标签:终端 domain 不可 class 结构性 电视 lin image 支持
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍。所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性的项目模板。
Linux安装:
pip install scrapy
Windows安装:
a. pip install wheel
b. 下载twisted:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
#根据Python解释器版本选择对应的版本下载
c. 进入下载目录,执行 pip install Twisted?17.1.0?cp35?cp35m?win_amd64.whl
- twisted:帮助scrapy实现异步的一个工具。
- 该步骤如果出错,可以尝试下载安装其他版本的twisted文件
d. pip install pywin32
e. pip install scrapy
1、创建一个工程项目:scrapy startproject ProName
? spiders: 爬虫文件夹。需要在内部创建一个爬虫文件
? settings:配置文件
2、进入工程项目:cd ProName
3、创建爬虫文件:scrapy genspider spiderName(爬虫名) www.xx.com(爬取域)
4、执行工程项目:scrapy crawl spiderName
5、列出所有爬虫:scrapy list
6、获得配置信息:scrapy settings [options]
目录结构
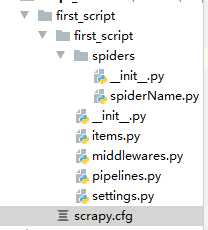
scrapy.cfg: 项目的配置文件
first_script/: 该项目的python模块。之后您将在此加入代码。
first_script/items.py:需要提取的数据结构定义文件。
first_script/middlewares.py: 是和Scrapy的请求/响应处理相关联的框架。
first_script/pipelines.py: 用来对items里面提取的数据做进一步处理,如保存等。
first_script/settings.py: 项目的配置文件。
first_script/spiders/: 放置spider代码的目录。
ROBOTSTXT_OBEY = False #不遵循rebots反爬机制
LOG_LEVEL = ‘ERROR‘
USER_AGENT = ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36‘
spiderName.py
爬取当前页作者+段子
# -*- coding: utf-8 -*-
import scrapy
class SpidernameSpider(scrapy.Spider):# 继承Spider类
name = ‘spiderName‘#爬虫文件名称 爬虫的唯一标识,不能重复,启动爬虫的时候要用
# allowed_domains = [‘www.xx.com‘] # 限定域名,只爬取该域名下的网页
start_urls = [‘https://www.qiushibaike.com/text/‘]
# 开始爬取的URL列表,可存放多个url作为列表元素,列表中存放的url会被自动进行get请求的发送
def parse(self, response):
‘‘‘
#用作于接收响应对象,进行数据解析。参数response就是接收到的响应对象
#parse方法调用的次数取决月start_urls列表元素的个数
:param response:
:return:
‘‘‘
# 数据解析:解析出段子的作者和内容
print(response)
div_list = response.xpath(‘//*[@id="content"]/div/div[2]/div‘)
for div in div_list:
# scrapy实现数据解析,取文本或者取属性返回的不在是字符串,而是一个Selector对象
# 且发现我们想要的数据都存在了Selector对象的data参数中
# 调用一个方法:extract()提取Selector对象data中的值
# author = div.xpath(‘./div[1]/a[2]/h2/text()‘)[0].extract()
author = div.xpath(‘./div[1]/a[2]/h2/text()‘).extract_first()
# 列表直接调用extract()方法表示extract方法可以作用到每一个列表元素中
content = div.xpath(‘./a/div/span//text()‘).extract()
content = ‘‘.join(content)
print(author,content)
终端运行:scrapy crawl spiderName
结果:
小青春呀
别喷我 喝多了才办的糗事[笑哭][笑哭] 昨天晚上 和我朋友喝酒 喝到12点的时候 旁边桌来了六个人
五个男的一个女的 根据我的观察 那五个男的和那个女的 都没有什么关系 不是情侣什么的 我就鼓起
勇气 在加上喝点酒 跑过去问那女的要微信去了 结果微信没有要到 那五个男的突然站起来 唉 先不说了
医院网络不好 [捂脸][捂脸][捂脸]
。。。。。。
正版煮茶
我在客厅吃东西,坐我对面的我妈叫我:你坐在空调吹风口干嘛,不得感冒了,快过我这边来坐!我心一暖,还是我
