标签:reset level 样式 nic nts https nump levels func
常见的图表有:饼状图,柱状图(可并列),折线图,散点图,直方图,叠加柱状图,三维散点图,三维曲面图,箱线图。
下面用seaborn库绘制以上各种类型的图表:
我们使用seaborn库中自带的数据库iris。如果没有,需要在https://github.com/mwaskom/seaborn-data上下载。
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
data = pd.read_csv(‘iris.csv‘)
dataname = data[‘species‘]
print(data.head())
print(‘------------------‘)
freq = dataname.value_counts(normalize = True) #也可以不归一化,在后面画图时候函数会自动归一化
print(freq)
print(‘------------------‘)
colors = [‘#81ecec‘,‘#ff7675‘,‘#6c5ce7‘]
plt.pie(freq, labels = freq.index, explode = (0.05, 0, 0), autopct = ‘%.1f%%‘, colors = colors, startangle = 90, counterclock = False)
plt.axis(‘square‘)
plt.legend(loc=‘upper right‘, bbox_to_anchor=(1.2, 0.2))
plt.show()
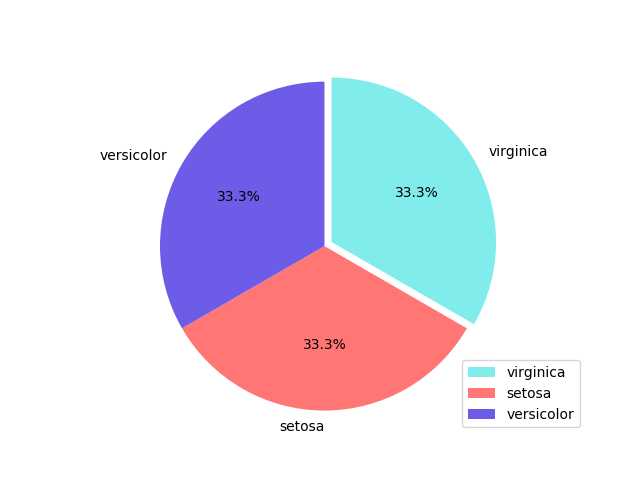
从图表可以看出来,每一类的数据分布是均匀的。
接下来我们看iris中每一个特征分布图,用柱状图表示。
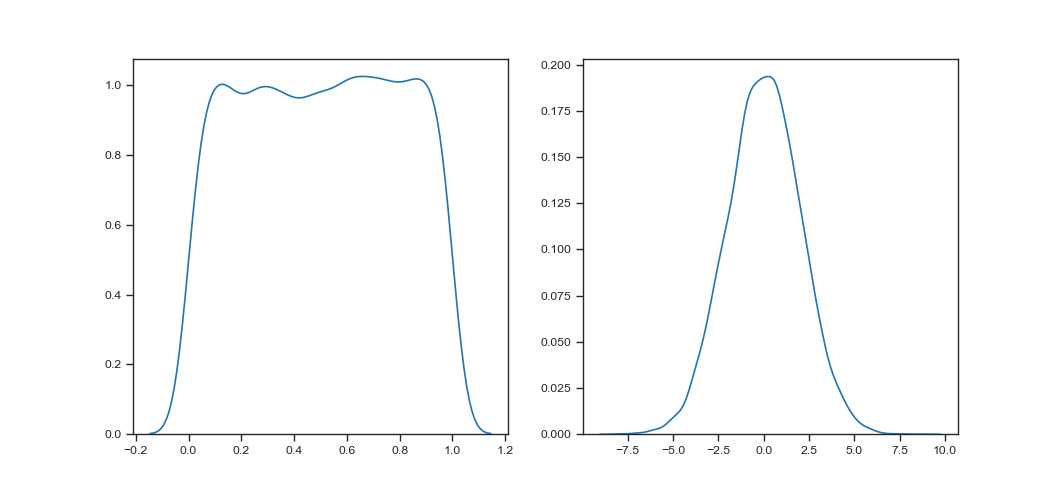
如何生成随机数据供我们学习,numpy可以生成各种分布的数据,下面用kdeplot()来绘图,绘出数据的近似分布密度函数图,如下:
代码:
sns.set_style(‘ticks‘) sns.set_context(‘paper‘) x = np.random.uniform(0,1,10000) #均匀分布 y = np.random.normal(0,2,10000) # y ~ N(0,4) 正态分布 scale = 标准差S f = plt.figure() f.add_subplot(1,2,1)
