标签:树结构 bsp 可变 collect rri copy linked 好的 lis
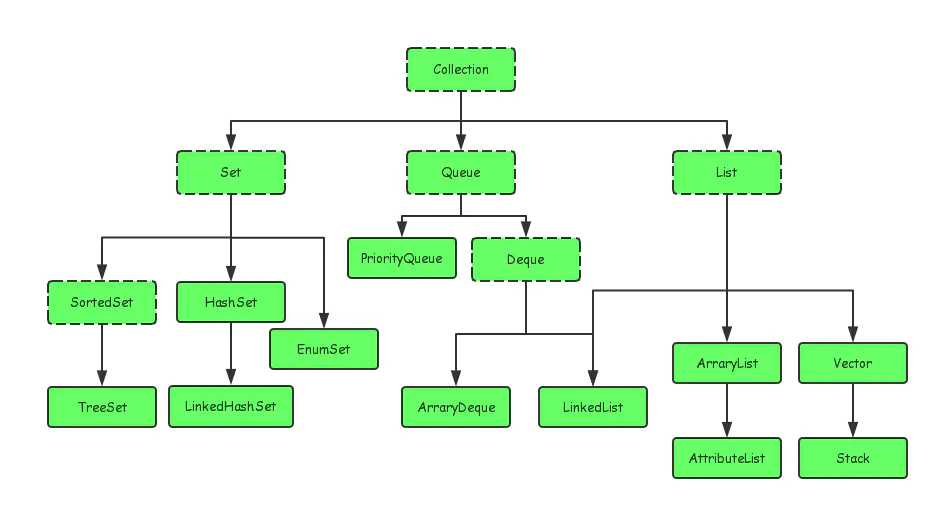
java集合大致可以分为List、Set、Map、Queue四种体系,其中Set代表无序、不可重复的集合;List代表有序的、可重复的集合;Map代表具有映射关系的集合;Queue是一种队列集合。
1.数组初始化的时候就指定了数组的长度,意味着只能保存定长的数据。而集合可以保存不定长的数据,而且集合还可以保存具有映射关系的数据。
2.数组元素即可以是基本类型的值,也可以是对象。集合里只能存对象,就算是基本类型,也会转成对应的包装类。
java的集合类主要由两个接口派生而出:Collection和Map。
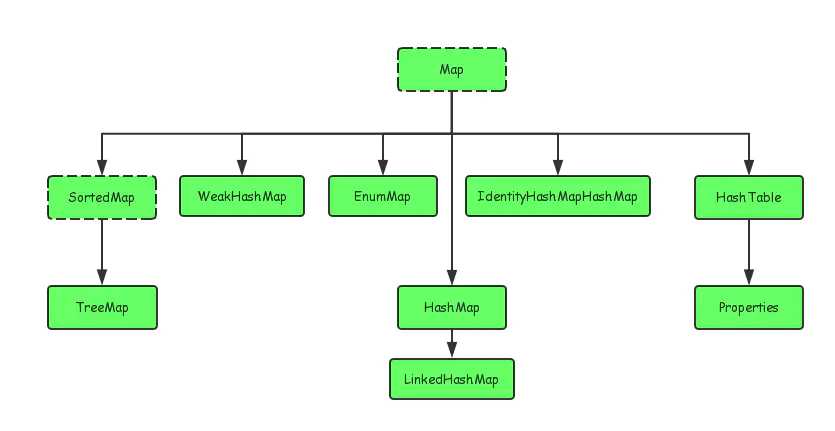
注:Map的结构图有一处错误,dentityHashMapHashMap应该是dentityHashMap。
Collection接口是Set、Queue、List的父接口。Collection接口中定义了多种方法可供其子类进行实现,以实现数据操作,如下:
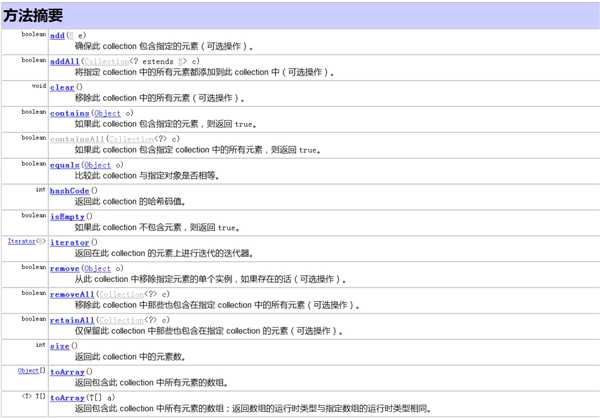
Iterator接口经常被称作迭代器,主要用于遍历集合中的元素。

Iterator的运用实例:
public static void main(String[] args) { List<Dog> arrayList = Arrays.asList(new Dog(1,1),new Dog(2,2)); Iterator<Dog> iterator = arrayList.iterator(); while(iterator.hasNext()){ Dog string = iterator.next(); string.setAge(3); System.out.println(string); } System.out.println(arrayList.toString()); }
输出:
Dog{age=3, age2=1}
Dog{age=3, age2=2}
[Dog{age=3, age2=1}, Dog{age=3, age2=2}]
这里可以注意到当我们修改iterator返回对象的属性时,集合中对象的属性也会随着改变,所以iterator遍历出来的对象,不是值传递,而是引用传递。但是如果集合中的对象是String的话则不会改变,这是因为String类是不可变的,所以会将引用指向另外的地址。
HashSet按Hash算法来存储集合中的元素,因此具有很好的存取和查找性能。
1.不能保证元素的排列顺序,顺序可能与添加顺序不同,顺序也有可能发生变化。
2.HashSet不是同步的,如果多个线程访问一个HashSet,则必须通过代码来保证其同步。
3.集合元素值可以是null。
equals()用来判断两个对象是否一个对象,比较的是两个对象的地址是否相等,而hashcode()是用来取哈希值的,哈希值是一个与地址有关但不相同的值,两个不同的对象有可能哈希值相同。
==
基本类型:比较的是值是否相同
引用类型:比较的是地址是否相同
equals
基本类型:基本类型根本就没有equals方法
引用类型:比较的是地址是否相同
equals方法默认是比较地址是否相同,但是你可以重写该方法,让对象之间进行值的比较。比如String类的equals方法就是被工程师们重写过的,对比的是String对象的值是否相同。所以一般在写代码的时候都建议用equals方法。
HashMap集合判断两个元素相等的标准:两个对象的equals方法相等,并且hashCode方法返回值也相等。
HashSet内部是一个HashMap,HashSet存对象会将该对象作为HashMap的key,然后拿一个默认对象作为value。所以HashSet判断是否存在该元素的原理和HashMap判断是否存在该key的原理是一样的。
假如Hashset中有10个内存位置(并不一定是连续的),我要讲Object1存进去,我会得到hashcode值经过算法的转换,算出存放的位置,比如位置3。那么我就去看位置3,如果该位置为空,那我就在该位置新建一个LinkList,将Object1存到表头;如果该位置3有LinkList了,那我就一个个遍历过去,调用equals比较地址,都不相同的情况下,在表尾插入。