妈关心我。我刚挪到她那边,我妈:对,这样坐就对了,刚刚电视全给你一个人挡了。
# -*- coding: utf-8 -*-
import scrapy
class SpidernameSpider(scrapy.Spider):# 继承Spider类
name = ‘spiderName‘#爬虫文件名称 爬虫的唯一标识,不能重复,启动爬虫的时候要用
# allowed_domains = [‘www.xx.com‘] # 限定域名,只爬取该域名下的网页
start_urls = [‘https://www.qiushibaike.com/text/‘]
# 开始爬取的URL列表,可存放多个url作为列表元素,列表中存放的url会被自动进行get请求的发送
def parse(self, response):
‘‘‘
#用作于接收响应对象,进行数据解析。参数response就是接收到的响应对象
#parse方法调用的次数取决月start_urls列表元素的个数
:param response:
:return:
‘‘‘
# 数据解析:解析出段子的作者和内容
div_list = response.xpath(‘//*[@id="content"]/div/div[2]/div‘)
all_data = []
for div in div_list:
# scrapy实现数据解析,取文本或者取属性返回的不在是字符串,而是一个Selector对象
# 且发现我们想要的数据都存在了Selector对象的data参数中
# 调用一个方法:extract()提取Selector对象data中的值
# author = div.xpath(‘./div[1]/a[2]/h2/text()‘)[0].extract()
author = div.xpath(‘./div[1]/a[2]/h2/text()‘).extract_first()
# 列表直接调用extract()方法表示extract方法可以作用到每一个列表元素中
content = div.xpath(‘./a/div/span//text()‘).extract()
content = ‘‘.join(content)
print(author,content)
dic = {
‘author‘:author,
‘content‘:content,
}
all_data.append(dic)
# 将解析到的数据存储封装到了all_data列表中,然后将其作为了parse的返回值
return all_data
终端运行指令:scrapy crawl spiderName -o ./qiushibaike.csv
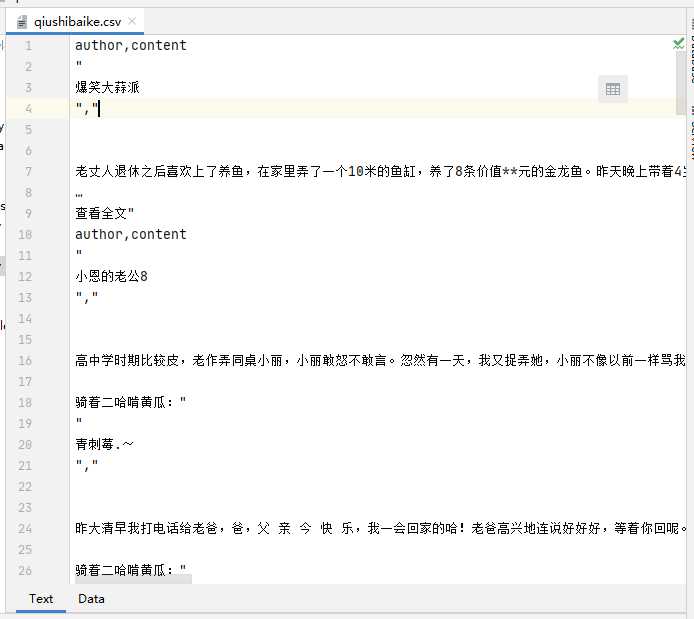
注意:只可以将parse方法的返回值写入到本地文件,不可以存储到数据库。
import scrapy
class SpidernameSpider(scrapy.Spider):# 继承Spider类
name = ‘spiderName‘#爬虫文件名称 爬虫的唯一标识,不能重复,启动爬虫的时候要用
# allowed_domains = [‘www.xx.com‘] # 限定域名,只爬取该域名下的网页
start_urls = [‘https://www.qiushibaike.com/text/‘]
# 开始爬取的URL列表,可存放多个url作为列表元素,列表中存放的url会被自动进行get请求的发送
def parse(self, response):
‘‘‘
#用作于接收响应对象,进行数据解析。参数response就是接收到的响应对象
#parse方法调用的次数取决月start_urls列表元素的个数
:param response:
:return:
‘‘‘
# 数据解析:解析出段子的作者和内容
div_list = response.xpath(‘//*[@id="content"]/div/div[2]/div‘)
all_data = []
for div in div_list:
# scrapy实现数据解析,取文本或者取属性返回的不在是字符串,而是一个Selector对象
# 且发现我们想要的数据都存在了Selector对象的data参数中
# 调用一个方法:extract()提取Selector对象data中的值
# author = div.xpath(‘./div[1]/a[2]/h2/text()‘)[0].extract()
author = div.xpath(‘./div[1]/a[2]/h2/text()‘).extract_first()
# 列表直接调用extract()方法表示extract方法可以作用到每一个列表元素中
content = div.xpath(‘./a/div/span//text()‘).extract()
spiderName.py
import scrapy
from first_script.items import FirstScriptItem
class SpidernameSpider(scrapy.Spider):# 继承Spider类
name = ‘spiderName‘#爬虫文件名称 爬虫的唯一标识,不能重复,启动爬虫的时候要用
# allowed_domains = [‘www.xx.com‘] # 限定域名,只爬取该域名下的网页
start_urls = [‘https://www.qiushibaike.com/text/‘]