#plt.title(‘x‘) sns.kdeplot(x) f.add_subplot(1,2,2)
#plt.title(‘y‘) sns.kdeplot(y) plt.show()
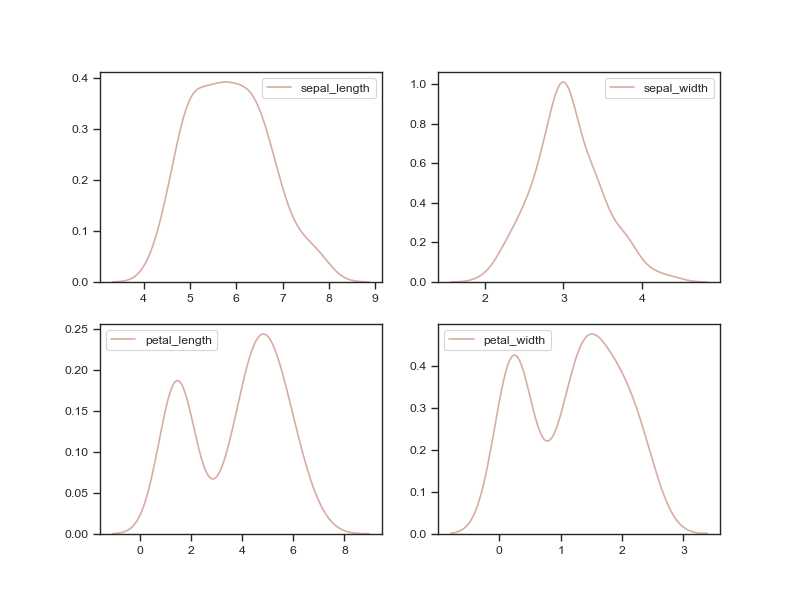
有了上面的练习,再来画出iris数据各个特征的分布核函数:
sns.set_style(‘ticks‘) sns.set_context(‘paper‘) f = plt.figure(figsize=(8,6)) with sns.cubehelix_palette(8, gamma = 2): #gamma<1 unclear;gamma>1 clear f.add_subplot(2,2,1) sns.kdeplot(data[‘sepal_length‘]) f.add_subplot(2,2,2) sns.kdeplot(data[‘sepal_width‘]) f.add_subplot(2,2,3) sns.kdeplot(data[‘petal_length‘]) f.add_subplot(2, 2, 4) sns.kdeplot(data[‘petal_width‘]) plt.show()
我们再看不同类别的相同特征有什么样的分布规律。
sns.set_context(‘paper‘)
f = plt.figure(figsize=(8,6))
labels = dataname.drop_duplicates(inplace=False)
labels = labels.reset_index(drop = True)
featurename = data.columns
print(featurename)
for i in range(3):
cls = data[dataname == labels[i]]
cls.columns = labels[i]+‘_‘+featurename
for j in range(4):
f.add_subplot(2,2,j+1)
plt.title(featurename[j])
sns.kdeplot(cls[labels[i]+‘_‘+featurename[j]])
plt.suptitle("kernel density estimations of the features of different irises")#中文显示问题我还没有解决,之后会出一随笔写有关plt中文显示的问题
