标签:gen source use ISE lan 过多 mybatis bat ble
前面已经介绍过,水平分库是把同一个表的数据按一定规则拆到不同的数据库中,每个库可以放在不同的服务器上。接下来看一下如何使用Sharding-JDBC实现水平分库,咱们继续对快速入门中的例子进行完善。
(1)将原有order_db库拆分为order_db_1、order_db_2

(2)分片规则修改
由于数据库拆分了两个,这里需要配置两个数据源。
分库需要配置分库的策略,和分表策略的意义类似,通过分库策略实现数据操作针对分库的数据库进行操作。
spring.main.allow-bean-definition-overriding=true
mybatis.configuration.map-underscore-to-camel-case=true
#sharding-jdbc分片规则配置
#数据源
spring.shardingsphere.datasource.names=m1,m2
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/order_db_1?useUnicode=true
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=123456
spring.shardingsphere.datasource.m2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m2.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m2.url=jdbc:mysql://localhost:3306/order_db_2?useUnicode=true
spring.shardingsphere.datasource.m2.username=root
spring.shardingsphere.datasource.m2.password=123456
# 分库策略,以user_id为分片键,分片策略为user_id % 2 + 1,user_id为偶数操作m1数据源,否则操作m2。
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.algorithm-expression=m$->{user_id % 2 + 1}
# 指定t_order表的数据分布情况,配置数据节点 m1.t_order_1,m1.t_order_2
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=m1.t_order_$->{1..2}
# 指定t_order表的主键生成策略为SNOWFLAKE
spring.shardingsphere.sharding.tables.t_order.key-generator.column=order_id
spring.shardingsphere.sharding.tables.t_order.key-generator.type=SNOWFLAKE
# 指定t_order表的分片策略,分片策略包括分片键和分片算法
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order_$->{order_id % 2 + 1}
# 打开sql输出日志
spring.shardingsphere.props.sql.show=true
分库策略定义方式如下:
#分库策略,如何将一个逻辑表映射到多个数据源
spring.shardingsphere.sharding.tables.<逻辑表名称>.database‐strategy.<分片策略>.<分片策略属性名>= #分片策略属性值
#分表策略,如何将一个逻辑表映射为多个实际表
spring.shardingsphere.sharding.tables.<逻辑表名称>.table‐strategy.<分片策略>.<分片策略属性名>= #分片策略属性值
Sharding-JDBC支持以下几种分片策略:
不管理分库还是分表,策略基本一样。
目前例子中都使用inline分片策略,若对其他分片策略细节若感兴趣,请查阅官方文档:https://shardingsphere.apache.org
(3)插入测试
修改testInsertOrder方法,插入数据中包含不同的user_id
@Test public void testInsertOrder(){ for (int i = 0 ; i<10; i++){ orderDao.insertOrder(new BigDecimal((i+1)*5),1L,"WAIT_PAY"); } for (int i = 0 ; i<10; i++){ orderDao.insertOrder(new BigDecimal((i+1)*10),2L,"WAIT_PAY"); } }
执行testInsertOrder:
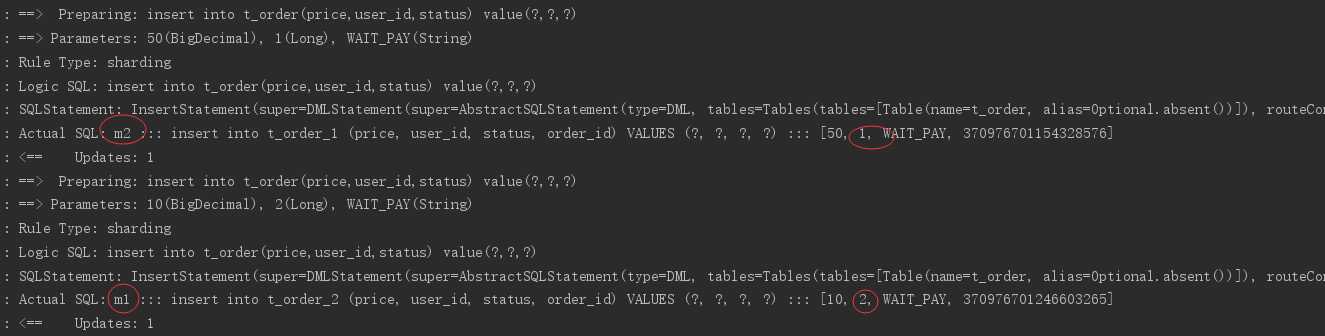
通过日志可以看出,根据user_id的奇偶不同,数据分别落在了不同数据源,达到目标。
(4)查询测试
调用快速入门的查询接口进行测试:
List<Map> selectOrderbyIds(@Param("orderIds")List<Long> orderIds);
通过日志发现,sharding-jdbc将sql路由到m1和m2:

问题分析:
由于查询语句中并没有使用分片键user_id,所以sharding-jdbc将广播路由到每个数据结点。
下边我们在sql中添加分片键进行查询。
在OrderDao中定义接口:
@Select({"<script>",
" select",
" * ",
" from t_order t ",
"where t.order_id in",
"<foreach collection=‘orderIds‘ item=‘id‘ open=‘(‘ separator=‘,‘ close=‘)‘>",
"#{id}",
"</foreach>",
" and t.user_id = #{userId} ",
"</script>"
})
List<Map> selectOrderbyUserAndIds(@Param("userId") Integer userId, @Param("orderIds")List<Long> orderIds);
编写测试方法
@Test public void testSelectOrderbyUserAndIds(){ List<Long> orderIds = new ArrayList<>(); orderIds.add(373422416644276224L); orderIds.add(373422415830581248L); //查询条件中包括分库的键user_id int user_id = 1; List<Map> orders = orderDao.selectOrderbyUserAndIds(user_id,orderIds); JSONArray jsonOrders = new JSONArray(orders); System.out.println(jsonOrders); }
执行testSelectOrderbyUserAndIds:

查询条件user_id为1,根据分片策略m$->{user_id % 2 + 1}计算得出m2,此sharding-jdbc将sql路由到m2,见上图日志。
标签:gen source use ISE lan 过多 mybatis bat ble
原文地址:https://www.cnblogs.com/jwen1994/p/13172091.html