# 开始爬取的URL列表,可存放多个url作为列表元素,列表中存放的url会被自动进行get请求的发送
def parse(self, response):
‘‘‘
#用作于接收响应对象,进行数据解析。参数response就是接收到的响应对象
#parse方法调用的次数取决月start_urls列表元素的个数
:param response:
:return:
‘‘‘
# 数据解析:解析出段子的作者和内容
div_list = response.xpath(‘//*[@id="content"]/div/div[2]/div‘)
all_data = []
for div in div_list:
# scrapy实现数据解析,取文本或者取属性返回的不在是字符串,而是一个Selector对象
# 且发现我们想要的数据都存在了Selector对象的data参数中
# 调用一个方法:extract()提取Selector对象data中的值
# author = div.xpath(‘./div[1]/a[2]/h2/text()‘)[0].extract()
author = div.xpath(‘./div[1]/a[2]/h2/text()‘).extract_first()
# 列表直接调用extract()方法表示extract方法可以作用到每一个列表元素中
content = div.xpath(‘./a/div/span//text()‘).extract()
content = ‘‘.join(content)
#Item对象的实例化
item = FirstScriptItem()
item[‘author‘] = author
item[‘content‘] = content
items.py
import scrapy
class FirstScriptItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
author = scrapy.Field()
content = scrapy.Field()
import scrapy
from first_script.items import FirstScriptItem
class SpidernameSpider(scrapy.Spider):# 继承Spider类
name = ‘spiderName‘#爬虫文件名称 爬虫的唯一标识,不能重复,启动爬虫的时候要用
# allowed_domains = [‘www.xx.com‘] # 限定域名,只爬取该域名下的网页
start_urls = [‘https://www.qiushibaike.com/text/‘]
# 开始爬取的URL列表,可存放多个url作为列表元素,列表中存放的url会被自动进行get请求的发送
def parse(self, response):
‘‘‘
#用作于接收响应对象,进行数据解析。参数response就是接收到的响应对象
#parse方法调用的次数取决月start_urls列表元素的个数
:param response:
:return:
‘‘‘
# 数据解析:解析出段子的作者和内容
div_list = response.xpath(‘//*[@id="content"]/div/div[2]/div‘)
all_data = []
for div in div_list:
# scrapy实现数据解析,取文本或者取属性返回的不在是字符串,而是一个Selector对象
# 且发现我们想要的数据都存在了Selector对象的data参数中
# 调用一个方法:extract()提取Selector对象data中的值
# author = div.xpath(‘./div[1]/a[2]/h2/text()‘)[0].extract()
author = div.xpath(‘./div[1]/a[2]/h2/text()‘).extract_first()
# 列表直接调用extract()方法表示extract方法可以作用到每一个列表元素中
content = div.xpath(‘./a/div/span//text()‘).extract()
content = ‘‘.join(content)
#Item对象的实例化
item = FirstScriptItem()
item[‘author‘] = author
item[‘content‘] = content
yield item #将item提交个管道
pipelines.py
class FirstScriptPipeline:
#是用来接收item对象的,每次调用只可以接收一个item类型对象
#参数item就是接受到的item对象
def process_item(self, item, spider):
author = item[‘author‘]
content = item[‘content‘]
print(‘管道:‘,author+‘:‘+content+‘\n‘)
return item
ITEM_PIPELINES = {
‘first_script.pipelines.FirstScriptPipeline‘: 300,
}
终端运行命令:scrapy crawl spiderName
执行结果图

标签:终端 domain 不可 class 结构性 电视 lin image 支持
原文地址:https://www.cnblogs.com/remixnameless/p/13179850.html