plt.show()
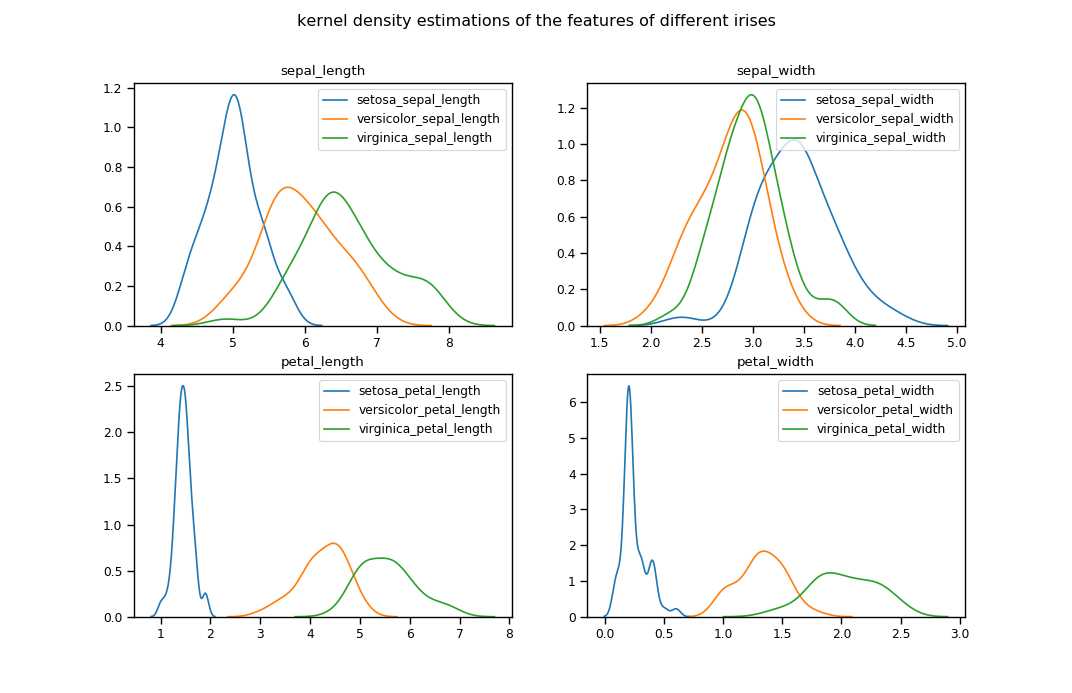
可以看出在petal_length和petal_width这两个特征的密度分布函数图中 setosa 和另外两种iris区分很开,所以依据petal_length或者petal_width就足够区分出是否为setosa了;
而另外两种iris 4个特征的密度分布函数均有重叠,需要后序做进一步区分。
前面单单从一个维度(petal_lenght或者petal_width)足够区分出一种花setosa, 对于另外两种花我们期待能在高的维度上区分它们,所以
我们可以作出更高维度的图看能否直观的区分出它们。
from scipy.stats import pearsonr,norm
sns.set_context(‘paper‘)
data1 = data[data[‘species‘]==‘versicolor‘]
data2 = data[data[‘species‘]==‘virginica‘]
sns.jointplot(x = ‘sepal_length‘, y = ‘sepal_width‘, data = data1,
marginal_kws=dict(bins = 20, kde = True, fit = norm, fit_kws = {‘color‘: ‘r‘},
rug = True),stat_func = pearsonr, linewidth = 1, space = 0, color = ‘b‘).set_axis_labels(‘versicolor_sepal_length‘,‘versicolor_sepal_width‘)
plt.suptitle(‘versicolor\‘s sepal feature‘)
ax = sns.jointplot(data2[‘sepal_length‘],data2[‘sepal_width‘],marginal_kws=dict(bins = 20, kde = True, fit = norm, fit_kws = {‘color‘: ‘r‘},
rug = True),stat_func = pearsonr, space = 0, color = ‘g‘,kind = ‘scatter‘) #kind = ‘scatter‘, ‘reg‘, ‘resid‘, ‘kde‘, ‘hex‘
