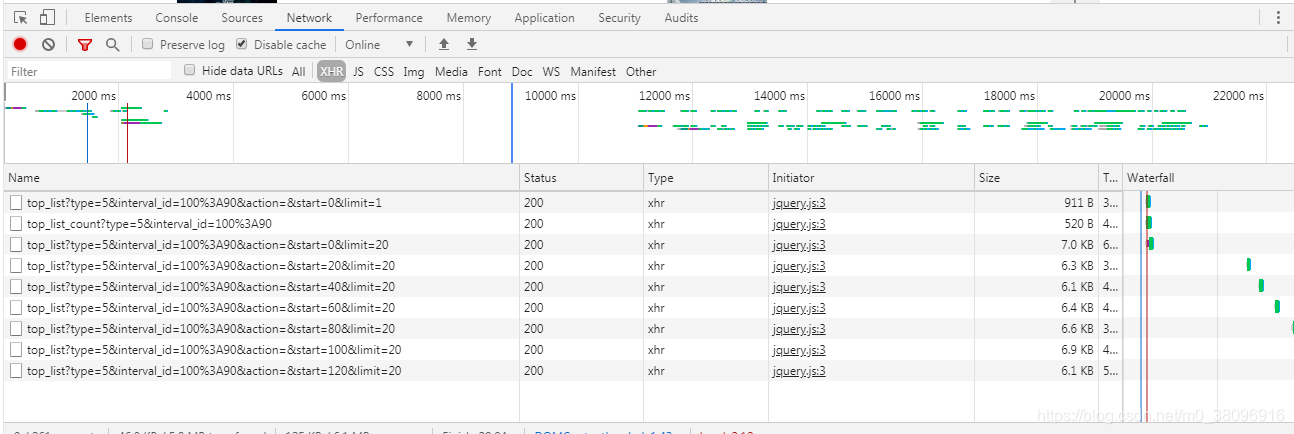
然后就会获取到对应的url
在response中是请求到的数据
其中所需要的数据是在哪一个数据包中,怎么找
选中其中的某一个,再Ctrl+f搜索就可以了
则会显示存在哪一个数据包中
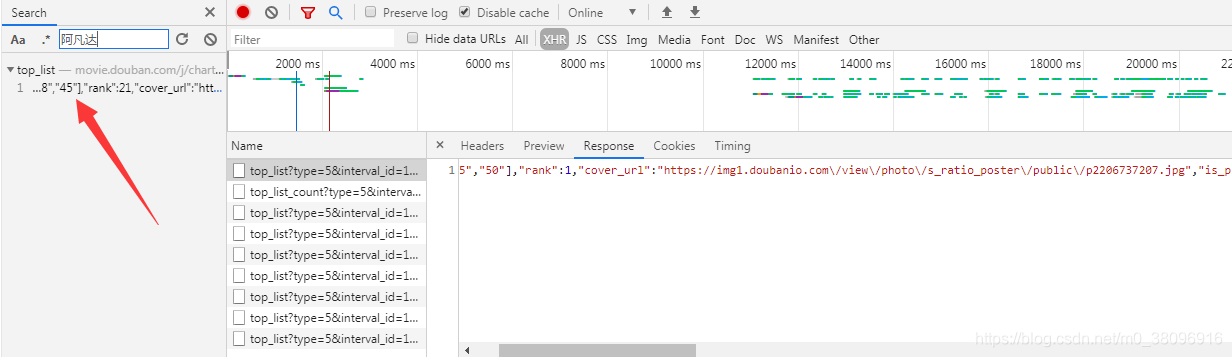
基于抓包工具做全局搜索,可以帮我们定位到动态加载的数据到底是存在于哪一一个数据
包中,定位到之后,就可以对该数据包的url进行请求发送捕获数据。
地址;

参数:
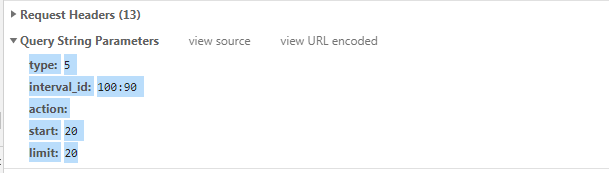
url = ‘https://movie.douban.com/j/chart/top_list‘
params = {
‘type‘: ‘5‘,
‘interval_id‘: ‘100:90‘,
‘action‘: ‘‘,
‘start‘: ‘20‘,
‘limit‘: ‘20‘,
}
#使用UA伪装