LinkedHashSet是HashSet对的子类,也是根据元素的hashCode值来决定元素的存储位置,同时使用链表维护元素的次序,使得元素是以插入的顺序来保存的。当遍历LinkHashSet集合中的元素时,LinkHashSet将会按元素添加顺序来访问集合中的元素。但是由于要维护元素的插入顺序,在性能上略低于HashSet,但在访问迭代set里的全部元素时有很好的性能。
TreeSet是SortedSet接口的实现类,TreeSet可以确保元素处于排序状态。

自然排序:
存放在TreeSet里面的对象需要实现Comparable接口,TreeSet会调用集合中元素的compareTo(Object o)方法来比较元素之间的大小关系,然后将集合元素按升序排序。
TreeSet是根据红黑树结构找到集合元素的存储位置的。
定制排序
TreeSet的定制排序是通过Comparator接口的帮助。该接口包含一个int compare(T o1,T o2)方法,该方法用于比较o1,o2的大小;如果要实现定制排序,则需要在创建TreeSet时,调用一个带参构造器,传入Comparator对象。并有该对象负责集合元素的排序逻辑,集合元素可以不必实现Comparable接口。
public static void main(String[] args){ Person p1 = new Person(); p1.age =20; Person p2 =new Person(); p2.age = 30; Comparator<Person> comparator = new Comparator<Person>() { @Override public int compare(Person o1, Person o2) { //年龄越小的排在越后面 if(o1.age<o2.age){ return 1; }else if(o1.age>o2.age){ return -1; }else{ return 0; } } }; TreeSet<Person> set = new TreeSet<Person>(comparator); set.add(p1); set.add(p2); System.out.println(set); }
如果向TreeSet中添加一个可变对象后,并且后面程序修改了该可变对象的实例变量,这将导致它与其他对象的大小顺序发生了变化,但TreeSet不会再次调整它们。下面程序演示这一现象。
TreeSet<Person> set = new TreeSet<Person>(); Person p1 = new Person(); p1.setAge(10); Person p2 =new Person(); p2.setAge(30); Person p3 =new Person(); p3.setAge(40); set.add(p1); set.add(p2); set.add(p3); System.out.println("初始年龄排序"); System.out.println(set); //p1的年龄修改成50 最大 p1.age = 60; System.out.println("修改p1年龄后集合排序"); System.out.println(set); p2.age = 40; System.out.println("修改p2年龄后集合排序"); System.out.println(set); Person p4 = new Person();
初始年龄排序 [Person[age=10], Person[age=30], Person[age=40]] 修改p1年龄后集合排序 [Person[age=60], Person[age=30], Person[age=40]] 修改p2年龄后集合排序 [Person[age=60], Person[age=40], Person[age=40]]
所以不推荐修改放入TreeSet集合中元素的关键实例变量。
EnumSet是一个专为枚举类设计的集合类,EnumSet中所有元素都必须是指定枚举类型的枚举类值,该枚举类类型在创建EnumSet的时候就隐性指定了