ax.plot_joint(sns.kdeplot, zorder = 0, n_levels = 6)#在前面一个图的基础上在加上核密度估计的联合密度分布图,通过plot_joint()实现。
plt.suptitle(‘virginica\‘s sepal feature‘)
plt.show()
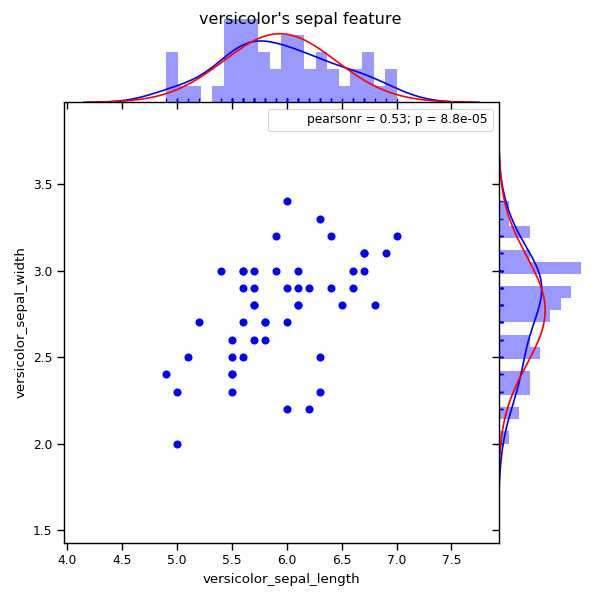
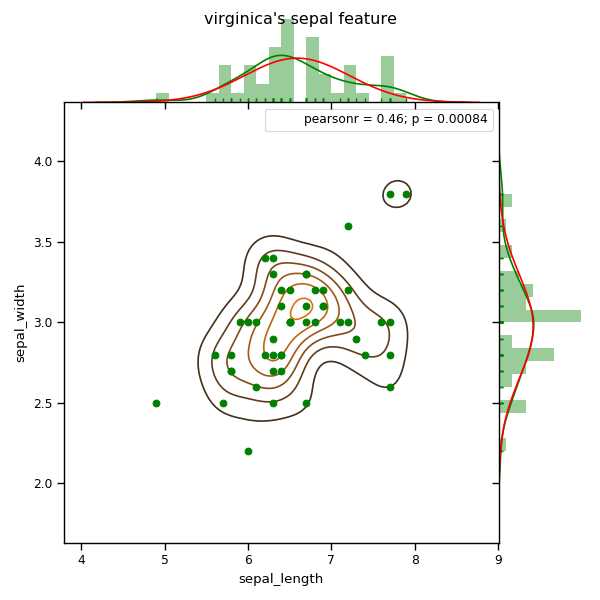
从这两个图我们可以看出sepal_length和sepal_width有正相关关系,由于仅仅由一个sepal_length或者sepal_width,我们是无法区别这两种花的,看了两种花的sepal_length or width 分布后我们可以知道仅仅由这两个数据我们依然无法区分sepal width, 左边图的中心在(6,2.5)左右,右边图的中心在(6.8,3)左右,两中心距离较近,且可以看出feature向量分布很散。
现在需要将两个图合并为一个图,这样我们可以更清楚的判断能否仅仅通过sepal数据来区分这两种iris。
我们需要用到pairplot()函数:
‘‘‘
seaborn.pairplot(data,hue = None,hue_order = None,palette = None,vars = None,x_vars = None,y_vars = None,kind =‘scatter’,
diag_kind =‘auto’,markers = None,s = 2.5,aspect = 1,dropna = True,plot_kws = None,diag_kws = None,grid_kws = None)
‘‘‘
sns.set_context(‘paper‘)
new_data = data[data[‘species‘]!=‘setosa‘]
print(new_data.head())
new_data.reset_index(drop = True, inplace = True)
print(new_data.head())
ax = sns.pairplot(new_data,
kind = ‘scatter‘, # 散点图/回归分布图 {‘scatter’, ‘reg’}
diag_kind="hist", # 设置对角线图直方图/密度图 {‘hist’, ‘kde’}
hue="species", # 按照某一字段进行分类
aspect = 1, #图形比例1:1
palette="husl", # 设置调色板