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36‘
}
#返回的数据为json字符串,当用.json时返回列表对象
data_list = requests.get(url=url,headers=headers,params=params).json()
#做解析
for dic in data_list:
title = dic[‘title‘]
score = dic[‘score‘]
print(title,score)
问题:怎么判断是json数据;
需求:-
http: //www.kfc.com.cn/kfccda/storelist/index.aspx
将北京所有肯德基餐厅的位置信息进行爬取
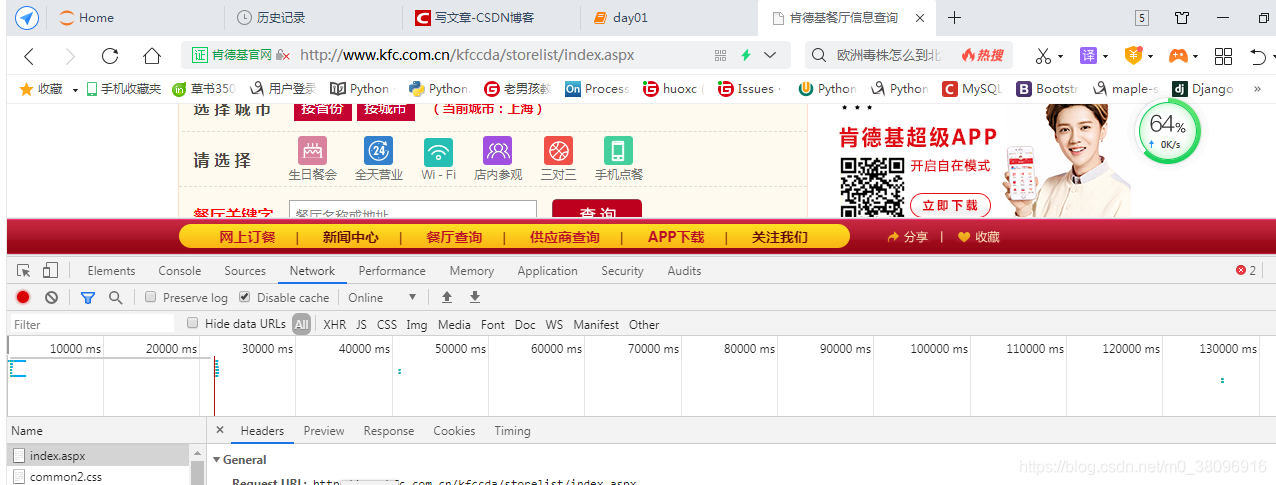
2:判断是不是动态加载的,怎么检测,打开抓包工具;
做一个局部搜索,如果搜不到,那就意味着数据是动态加载的
首先加载数据:
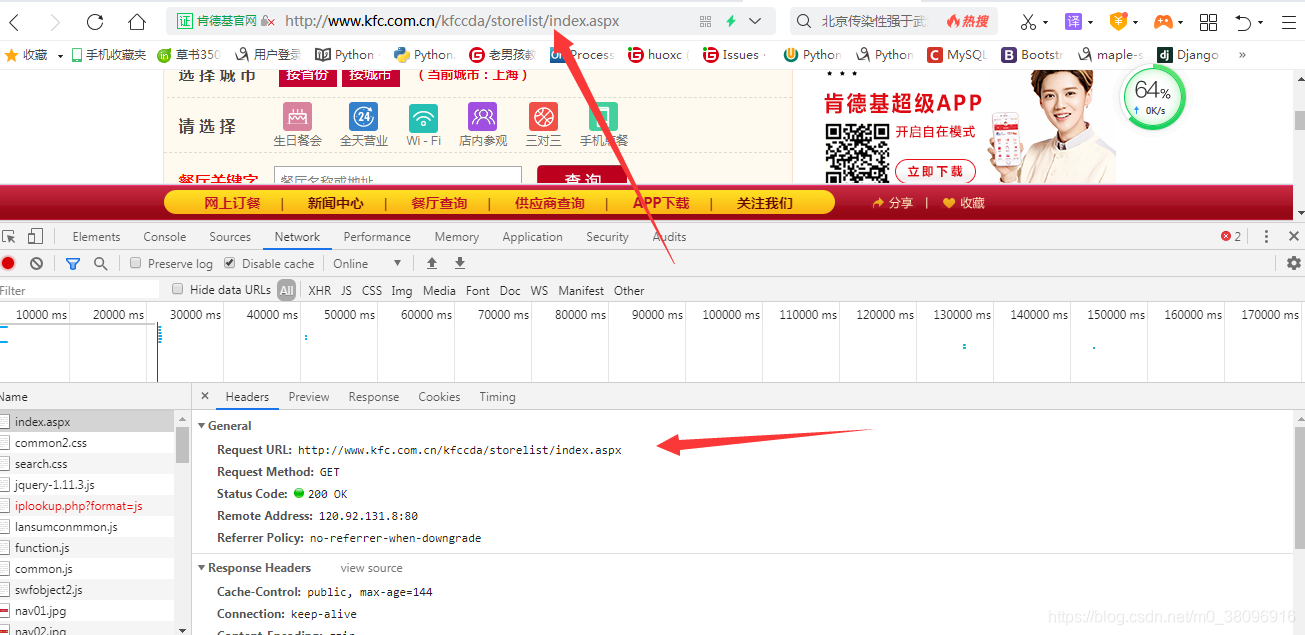
第二:找到与地址栏中相同的URL
第三步:来到response中,进行局部搜索,也可以点击preview,因为preview是可也做response的展示,如果在preview中没有数据则表明数据是动态加载的
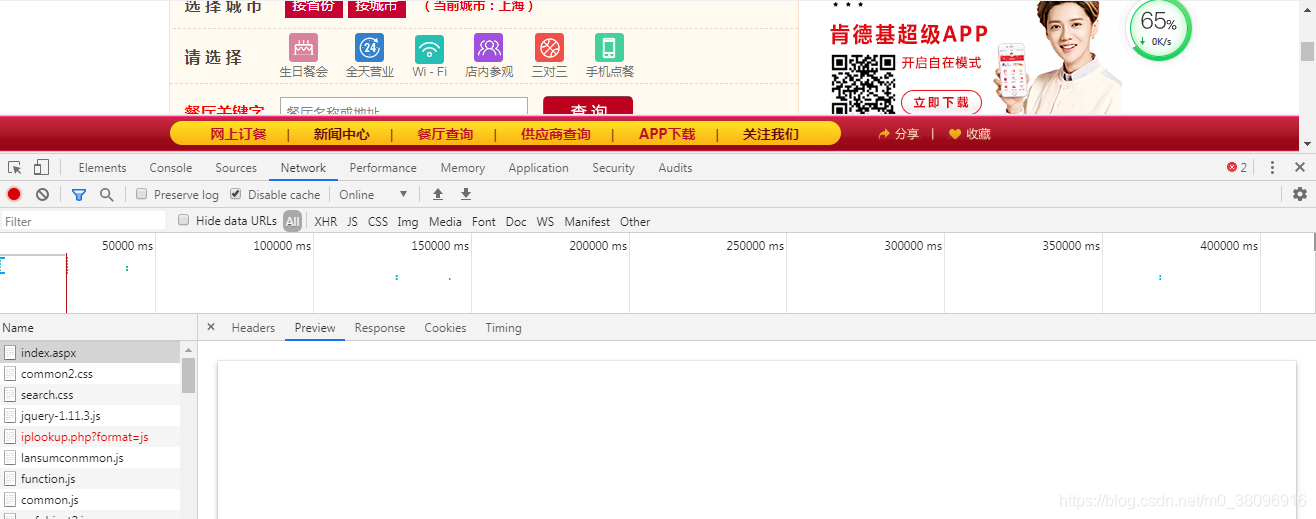
当输入北京时定位到XHR,就会发现,它发的是ajax请求
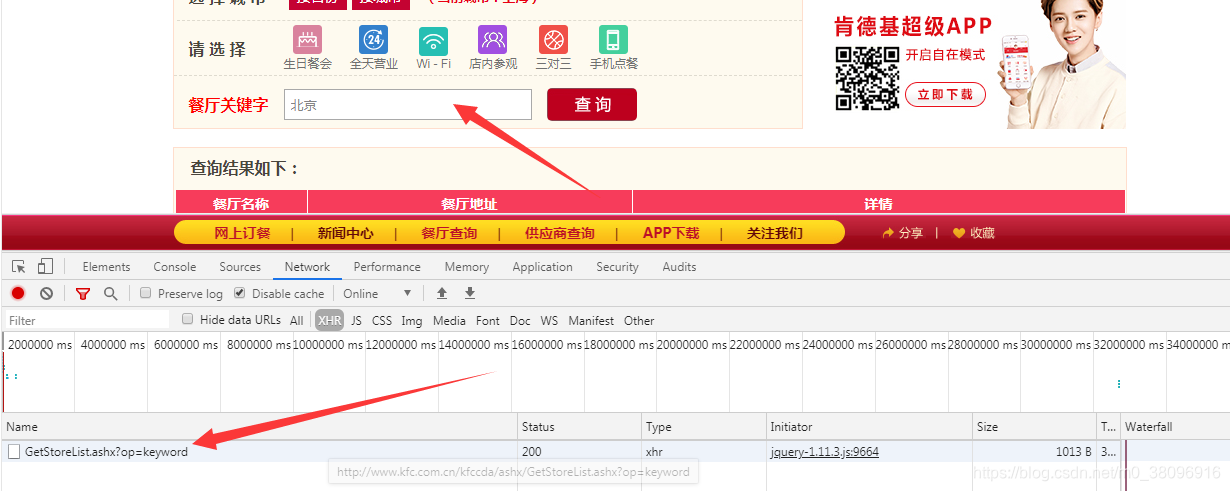
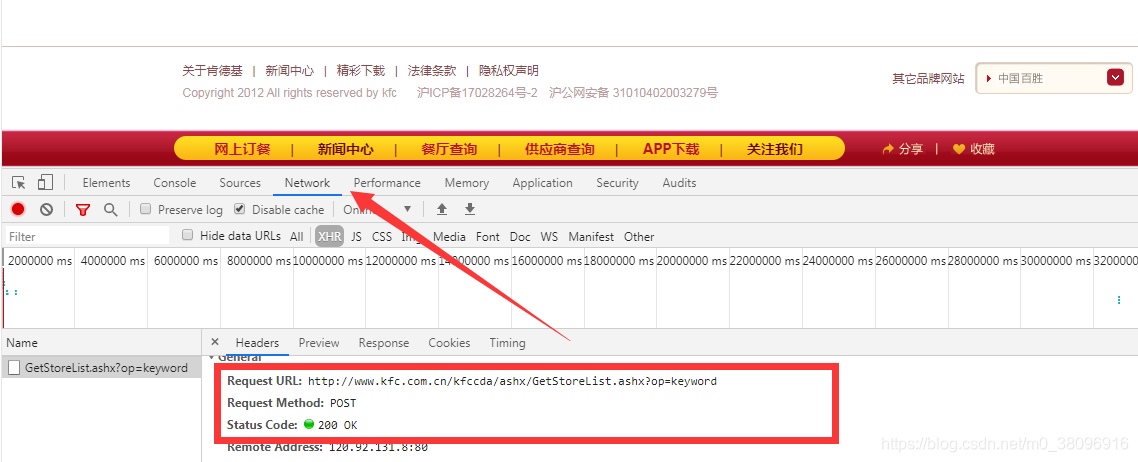
点击查看对应的请求的url,请求的方式,以及响应的数据,其中post会携带请求的参数,则需要做参数动态化
#1.以字符串的形式指定URL
url = ‘http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword‘
#参数动态化
