标签:sea 计算机科学 none mic 简写 regex 计算 pre group
一。正则表达式初识
1.定义:
又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。
2.使用
1)导入re模块
import re
常用正则表达式的表示方法:
单个字符匹配:

数量匹配:

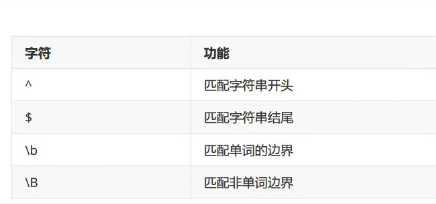
边界匹配:
2)运用:
正则表达式前需要加r,如:r“a\A”
1.匹配
my_re = "xiangwangshiheyuanfang"
#match,从最开始的地方进行匹配,若没有返回None
print(re.match(r"wang",my_re))
#search,不区分前后,任意匹配
print(re.search(r"wang",my_re))
运行结果:
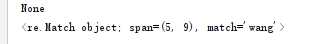
3)获得匹配结果:
#group(),获取匹配的内容
re_result=re.search(r"wang",my_re)
print(re_result.group())
#re.findall 返回所有的匹配结果。
print(re.findall(r"g",my_re))
运行结果:
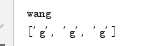
3.常用匹配方式:
1.单个字符匹配
1)‘.’
#匹配一个字符,除了\n
print(re.search(r".",my_re))
#匹配a后面的一个字符
print(re.search(r"a.",my_re))
运行结果:
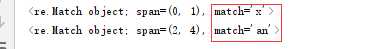
注意:
1.匹配是从左边第一个开始的。
2.‘.’前面加上字符后,会返回字符+字符后面的字符,‘.’后面加字符也是同理
2)‘[]’
#匹配[]中的某一个字符
print(re.search(r‘[agw]‘,my_re))
运行结果:
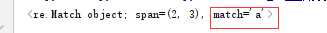
3)\d、\D
my_remath="xiangwangshiheyuanfang521@"
#\d 匹配一个数字
print(re.search(r"\d",my_remath))
#\D匹配一个非数字
print(re.search(r"\D",my_remath))
运行结果:

注意:
#[0-9]与\d等价
print(re.search(r"[0-9]",my_remath))
运行结果:
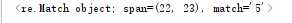
4)\w与\W
my_remath="_xiangwangshiheyuanfang521@"
#匹配 大写小字母和_
print(re.search(r"\w",my_remath))
#匹配非单词字符
print(re.search(r"\W",my_remath))
运行结果:
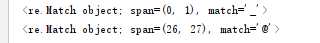
2.匹配 数量
1)*
#匹配*前面的字符任意次,有可能没有
print(re.search(r"\D*",my_remath))
第运行结果:
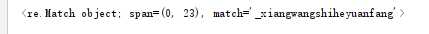
2)+、?
#+极可能多的匹配,?只匹配一次
print(re.search(r"\d+",my_remath))
print(re.search(r"\d+?",my_remath))
运行结果:
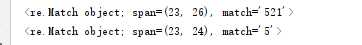
3){m}
my_remath="_xiaaangwangshiheyuanfang521@"
#匹配a出现过几次,从结果中可以看出只对连在一起的值匹配有效果
print(re.search(r"a{1,}",my_remath))
#不连在一起的值
print(re.search(r"g",my_remath))
运行结果:
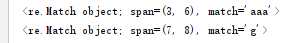
4.利用添加类属性动态替换测试用例中的固定值
待续ing
标签:sea 计算机科学 none mic 简写 regex 计算 pre group
原文地址:https://www.cnblogs.com/newsss/p/13174595.html