markers=[‘o‘,‘x‘], # 设置不同系列的点样式(这里根据参考分类个数)‘D‘,‘o‘,‘x‘,‘+‘...
size = 2, # 图表大小
plot_kws={‘size‘:2.5}, # 设置点大小
diag_kws={‘edgecolor‘:‘w‘}) # 设置对角线直方图样式
plt.show()
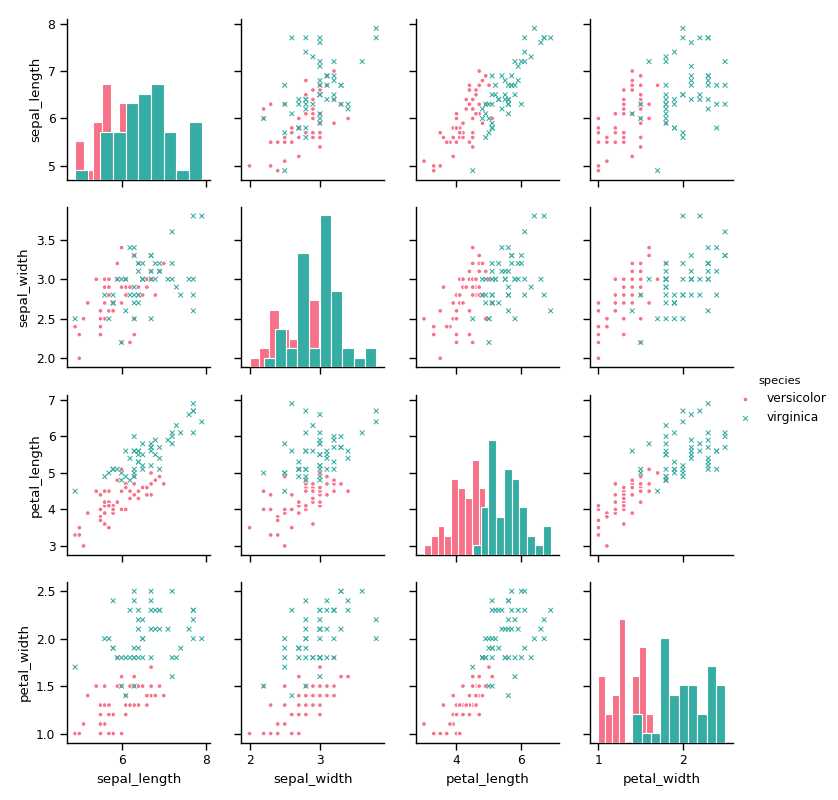
可以看出当数据投影到二维平面上时候我们可以近似用一条直线将两种iris花给区分开,
由(1,4),(2,4),(3,4)我们可以清晰的看见可以画出一条分界线区分两种花,
这说明了petal_width是区分这两种花的关键。
sns.set_style(‘white‘,{‘font.sans-serif‘:[‘simhei‘,‘Arial‘]})
sns.set_context(‘paper‘)
new_data = data[data[‘species‘]!=‘setosa‘]
print(new_data.head())
new_data.reset_index(drop = True, inplace = True)
print(new_data.head())
sns.pairplot(new_data, kind = ‘reg‘, hue = ‘species‘, markers = [‘o‘,‘x‘],
diag_kind=‘kde‘,palette =‘husl‘, diag_kws=dict(shade = True, color = ‘g‘), height = 2)
plt.suptitle(‘对每一类两个变量进行回归分析图表‘)
plt.show()
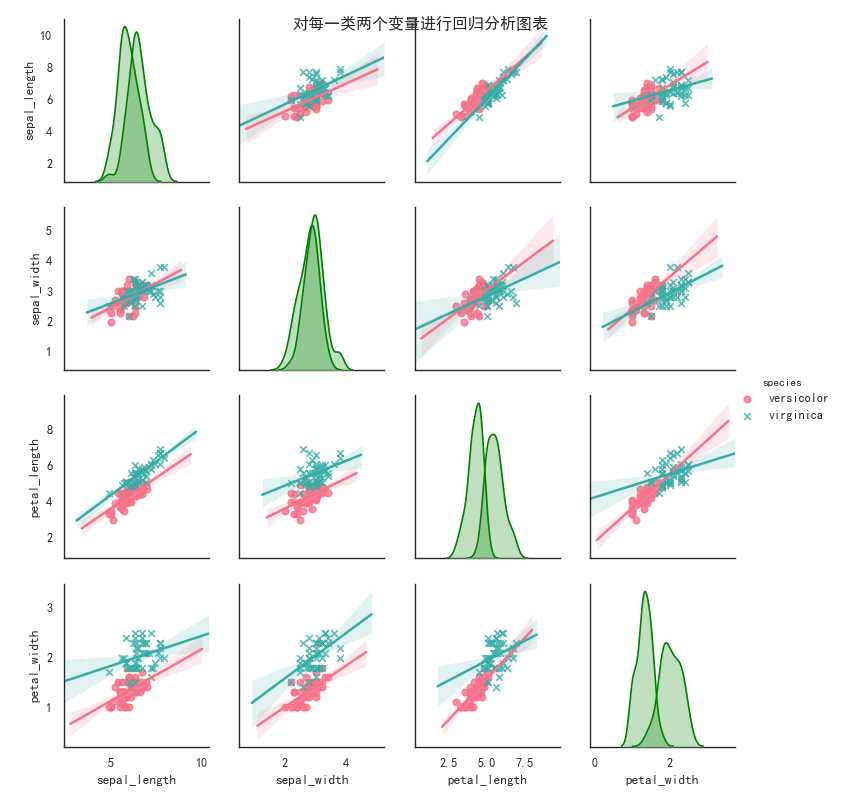
前面添加一句话 sns.set_style(‘white‘,{‘font.sans-serif‘:[‘simhei‘,‘Arial‘]})就可以显示中文啦!
从图表可以看出来不同种类的iris花各个特征之间的影响程度不同,petal_length对petal_width,不同种类影响也不同,
例如versicolor的petal_length对pental_width影响很大。
明天继续更新seaborn库对后面的图表绘画的方法。
标签:reset level 样式 nic nts https nump levels func
原文地址:https://www.cnblogs.com/raiuny/p/13172340.html