Enum的一些特点:
①EnumSet的集合元素也是有序的,以枚举值在枚举类中的定义顺序来排序的。
②EnumSet不能存Null;
③EnumSet是非线程安全的。
④EnumSet类没有暴露任何构造器来创建该类的实例,程序应该通过它提供的static方法来创建EnumSet对象,常用的static方法比如:
enum Sesson{ SPRING,SUMMER,FALL,WINTER } public class Test { public static void main(String[] args) throws ParseException{ //创建一个EnumSet集合,集合元素就是所有Sesson中的枚举值 EnumSet es1=EnumSet.allOf(Sesson.class); System.out.println(es1); //[SPRING, SUMMER, FALL, WINTER] } }
四种Set的性能对比
EnumSet > HashSet > LinkedHashSet > TreeSet
EnumSet内部以位向量的形式存储,结构紧凑、高效,且只存储枚举类的枚举值,所以高效。HashSet次之,LinkedHashSet因为要维护链表,所以比HashSet更慢。TreeSet因为要排序所以最慢。
具体的应用场景:
当需要一个特定排序的集合时,使用TreeSet集合。
当需要保存枚举类的枚举值时,使用EnumSet集合。
当经常使用添加,查询操作时,使用HashSet。
当经常插入排序或使用删除、插入及遍历操作时,使用LinkedHashSet。
与Set不同,List还提供了一个listIterator()方法,该方法返回一个listIterator对象,可以用来前向遍历List,还可以通过add方法,添加元素
ArrayList和Vector都是基于数组实现的List类,所以ArrayList和Vector类封装了一个动态的、允许再分配的Obje[]数组,ArrayList和Vector都可以用initalCapacity参数来设置该数组的长度,当向ArrayList或Vector中添加元素超过该数组长度时,它们的initalCapacity长度会自动增加,完成扩容,如果不设置,默认为10。
当往ArrayList里面添加对象时,调用add方法,
public boolean add(E e) { ensureCapacityInternal(size + 1); // 数组的大小增加1 elementData[size++] = e; return true; }
在该方法中,先调用一个ensureCapacityInternal方法,顾名思义,该方法用来确保数组中是否还有足够的容量,如果不够,就执行grow方法。
private void grow(int minCapacity) { //......省略部分内容 主要是为了生成大小合适的newCapacity //下面这行就是进行了数组扩容 elementData = Arrays.copyOf(elementData, newCapacity); }
ArrayList和Vector有相似之处也有不同之处,他们最大的区别就是Vector是线程安全的,所以Vector也会比ArrayList要慢。
①使用迭代器Iterator遍历;②使用for循环遍历;③使用下标遍历。
因为ArrayList是内部是一个数组,所以第一种方法最慢,第三种方法最快。而LinkList是链表结构,所以和ArrayList相反。
LinkedList的实现机制与ArrayList完全不同。LinkedList内部以链表的形式来保存集中中的元素,因此随机访问集合元素时性能较差,但插入和删除性能比较出色。
LinkedList由于维护了一个表头表尾的Node对象的变量。可以进行后续的添加元素到链表中的操作,以及其他删除,插入等操作。也因此实现了双向队列的功能,既可向表头加入元素,也可以向表尾加入元素。
标签:树结构 bsp 可变 collect rri copy linked 好的 lis
原文地址:https://www.cnblogs.com/isgoto/p/13123489.html