data = {
‘cname‘:‘‘ ,
‘pid‘:‘‘ ,
‘keyword‘: ‘北京‘,
‘pageIndex‘: ‘1‘,
‘pageSize‘: ‘10‘,
}
#发送请求:在post请求中,参数动态化使用的是data
data_dict = requests.post(url=url,headers=headers,data=data).json()
print(data_dict)
其中拿到的是第一页的数据

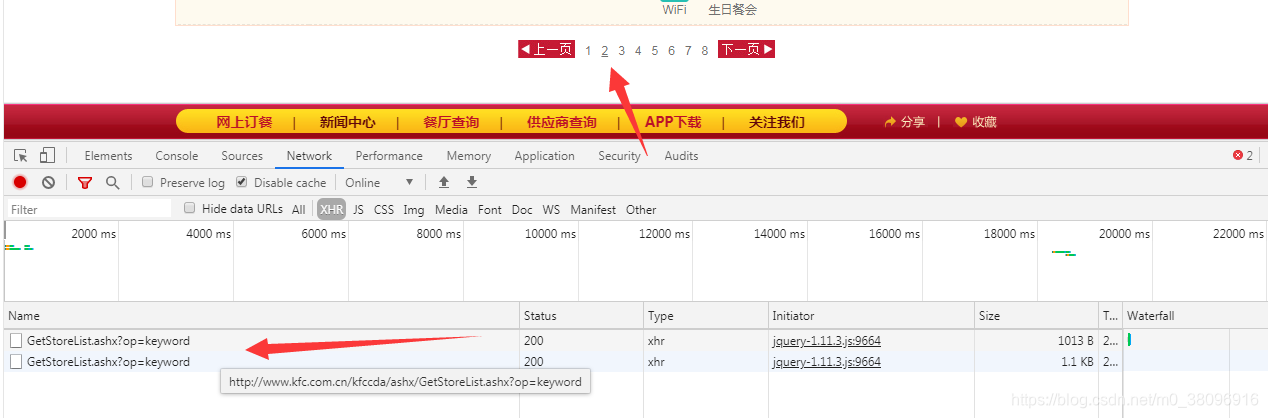
如果想要获取所有的数据怎么办,当点击第二页的数据,获取到了第二个ajax的请求,只有请求的参数不一样,其他都一样,写for循环就可以了

import requests
#1.以字符串的形式指定URL
url = ‘http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword‘
city = input(‘Enter you city:‘)
for page in range(5):
#参数动态化
data = {
‘cname‘: ‘‘ ,
‘pid‘: ‘‘ ,
‘keyword‘: ‘北京‘,
‘pageIndex‘: str(page),
‘pageSize‘: ‘10‘,
}
#发送请求:在post请求中,参数动态化使用的是data
data_dict = requests.post(url=url,headers=headers,data=data).json()
print(data_dict)
1:局部搜索检测是否是动态加载的;
2:如果是动态加载的,那么要全局搜索搜数据;搜数据的目的是为了能够定位到,咋们动态加载数据所对应的的数据包到底是哪一个,对数据包中的URL和请求参数做一个提取,就可以对其请求发送
标签:应对 刷新 抓包工具 发送 定位 RoCE 结果 url编码 har
原文地址:https://www.cnblogs.com/huoxc/p/13149723.html